
Обеспечение тщательного запрограммированного подкрепления правильных ответов когда обучение
Обновлено: 07.07.2024
Метод обучения с подкреплением – это самостоятельное и уже вполне сформировавшееся направление кибернетических исследований. Обучение с подкреплением используется в различных областях науки: нейронных сетях, психологии, искусственном интеллекте, управлении, исследовании операций и т. д. Главное достоинство этого метода – его сравнительная простота, но не реализация: наблюдаются действия обучаемого объекта и в зависимости от результата поощряют, либо наказывают данный объект, не объясняя обучаемому объекту, как именно нужно действовать. Роль учителя может играть внешняя среда. В данном методе большое внимание уделяется поощрению/наказанию не только текущих действий, которые непосредственно привели к положительному/отрицательному результату, но и тех действий, которые предшествовали текущим. Основные принципы обучения с подкреплением:
· обучение через взаимодействие;
· обучение через взаимодействие с окружающей средой.
Функция оценки – показывает, что есть хорошо в продолжительный период, тогда как функция подкрепления показывает, что есть хорошо в текущий момент. Оценка состояния это итоговое подкрепление агента, которое предположительно может быть накоплено при последующих стартах из этого состояния. В то время как подкрепление определяет прямую, характерную желательность состояния окружения, оценки показывают долгосрочную желательность состояний после принятия во внимания состояний, которые последуют за текущим, и подкреплений, соответствующих этим состояниям. Например, состояние может повлечь низкое непосредственное подкрепление, но иметь высокую оценку, потому как за ним регулярно следуют другие состояние, которые приносят высокие подкрепления.
Функция подкрепления - определяет цель в процессе обучения с подкреплением. Это соответствие между воспринимаемыми состояниями среды и числом, подкреплением, показывающим присущую желательность состояния. Единственная цель агента состоит в максимизации итогового подкрепления, которое тот получает в процессе длительной работы. Функция отражает и определяет существо проблемы управления для агента. Она может быть использована как базис для изменения правил. Например, если выбранное действие повлекло за собой низкое подкрепление, правила могут быть изменены для того, чтобы в следующий раз выбрать другое действие. В общем случае, функция подкрепления может быть стохастической.
Агент и среда взаимодействуют на каждом из последовательности дискретных временных шагов, t = 0, 1, 2, 3, … . На каждом временном шаге, t, агент получает некоторое представление о состоянии среды, , где S это множество всех возможных состояний. На основе состояния агент выбирает действие, , где это множество действий, возможных в состоянии . Во время следующего шага, как часть ответа на действие, агент получает числовое подкрепление, , и переводит себя в состояние .
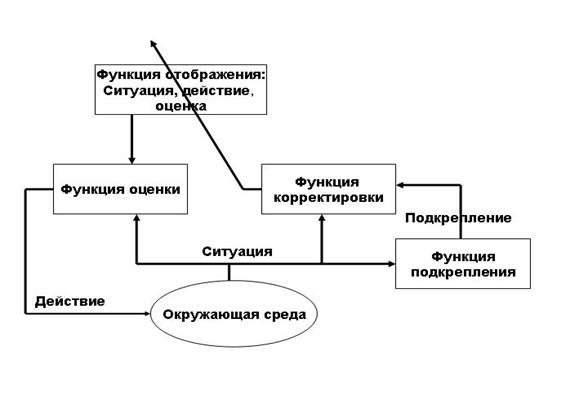
Рисунок. Принцип работы систем использующих обучение с подкреплением
На каждом временном шаге, агент осуществляет отображение состояний на вероятности выбора каждого действия. Такое отображение называется правилами агента и обозначается , где вероятность, что , если . Методы обучения с подкреплением указывают, как агент изменяет свои правила в результате получения нового опыта. Цель агента максимизировать итоговую сумму подкрепления, полученную в течение долговременной работы.
Последовательность полученных сигналов подкреплений после шага t обозначается как . В обучении максимизируется ожидаемый результат, где результат, , определен как некоторая специфическая функция последовательности подкреплений. В простейшем случаем результат есть простая сумма подкреплений:
где T заключительный шаг.
Существуют две основные стратегии для реализации обучения с подкреплением с использованием нейронных сетей – -обучение и сети адаптивной критики.
Сети адаптивной критики
Сети адаптивной критики применяются в ситуации, когда окружающая среда является зашумленной, нелинейной и нестационарной. Такие топологии служат основой многих адаптивных систем управления. В основе сетей адаптивной критики лежит принцип оптимальности Беллмана [1] .
Различают следующие основные виды сетей адаптивной критики:
- ЭДП (эвристическое динамическое программирование) - критик оценивает значение J ( t ), также этот алгоритм известен под названием SARSA ;
- ДЭП (Двойственное эвристическое программирование) - критик оценивает значения производной J(t).
Также разработано большое количество других реализаций, но в их основе лежит либо ЭДП, либо ДЭП, либо комбинация ЭДП и ДЭП. Но первым и самым простым является алгоритм SARSA .
Сеть адаптивной критики обучается аппроксимации стратегической функции. При обучении, функция выигрыша J должна быть известна, однако из-за разнообразия технических задач, иногда приходится использовать этот метод без ее знания, но при этом необходимо учитывать к чему должна стремиться в конечном счете система.
Использование принципа динамического программирования в данном случае предполагает применение двух отдельных циклов: цикл обучения агента и цикл обучения критика. В случае агента, в цикле нейросеть учится аппроксимировать оптимальный сигнал управления. Критик тренируется оптимизировать функцию J ( t ). После, выход агента - управляющий сигнал u ( t ), на основе градиентного алгоритма обучения используется для оценки производной при обучении критика. Рассмотрим основные виды сетей адаптивной критики:
Алгоритм SARSA . В данном алгоритме множество возможных ситуаций и действий является конечным. Каждый шаг обучения соответсвует цепочке:
Обучение происходит в режиме реального времени. В процессе обучения итеративно происходит оценка суммарной величины награды, которую получит агент, если в ситуации выполнит действие . Матожидание награды равно:
Ошибка оценки равна [134]:
В каждый такт времени происходит как выбор действия, так и обучение агента. Выбор действия происходит следующим образом – в момент времени t с вероятностью выбирается действие с максимальном значением . .
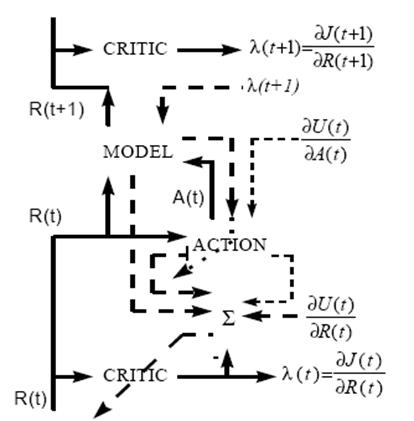
Рисунок - Схема работы ДЭП
Алгоритм Двойственного Эвристического Программирования (далее ДЭП) (Рисунок 1.6). В алгоритме ДЭП сеть критики используется для вычисления производной по отношению к вектору . Сеть критики обучается минимизировать следующее соотношение:
где - вектор содержащий частные производные скаляра в отношении к компонентам вектора . В алгоритме ДЭП обучение сети критики происходит дольше, чем в алгоритме ЭДП, т. к. должны учитываться все значимые направления в обратном распространении. Веса сети критики корректируются по формуле:
где - скорость обучения.
Алгоритм Объединенного Двойственного Эвристического Программирования (далее ОДЭП). В ОДЭП минимизируется ошибка в отношении обеих и их производных. Несмотря на сложность реализации и значительные временные затраты, этот алгоритм дает наилучшее результаты при планировании поведения объекта. Существуют около десятка подвидов данного алгоритма [6], кратко рассмотрим основные моменты основополжного, предложенного Вербосом ( Werbos ). При обучении сети критики в ОДЭП используется мера погрешности, которая является комбинацией мер погрешности в ЭДП и ДЭП (1.6 и 1.8), то есть в данном случае они скрещиваются. Результатом является следующее правило изменения весов сети критики:
Решение задачи брокера
Пусть мы имеем следующее:
- есть агент, который обладает некоторым количеством ресурсов двух типов: депозитом в банке и акциями (для простоты одного типа). Сумма этих ресурсов составляет общий капитал брокера . Процент акций в общем капитале обозначим как ;
- внешняя среда определяется временным рядом , характеризующим курс акции в момент времени ;
- агент стремится увеличить свой капитал с течением времени;
- система управления агента содержит блок Модель, которая прогнозирует изменение курса акции на одну временную итерацию вперед;
- система управления агента содержит блок Критик, который оценивает качество ситуации . Ситуация задается вектором > , ;
- система управления содержит - жадное правило, которое используется для выбора одного из возможных двух действий:
а) - перевести весь капитал в деньги;
б) - перевести все деньги в капитал.
Блок Модель предназначена для прогнозирования изменения курса акции и для этого вполне подходит обычный многослойный персептрон и метод обучения обратного распространения ошибки.
Блок Критик предназначен для оценки суммарной награды . Блок Критика также представляет собой многослойный персептрон (в данном случае входной – скрытый – выходной слои).
На Критика дважды подается вектор , при этом спрогнозирован блоком Модель, а подается сначала 1, затем 0 (порядок не имеет значения). Критик обучается с помощью временной разницы:
где и - оценка суммарной награды для ситуаций и . Таким образом, в течении времени накапливается история правильности принятия решений , на основе ошибки .
Выбор действия после выдачи блоком Критика результата происходит на основе - жадного правила. При этом выбирается с вероятностью максимальное из выданных Критиком . .
[1] “Оптимальная стратегия обладает следующим свойством, каким бы не было начальное состояние управления, последующие управления должны определять оптимальную стратегию относительно состояния полученного в результате 1-го решения” [ 7 ].
Общая схема алгоритма обучения с подкреплением
1.1. Агент взаимодействует со средой посредством выбора и выполнения поведения.
1.2. Состояние агента переходит в следующее состояние после выполнения действия.
1.3. Среда будет давать соответствующие награды и наказания в зависимости от действий агента.
1.4. В соответствии с вознаграждениями и наказаниями, которые дает среда, агент постоянно учится адаптироваться к среде методом проб и ошибок.
Элементы алгоритма обучения с подкреплением
2.1.Агент: Программа, которая выполняет разумное принятие решений, цель, которую мы, наконец, достигаем в процессе обучения.Это ученик во всей системе, который можно вообразить в младенчестве, постоянно обучающийся и растущий в постоянном контакте с окружающей средой.
2.2.Функция стратегии: Стратегия определяет поведение агента в окружающей среде. Тип действий агента в окружающей среде зависит от стратегии. ----- Это можно понимать как проблему обучения ребенка и размышления о проблеме в процессе контакта с окружающей средой. Разные способы мышления повлияют на разное поведение ребенка, а также сформируют его разные личности.
2.3.Функция значения: Функция ценности указывает степень активности агента в определенном состоянии. Это связано со стратегией. ----- Это можно понимать как оценку поведения взрослого по отношению к ребенку, когда поведение ребенка хорошее. Дайте ребенку награду, дайте ему конфету или что-нибудь еще. Когда ребенок плохо себя ведет, он игнорирует ребенка или шлепает его.
2.4.модель: Модель - это агентное представление среды. Обучение делится на два типа: обучение на основе моделей и обучение без моделей. Обучение на основе моделей - это использование ранее полученного опыта для обучения в процессе обучения. Обучение происходит путем постоянных проб и ошибок .----- Как будто у некоторых детей нет памяти, у некоторых детей память хорошая, и одни и те же ошибки можно выучить только один или два раза, но дети, у которых нет памяти Будет повторять ту же ошибку, но, в конце концов, ребенок не совершит эту ошибку, и вероятность ее совершения будет меньше из-за урока ошибки.
Платформа обучения с подкреплением
3.1.OpenAI Gym и Вселенная
OpenAI Gym - это набор инструментов для построения, оценки и сравнения обучения с подкреплением. Совместим с Tensorflow, Theano, Keras.
OpenAI Universe - это расширение OpenAI Gym, которое предоставляет функции для обучения и оценки агентов в различных средах, от простых до сложных в реальном времени. Неограниченный доступ ко многим играм.
3.2.DeepMind Lab
Платформа обучения с подкреплением, предоставленная командой DeepMind
3.3.RL_Glue
3.4.Project Malmo
3.5.VIzDoom
Привет! Вы впервые используетеРедактор Markdown Отображается страница приветствия. Если вы хотите узнать, как использовать редактор Markdown, вы можете внимательно прочитать эту статью, чтобы узнать об основном синтаксисе Markdown.
Поскольку OpenAI Gym и Universe в настоящее время поддерживают только системы Linux и Mac, все следующие среды устанавливаются под Ubuntu 18.04. Установка системы Mac аналогична. Пользователи системы Windows могут установить системы Linux или Mac на виртуальную машину для установки.
Установка анаконды
Команды, связанные с операциями Conda
Установить Docker
Введение в докер
Docker - это контейнерный движок приложений с открытым исходным кодом, который позволяет разработчикам упаковывать свои приложения и зависимости в переносимый контейнер, а затем публиковать его на любой популярной машине Linux, которая также может быть виртуализирована. Контейнеры полностью используют механизм песочницы, и между ними не будет интерфейсов
Официальный учебник английского языка DockerПроще говоря, Docker похож на github. Только github предназначен для размещения кода, а Docker - для размещения нашей среды разработки. Мы можем загрузить нашу среду разработки вDocker HubКогда мы меняем компьютеры или развертываем на сервере, мы можем напрямую извлекать нашу развернутую среду или среду других, публично развертывающих пакеты в Docker Hub, что позволяет избежать проблем, связанных с нашей повторяющейся средой конфигурации. И мы устанавливаем Docker - это потому, что Universe необходимо развернуть в DockerРуководство Doker на китайском языке
Установка Docker
- Базовая установка DOcker
- Конфигурация докера
Как видите, все мы выполняем команды Docker от имени пользователя root. Чтобы позволить нам запускать Docker каждый раз, когда нам не нужно использовать корневую идентификацию, а только нашу обычную идентификацию пользователя, мы можем сделать это:
Установка OpenAI Gym
Решение
- Установите физический движок MuJoCo
- Сменить спортзалsetup.py Конфигурация
gedit ~/gym/setup.py
Закомментируйте пары "ключ-значение" ниже Затем переустановите тренажерный зал
- Error:command ‘gcc’ failed with exit status 1:
Вселенная инсталляция
Установить из исходного кода юниверса

юниверс установлен успешно
Тестовый тренажерный зал и Вселенная

2.Тестовый код два

При выполнении этого кода контейнер будет загружен из концентратора Docker, поэтому он будет очень медленным.
Результат:
2. Изучите принципы обучения, пользуясь различными источниками. Охарактеризуйте пять любых принципов, заполняя таблицу.
Принцип воспитывающего обучения
Процесс обучения и воспитания неразрывно связаны, в процессе обучения формируется также и базовая культура личности
Процесс учебной деятельности и применение полученных знаний и навыков является четко структурированной системой
Процесс обучение строится с учетом реальных возможностей обучаемого
- непосредственно определяет содержание учебных материалов;
- необходимо вовлечение учащегося в непосредственный научный процесс, дискуссии и поиск дополнительной информации
- реализация гуманистического подхода в образовании;
- обучение должно быть направлено на всестороннее развитие учащегося;
- высокий уровень эрудиции и профессионализма учителя с целью создания его рефферентного образа у учеников;
- опора на сильные стороны обучаемого и ненавязчивое выделение и развитие слабых
- преподавание и усвоение знаний в определенном порядке
- для каждой педагогической ситуации должна применяться наиболее рациональная система и последовательность;
- необходимо вычленение в изучаемом материале ведущих категорий и понятий и установление их связей с другими категориями и понятиями
- процесс обучения строится на основе перехода от простого материала, доступного для усвоения учеником на данном этапе развития к более сложному;
- нельзя допускать эмоциональных и интеллектуальных перегрузок обучаемого
- процесс обучения, оставаясь доступным, должен вызывать интеллектуальные, нравственные и физические усилия
- использование в процессе обучения наглядных пособий, демонстрационных материалов, примеров из жизни
В. Прочности результатов обучения.
А. Воспитывающего обучения.
Б. Систематичности и последовательности.
А. Прочности результатов обучения.
Б. Связи обучения с жизнью.
В. Рационального сочетания коллективных и индивидуальных форм работы.
Ответ А
6. Докажите, пользуясь конкретными примерами, что принципы обучения основываются на его закономерностях.
Принципы обучения не могут противоречить или не соответствовать законам обучения, поэтому основаны на данных закономерностях. Например, на законе целостности и единства учебного процесса основан принцип систематизации обучения и принцип научности: обучение должно составлять единую систему и взаимодействовать е ее рамках с отраслями науки; закон взаимообусловленности обучения, воспитания и деятельности учащихся связан с принципом воспитывающего обучения: процесс обучения неразрывно связан с усвоением учащимся норм социального поведения, которые согласно вышеизложенному закону должны соответствовать конкретному общественному строю, времени и пр.
Взаимосвязанные способы деятельности учителя и учащихся, направленные на решение задач обучения;
Способ взаимосвязанной деятельности учащихся, обеспечивающий усвоение содержания образования;
Систематически применяемый способ работы учителя с учащимися, позволяющий учащимся развивать умственные способности и интересы;
Упорядоченная и систематическая деятельность педагога, направленная на достижение заданной цели обучения;
Часть теории обучения.
Понятие
9. Сопоставьте различные подходы к классификации методов обучения (Е.Я.Голант, М.Н.Скаткин, И.Я.Лернер, Ю.К.Бабанский, М.И.Махмутов, М.А.Данилов, Б.П.Есипов и др.) и дайте их краткую характеристику. Заполните таблицу:
Словесные (рассказ, беседа, лекция);
Наглядные(демонстрация – наглядно-чувственное ознакомление учащихся с явлениями и процессами. Иллюстрация – показ и восприятие предметов, процессов и явлений);
Практические: (упражнение, лабораторная работа, практическая работа).
- по степени самостоятельности решений:
Репродуктивные– воспроизведение действий по применению знаний на практике.
Проблемно-поисковые – проблемное изложение изучаемого материала
- по логике передачи и восприятия информации:
Создание ситуации занимательности.
Создание ситуации успеха, реализация воспитательного потенциала ситуаций неуспеха, эмоциональных переживаний.
- Методы симулирования долга и ответственности.
Формирование убеждений в социальной и личностной значимости учения.
Упражнения в выполнении требований.
Фронтальный опрос (требует серии логически связанных м/у собой вопросов по небольшому объему материала)
- методы письменного контроля и самоконтроля:
Контрольные письменные работы.
Программные письменные работы (на каждый вопрос предполагает 4 варианта ответа, один из них верный)
Письменный самоконтроль (учащиеся сами проверяют свои работы, находят ошибки, стимулируют)
- методы лабораторно-практического контроля и самоконтроля
Контрольно-лабораторные работы (проведение опытов, выполнение практических заданий с использованием ранее полученных знаний).
Машинный контроль – различные виды программированного контроля
- эвристические или поисковые (эвристическая беседа, дискуссия, лабораторные работы);
10. Может ли метод обучения выступать в роли средства обучения и наоборот? Ответ обоснуйте.
Не может, так как метод обучения это более широкое понятие, включающее в себя процесс передачи знаний с помощью средств обучения. Метод это комплекс мер для организации обучения: например, выбор места для обучения, времени, стиля изложения материала и используемых пособий. Средство же обучения это материальный предмет, используемый для помощи в передачи и усвоении информации
Понятие
12. Проанализируйте различные формы обучения и заполните таблицу.
Форма обучения
13. Найдите соответствие между закономерностями и принципами воспитания. Заполните таблицу.
Принцип согласованности педагогического руководства деятельностью и развития инициативы и самостоятельности воспитанников;
Принцип ориентированности педагогической деятельности на формирование в единстве сознания и опыта деятельности;
14. Что такое самовоспитание?
Самовоспитание - осознанное, управляемое самой личностью развитие, в котором в интересах общества и самой личности планомерно формируются качества, свойства, силы и способности человека
15. Сравните эти высказывания.
А) В результате немецкого воспитания получается всегда немец, из французского – француз, из английского – англичанин, и только из русского сплошь и рядом выходит не русский, а часто если не космополит по убеждениям, то человек совсем равнодушный и безучастный к своей стране и народности (Царевский А.А. Значение русской словесности в национальном русском образовании. – Казань, 1893. – С. 42).
Б) Русские школы переделывают структуру русской души на манер иностранный, учат патриотизму на примере римских патриотов, чести – на образах французского рыцарства, семейной домовитости – на рассказах о германцах и швейцарцах (Розанов В.В. Сумерки просвещения. – М., 2001. – С. 56).
Проанализируйте обозначенные подходы к национальному своеобразию воспитания личности. Выскажите ваше мнение по этому поводу. Оформите
Обучение с подкреплением, идея которого была почерпнута в смежной области психологии, является подразделом машинного обучения, изучающим, как агент должен действовать в окружении, чтобы максимизировать некоторый долговременный выигрыш. Алгоритмы с частичным обучением пытаются найти стратегию, приписывающую состояниям окружающей среды действия, которые должен предпринять агент в этих состояниях. В экономике и теории игр обучение с подкреплением рассматривается в качестве интерпретации того, как может установиться равновесие.
Окружение обычно формулируется как марковский процесс принятия решений (МППР) с конечным множеством состояний, и в этом смысле алгоритмы обучения с подкреплением тесно связаны с динамическим программированием. Вероятности выигрышей и перехода состояний в МППР обычно являются величинами случайными, но стационарными в рамках задачи.
При обучении с подкреплением, в отличии от обучения с учителем,не предоставляются верные пары „входные данные-ответ“, а принятие субоптимальнх решений (дающих локальный экстремум) не ограничивается явно. Обучение с подкреплением пытается найти компромисс между исследованием неизученных областей и применением имеющихся знаний. Баланс изучения-применения при обучении с подкреплением исследовался в задаче многорукого бандита.
Формально простейшая модель обучения с подкреплением состоит из:
- множества состояний окружения S;
- множества действий A;
- множества вещественнозначных скалярных „выигрышей“.
В произвольный момент времени t агент характеризуется состоянием и множеством возможных действий . Выбирая действие , он переходит в состояние и получает выигрыш . Основываясь на таком взаимодействии с окружающей средой, агент, обучающийся с подкреплением, должен выработать стратегию , которая максимизирует величину в случае МППР, имеющего терминальное состояние, или величину
для МППР без терминальных состояний (где —- дисконтирующий множитель для „предстоящего выигрыша“).
Таким образом, обучение с подкреплением особенно хорошо подходит для решения задач, связанных с выбором между долгосрочной и краткосрочной выгодой. Оно успешно применялось в различных областях, таких как робототехника, управление лифтами, телекоммуникации,шашки и нарды (Sutton 1998, Глава 11).
Алгоритмы
Теперь, когда была определена функция выигрыша, нужно определить алгоритм, который будет использоваться для нахождения стратегии, обеспечивающей наилучший результат.
Наивный подход к решению этой задачи подразумевает следующие шаги:
- опробовать все возможные стратегии;
- выбрать стратегию с наибольшим ожидаемым выигрышем.
Первая проблема такого подхода заключается в том, что количество доступных стратегий может быть очень велико или же бесконечно. Вторая проблема возникает, если выигрыши стохастические — чтобы точно оценить выигрыш от каждой стратегии потребуется многократно применить каждую из них. Этих проблем можно избежать, если допустить некоторую структуризацию и, возможно, позволить результатам, полученным от пробы одной стратегии, влиять на оценку для другой. Двумя основными подходами для реализации этих идей являются оценка функций полезности и прямая оптимизация стратегий.
Подход с использованием функции полезности использует множество оценок ожидаемого выигрыша только для одной стратегии (либо текущей, либо оптимальной). При этом пытаются оценить либо ожидаемый выигрыш, начиная с состояния s, при дальнейшем следовании стратегии ,
либо ожидаемый выигрыш, при принятии решения a в состоянии s и дальнейшем соблюдении ,
Если для выбора оптимальной стратегии используется функция полезности Q, то оптимальные действия всегда можно выбрать как действия, максимизирующие полезность. Если же мы пользуемся функцией V, необходимо либо иметь модель окружения в виде вероятностей P(s'|s,a), что позволяет построить функцию полезности вида
либо применить т.н. метод исполнитель-критик, в котором модель делится на две части: критик, оценивающий полезность состояния V, и исполнитель, выбирающий подходящее действие в каждом состоянии.
Имея фиксированную стратегию , оценить при можно просто усреднив непосредственные выигрыши. Наиболее очевидный способ оценки при — усреднить суммарный выигрыш после каждого состояния. Однако для этого требуется, чтобы МППР достиг терминального состояния (завершился).
Поэтому построение искомой оценки при неочевидно. Однако, можно заметить, что R образуют рекурсивное уравнение Беллмана:
Подставляя имеющиеся оценки, V, и применяя метод градиентного спуска с квадратичной функцией ошибок, мы приходим к алгоритму обучения с временными воздействиями. В простейшем случае и состояния, и действия дискретны и можно придерживаться табличных оценок для каждого состояния. Другие похожие методы: Адаптивный эвристический критик (Adaptive Heuristic Critic, AHC), SARSA и Q-обучение (Q-learning). Все вышеупомянутые используют различные методы приближения, но в некоторых случаях сходимость не гарантируется. Для уточнения оценок используется метод градиентного спуска или метод наименьших квадратов в случае линейных приближений.
Указанные методы не только сходятся к корректной оценке для фиксированной стратегии, но и могут быть использованы для нахождения оптимальной стратегии Для этого в большинстве случаев принимают стратегию с максимальной оценкой, принимая иногда случайные шаги для исследования пространства. При выполнении некоторых дополнительных условий существуют доказательства сходимости упомянутых методов к оптимальной стратегии. Однако, эти доказательства гарантируют только асимптотическую сходимость, в то время как поведение алгоритмов обучения с подкреплением в задачах с малыми выборками мало изучено, не считая некоторых очень ограниченных случаев.
Альтернативный метод поиска оптимальной стратегии — искать непосредственно в пространстве стратегий. Таки методы определяют стратегию как параметрическую функцию с параметром . Для настройки параметров применяются градиентные методы. Однако, применение градиентных методов осложняется тем, что отсутствует информация о градиенте. Более того, градиент тоже приходится оценивать через зашумлённые результаты выигрышей. Так как это существенно увеличивает вычислительные затраты, может быть выгоднее использовать более мощные градиентные методы, такие как метод скорейшего спуска. Алгоритмы, работающие напрямую с пространством стратегий привлекли значительное внимание в последние 5 лет и в данный момент достигли достаточно зрелой стадии, но до сих пор остаются активным полем для исследований. Существуют и другие подходы, такие как метод отжига, применяемые для исследования пространства стратегий.
Современные исследования
В настоящее время ведутся исследования по Альтернативным представлениям (таких как Представление предсказывающих состояний), градиентный спуск в пространстве стратегий, сходимость для задач с малыми выборками, модулярное и иерархическое обучение с подкреплениями. В последнее время обучение с подкреплением использовалось в психологии для изучения процессов человеческого обучения и деятельности. В частности, исследовались когнитивные модели, симулирующие человеческое поведение в процессе решения задач и/или обретения навыков (Sun, Merril, & Peterson, 2001; Sun, Slusarz, & Terry, 2005; Gray, Sims, Fu, & Schoelles, 2006; Fu & Anderson, 2006). Обучение с подкреплением использовалось, чтобы предложить модель человеческой системы обработки ошибок. Многоагентное или распределённое обучение с подкреплением являются одним из направлений исследований в этой области.
Идея оперантного научения принадлежит бихевиористу Берресу Фредерику Скиннеру, поэтому часто этот метод обучения называют методом Скиннера.
Оперантное обучение строится на системе поощрений и наказаний, при помощи которых можно усилить или прекратить какой-то тип поведения. Поощрение называется позитивным подкреплением, а наказание, соответственно, негативным подкреплением.
Как вы уже поняли, танцевать цыплёнка научили исключительно за счёт позитивного подкрепления.
Дрессировка - любимый способ обучения. Люди дрессируют собак, лошадей и дельфинов, кошки вполне успешно дрессируют хозяев, жёны - мужей, родители - детей, многие люди дрессируют сами себя и так далее. Правда, у кого-то это получается более успешно, а у кого-то менее.

Родители постоянно дрессируют детей, давая им невербальную (а иногда и вербальную) обратную связь. Точно так же друг друга дрессируют муж с женой, друзья, коллеги, тренер группу, а группа тренера. По большей части процесс дрессировки проходит совершенно вне сознательного внимания. И может получиться совсем не то, что хотелось бы.
Ребёнок приходит со двора радостный и грязный, мать выражает недовольство. Бессознательное ребёнка связывает радость и негативную реакцию матери и через некоторое время домой он радостным не возвращается. Это негативное подкрепление.
Другой ребёнок заболевает, вокруг него суетятся родители, заботятся и бессознательное понимает - если болеешь, ты будешь получать внимание и одобрение. Это позитивное подкрепление.
Но подкрепление можно использовать и для полезного обучения. Учитывая, что получение навыков идёт через подкрепление. Вы учитесь играть в дартс: кидаете в цель стрелку - если попадает ближе к центру, то чувствуете позитивную эмоцию, стрелка уходит в молоко - негативную. Постепенно вы начинаете играть всё лучше и лучше - всё больше ваших стрелок попадает центр и всё меньше - в молоко.
Оперантное обучение не задаёт жёсткого паттерна поведения - у вас появляется склонность делать более эффективные вещи. Но остаётся некий разброс, который даёт гибкость. Это отличается от якорей, которые чётко вызывают заданную реакцию.
Правила оперантного обучения
Преимущественно используйте позитивное подкрепление
Негативное подкрепление без позитивного практически не работает. По крайней мере, если вы чему-то хотите научиться.
Маленький эксперимент, имени Ходжи Насреддина. Который, когда к нему привели на улучшение внешности ростовщика, заставил его и его родственников молиться и НЕ ДУМАТЬ о белой обезьяне. Они не смогли. Посмотрим, сможете ли вы. Представьте себе большую белую обезьяну. Большую и белую - гориллу, мартышку, шимпанзе, не важно. Самое главное, что она белая. Запустите не телефоне (или где ещё) секундомер - ваша задача в течении двух минут НЕ ДУМАТЬ о белой обезьяне. Если подумали - хлопните в ладоши. Или стукните по столу.
Сколько раз вы вспомнили о белой обезьяне? Три, пять, десять?
Нам просто очень сложно не делать что-то без представления о том, что делать вместо этого.
Поэтому - больше позитивного подкрепления.
Когда родители только ругают ребёнка за плохие оценки, и особо не хвалят за хорошие - такое подкрепление работает плохо. Точно так же начальник, который только ругает за ошибки, и не считает важным похвалить за достижения - снижает эффективность работы подчинённых.
Подкрепление сразу после нужного события
Чем чётче бессознательное может связать между собой подкрепление и событие - тем лучше. Ему же ещё нужно понять, какое конкретное поведение вызывает такую реакцию. Поэтому чем быстрее получено подкрепление после нужного поведение - тем быстрее ваработается навык. Сделали десять приседаний - сразу похвалили себя. Заметили собственную ошибку в тексте - сразу немного огорчились, ту же исправили и сразу же сильно порадовались. Дописали статью - попили чая с печенькой. А если вы делаете упражнение желательно, чтобы обратная связь была сразу после его выполнения, а не в конце занятия или в конце курса.
Позитивное подкрепление после занятия
После всего занятия - по иностранному языку, йоге, калибровке или вычислению интегралов - сделайте себе приятно. Похвалите себя, съешьте конфетку или просто воспроизведите сильный позитивный якорь.
Вариабельное подкрепление после заучивания
После того, как вы научились чему-то, полезно изредка себя подхваливать. Не постоянно - постоянное подкрепление после заучивания начинает ухудшать навык.
Чем подкреплять
Своё собственное поведение можно подкреплять
озитивно: положительной эмоцией, похвалой, подарком самому себе, лакомством (конфеткой или кусочком печеньки), позитивным якорем;
негативно: негативной эмоцией, болью (можно себя слегка ущипнуть), негативным якорем.
Чужое поведение можно подкреплять:
позитивно: улыбкой, демонстрацией позитивной эмоции, вниманием, согласием, похвалой, позитивным символом, вроде поднятого вверх большого пальца, лакомством, позитивным якорем;
негативно: недовольным выражением лица, демонстрацией негативной эмоции, несогласием, негативным символом (большой палец вниз), отрицательным якорем.
Подкрепление в коммуникации
Во время общения точно так же можно обучить собеседника каким-то полезным навыкам: говорит медленнее, сидеть более ровно, улыбаться, расслабиться или прекратить смотреть в телефон во время занятия. Правила здесь всё те же, просто всё происходит намного быстрее. Например, вы хотите, чтобы ваш собеседник говорил спокойнее - как только он начинает говорить спокойнее, вы улыбаетесь и киваете головой, начинает напрягаться - чуть хмуритесь и киваете головой отрицательно. Постепенно он во время разговора с вами начинает говорит всё более и более спокойно.
Я так ради эксперимента обучил продавцов на рынке, на котором я регулярно закупаюсь, улыбаться уже при виде меня.
Если же вы хотите, чтобы человек что-то не делал, то всё равно вам нужно использовать и позитивное, и негативное подкрепление. Например, ваш собеседник или участник тренинга регулярно отвлекается и смотрит в сторону. Просто каждый раз, когда он отвлекается вы хмуритесь и понижаете голос, а когда он смотрит на вас – улыбаетесь и голос слегка повышаете. Через некоторое время он станет отвлекаться всё меньше, а смотреть на вас всё больше.
Здесь очень важна точность и чёткость обратной связи.
Вам нужно слегка улыбаться и согласно кивать головой каждый раз и именно в том момент, как собеседник начинает говорить спокойнее. И начинать слегка хмуриться и отрицательно кивать головой каждый раз и именно в тот момент, когда он начинает говорить более напряжённо.
В таком варианте через три-пять минут разговора вы уже заметите вполне чёткие изменения.
Читайте также: