
Кто осуществляет выбор архитектуры будущего хранилища данных
Обновлено: 02.07.2024
Надёжное хранение данных — задача, которую приходится решать каждому бизнесу. Но когда повышаются объёмы информации, растут и требования к надёжности хранения данных. Чтобы организовать наилучшую работу с информацией, стоит обратиться к СХД — системе хранения данных.
В материале расскажем о том, что такое и как устроены СХД, какие проблемы они решают, как классифицируются и на какие характеристики следует смотреть в первую очередь, если вы не так давно в этой отрасли.
Что такое СХД и какие проблемы она решает
СХД (Система хранения данных или Сервер хранения данных) — это устройство для хранения и управления данными, их резервного копирования. Она призвана решить типичные проблемы, связанные с растущими объёмами информации в любой организации.
Если раньше все данные могли храниться буквально на одном жёстком диске, то сейчас любая функциональная система требует отдельного хранилища – к примеру, серверов электронной почты, СУБД, домена и так далее. Поэтому с помощью СХД можно организовать децентрализацию информации (рассредоточение её по разным хранилищам).
Лавинообразный рост размера информации, который вызван, с одной стороны, ужесточением регулирования и требованием сохранять всё больше информации, связанной с ведением бизнеса. С другой стороны, ужесточение конкуренции требует всё более глубокого анализа информации о рынке, клиентах, их предпочтениях, заказах и действиях конкурентов. Но количества жёстких дисков, которые вы можете установить в конкретный сервер, не может покрыть необходимую системе ёмкость. В этом тоже может помочь СХД.
Хранение данных — не единственная функция современных СХД. Они также предлагают экономить место в хранилище с помощью дедупликации и компрессии. Компрессия позволяет системе сжимать файлы, исключая избыточную информацию, а дедупликация помогает экономить место для хранения, исключая избыточные файлы и оставляя лишь ссылки на них.
Некоторым компаниям тяжело контролировать и ограничивать доступ из-за политики безопасности предприятия. Например, касается как доступа к данным по существующим для этого каналам (локальная сеть), так и физического доступа к носителям.
Также отметим высокие затраты используемых ресурсов для поддержания работоспособности всей информационной системы предприятия, начиная от необходимости содержать большой штат квалифицированного персонала и заканчивая многочисленными недешёвыми аппаратными решениями.
Устройство СХД
Основные компоненты типичной СХД — массив жёстких дисков (HDD или SSD), кэш-память, контроллер дискового массива, внешний корпус и несколько блоков питания.
Главная фишка СХД — это скорость работы дисковой системы. Например, если ваши диски стоят внутри сервера они не будут работать с такой же производительностью, как сервер подключённый к СХД.
Какие бывают системы хранения данных
Существует классификация СХД: они делятся на файловые, блочные и объектные. Каждый вид СХД определяет в каком виде хранятся данные, способ доступа к ним, и, как результат, простоту управления и скорость доступа к данным.
Файловые
Хранят информацию в виде файлов, собранных в каталоги (папки). Файлы организуются и извлекаются благодаря метаданным, которые сообщают, где находится тот или иной файл. Условно такую систему можно представить в виде каталога.
Блочные
Данные хранятся независимо друг от друга. Каждому такому блоку присваивается идентификатор, который позволяет системе размещать каждый блок, где ей удобно. Блочные хранилища не полагаются на единственный путь к данным (в отличии от файловых хранилищ).
Объектные
Принцип работы СХД — NAS, SAN и DAS
Существует несколько аппаратных компонентов, программного обеспечения и протоколов, которые в конечном итоге придают решениям для хранения данных их особые свойства.
На основе классификации выше выделяют два основных типа СХД: они различаются уровнем хранения, чтения и записи данных.
О каждом из них расскажем подробнее.
NAS расшифровывается как Network Attached Storage, что можно условно перевести как сетевое хранилище. Поскольку данные обрабатываются на уровне файлов, сервер представляется NAS как сетевой сервер со своей собственной файловой системой.
Если объяснить проще — представьте себе стационарный компьютер, который подключён к домашнему роутеру. На нём хранятся фото, видео, документы и другие данные. Сетевой доступ разрешен всем пользователям — приблизительно так выглядит NAS.
NAS-хранилище может принимать разные формы. Например, к производственному серверу могут быть подключены другие серверы, виртуальные машины или так называемые дисковые станции, на которых находится другое количество съёмных жестких дисков.
Преимущества NAS:
- Доступность и низкая стоимость.
- Простота подключения и управления.
- Гибкость, возможность быстро увеличить объём для хранения данных.
- Универсальность клиентов (компьютер под управлением любой операционной системы может получить доступ к файлам).
Недостатки NAS:
- Хранение данных только в виде файлов.
- Медленный доступ к информации по сетевым протоколам (по сравнению с локальной системой).
- Невозможность работы некоторых приложений с сетевыми дисками.
DAS расшифровывается как Direct Attach Storage — прямое подключение к рабочей станции, хранилищу). Например, подключение внешнего диска по USB условно можно назвать DAS.
Из принципиальной простоты архитектуры DAS следуют её основные преимущества: доступная цена и относительная простота внедрения. Кроме того, такой конфигурацией легче управлять ввиду хотя бы того, что число элементов системы мало.
Внутри системы находится блок питания, охлаждение и RAID-контроллер, который обеспечивает надёжность и отказоустойчивость хранилища. Управляется при помощи встроенной операционной системы.
Достоинства DAS:
- Легкость развёртывания и администрирования.
- Высокая скорость передачи данных.
- Низкая стоимость оборудования.
Недостатки DAS:
- Требует выделенного сервера).
- Ограничения в подключениях (не больше двух серверов).
В свою очередь SAN — это сети хранения данных. Как правило они представлены в виде внешних хранилищ на нескольких сетевых блочных устройствах и реализованы в виде протокола FC (Fiber Channel) или iSCSI (Internet Small Computer System Interface). Это блочный доступ непосредственно к устройству хранения — диску или наборов дисков в виде RAID-групп или логических устройств.
Кстати, вышеупомянутый DAS может быть очень мощным и часто более дешёвым, чем SAN. Однако в то же время недостаток DAS в том, что он не может быть легко расширен — количество подключённых компьютеров ограничено физическим количеством портов SAS на DAS (обычно их всего четыре). Поэтому многие компании и учреждения предпочитают выбирать блочные хранилища, подключенные через SAN.
Преимущества SAN:
- Высокая скорость работы, низкая задержка.
- Гибкость и масштабируемость.
- Хранение данных блоками.
- Высокая надёжность обмена и хранения данных.
- Разгрузка подсети от служебного трафика.
Недостатки SAN:
- Сложность проектирования
- Высокая стоимость.
- Невозможность некоторых приложений и систем работать с протоколом iSCSI.
Как выбрать СХД?
В первую очередь нужно понимать, какие задачи она будет решать. Важно определиться с несколькими базовыми параметрами.
Тип данных
Разные типы данных требуют разной скорости доступа, технологий обработки, компрессии и так далее. К примеру, виртуальный СХД для работы с большими медиа-файлами отличается от той системы, которая будет работать с неструктурированными данными для нейросети.
Объём данных
От этого зависит выбор дисковых накопителей. Иногда можно обойтись SSD потребительского класса — если известно, что ёмкость СХД даже в худшем случае не будет превышать 300 ГБ, а скорость доступа не критична.
Отказоустойчивость
Необходимо представлять, какова стоимость потери данных за определённое время. Это поможет рассчитать RPO (Recovery-Point Objective) и RTO (Recovery Time Objective), а также избежать лишних затрат на резервное копирование. Бэкапы, бэкапы и ещё раз бэкапы.
Производительность
Если СХД закупается под новый проект (нагрузку которого сложно предугадать), то лучше пообщаться с коллегами, которые уже решали эту задачу или протестировать СХД.
Вендор
Иногда даже для ресурсоемкого сервиса подойдет бюджетное или среднеуровневое решение (StarWind, Huawei, Fujitsu). Однако у топовых производителей — NetApp, HPE, Dell EMC — линейка продуктов достаточно широкая, и сравнительно недорогие СХД здесь также можно найти. В любом случае, желательно сильно не расширять количество вендоров на одной инфраструктуре.
Если сейчас вы находитесь в поисках решения для работы с данными, арендовать выделенный web-сервер и СХД (системы хранения данных) можно в одном из наших ЦОД. Мы, со своей стороны, обеспечим сервер быстрым соединением с интернетом на скорости до 10 Гбит/сек, постоянным подключением к электричеству и поддержкой 27/7 ;).

До 2022 года объем генерируемых предприятиями данных продолжит увеличиваться приблизительно на 42,2% в год.

В эпоху цифровой трансформации количество цифровых данных в мире измеряется миллиардами терабайт. Форсированный переход в онлайн на фоне пандемии еще больше подхлестнул их беспрецедентный рост, и это уже дает свои плоды в виде усложнения и повышения разнообразия экосистемы данных, которая сегодня включает в себя многооблачные и периферийные среды. Применение IoT, AI, смарт-технологий набирает обороты, соответственно растет и потребность в вычислительных ресурсах. Предпринимателям приходится признать, что управлять данными стало гораздо сложнее.
Эксперты Seagate проанализировали глобальный рынок данных, выделив пять ключевых тенденций, которые ярко проявят себя в наступившем 2021 году, и сформулировали рекомендации для бизнеса в новых условиях.
Рост применения иерархической схемы обеспечения безопасности
Рекомендация
Во многих отраслях шифрование неактивных данных для защиты от внешних и внутренних угроз становится обязательным. Даже если в вашей конкретной отрасли требование такого шифрования еще не введено, в ближайшее время ситуация может измениться, и есть смысл задуматься об оперативном переходе на накопители с шифрованием, дабы в дальнейшем избежать сбоев из-за ввода в действие соответствующих норм.
Более широкое применение объектных хранилищ на предприятиях
Взрывной рост объемов полезных данных привел к тому, что именно объектное хранилище становится предпочтительным для их размещения. Одно из главных преимуществ такого решения — возможность использования директивных метаданных, масштабируемость и отсутствие иерархической структуры. Современным системам необходима более интеллектуальная обработка наборов данных, а объектные хранилища как раз и дают соответствующие средства для этого.
Существуют три типа хранилищ: блочные, файловые и объектные. Блочные необходимы для критически важных приложений, которым требуется высокая производительность. Файловые применяются для устаревших приложений, обеспечивая надежную архитектуру хранения. А объектные хранилища используются при разработке новых приложений и применяются в сочетании с блочными хранилищами, что обеспечивает и масштаб, и высокое быстродействие. Многие устаревшие файловые приложения переводят на инфраструктуру объектного хранилища, которая позволяет им использовать эффект масштаба.
Рекомендация
Объектное хранилище становится фактическим стандартом хранилища большой емкости, одновременно дополняя файловые хранилища и вытесняя их благодаря более высокой экономической эффективности и масштабируемости. Кроме того, нынешние выпускники-программисты чаще всего выстраивают рабочие процессы с расчетом на использование интерфейсов объектного хранения, и на работу лучше нанимать именно таких специалистов. Если вы еще не внедрили объектное хранилище в центре обработки данных, сейчас самое время сделать это.
Рост освоения компонуемых систем & открытый код
Идея разделения систем на независимые модули, которые можно комбинировать друг с другом, не нова, однако в настоящее время происходит более широкое освоение концепции компонуемости на основе ПО с открытым кодом. Стержнем этой тенденции является Kubernetes — система с открытым кодом, предназначенная для автоматизации развертывания, масштабирования контейнеризованных приложений и управления ими. За открытым кодом будущее разработки приложений, так как использование соответствующих принципов позволяет гораздо более широкому сообществу работать над решением задач, стоящих перед многими отраслями, и создавать узкоспециализированные решения на базе открытых архитектур. Сегодня будет логичнее перейти на принцип компоновки оборудования для оптимального обеспечения потребностей программных систем и бизнеса.
.jpg)
Рекомендация
В настоящий момент центры обработки данных переводят на компонуемые системы. Это обеспечивает более простое внедрение и перераспределение ресурсов и в то же время не требует необходимости предварительно задавать конфигурации и статично выбирать соотношения между ресурсами вычислений, памяти и хранения. Фундаментом компонуемости становятся контейнеры и система Kubernetes, и сегодня эти технологии необходимо внедрять во всех центрах обработки данных.
Разделение архитектуры хранения больших объемов данных на уровни
В NVIDIA предусмотрели программный интерфейс для использования преимуществ многоуровневой памяти и программирования систем, оптимизированных для такой архитектуры. По аналогии твердотельные накопители и жесткие диски можно применять на разных уровнях хранилища. Сегодня, когда генерируются очень большие объемы полезных данных, использовать для них однородное хранилище было бы неэффективно.
Почему это важно? СХД, выполненная исключительно на высокопроизводительных накопителях, скорее всего, будет отличаться слишком высокой стоимостью, а состоящая только из накопителей большой емкости характеризовалась бы недостаточной производительностью. Именно поэтому развивается нынешняя тенденция разделения на уровни, ведь такая схема обеспечивает самый эффективный баланс стоимости и производительности. С появлением новых технологий (например, памяти класса хранилища) становятся остро актуальными архитектуры, позволяющие извлекать максимальную пользу из хранилищ всех уровней.
Рекомендация
Формативный AI увеличивает пользу данных
На фоне взрывного роста данных увеличивается и количество полезной информации. Сегодня даже архивные данные восстанавливают, чтобы обрабатывать их средствами искусственного интеллекта и машинного обучения и получать дополнительные сведения. Руководителям предприятий нужно подготовиться к хранению еще большего объема данных для обучения моделей и извлечения критически важных сведений, а также к увеличению размеров архивов с учетом того, что срок их службы становится более длительным. Благодаря формативному AI из данных удается извлекать больше полезных сведений.
Аналитики Gartner определяют формативный AI как искусственный интеллект, способный динамически меняться в зависимости от ситуации. В IDC, в свою очередь, к формативному AI относят целый ряд новых технологий в сфере ИИ и смежных областях. Отличительная черта таких технологий — способность динамически меняться, реагируя на изменения ситуации.
Формативный AI имеет отношение и к тенденции разделения хранилищ на уровни, поскольку для этого необходима гибкая архитектура, способная интеллектуально реагировать на изменения.
Допустим, при мониторинге модели AI наблюдаются отклонения сигнала. В этом случае с помощью другой модели можно выполнить поиск соответствующих учебных данных на дисковом уровне и автоматически перенести их на флеш-уровень, чтобы обучение проходило быстрее. При этом дисковый уровень, скорее всего, будет организован по схеме объектного хранилища, то есть соответствующая тенденция тоже играет здесь свою роль. В этом случае преимуществами станут скорость (так как данные автоматически перемещаются на быстрый уровень) и уменьшение затрат (данные можно хранить на недорогих дисках в легкодоступном формате до момента, когда они понадобятся).
.jpg)
Рекомендация
Прогресс в области машинного обучения за последнее время позволяет по-настоящему раскрывать потенциал искусственного интеллекта. Вместе с тем системам машинного обучения необходимы наборы данных все большего размера, чтобы извлекать из них более точные сведения. Будущие возможности машинного обучения предсказать сложно, однако компаниям необходимо уже сегодня сохранять как можно больше данных. Ведь только так можно позаботиться о том, чтобы будущие аналитические системы работали с использованием лучших учебных выборок.
По прогнозам Seagate и IDC, до 2022 года объем генерируемых предприятиями данных продолжит увеличиваться приблизительно на 42,2% в год. При этом лишь 32% доступных бизнес-данных используются организациями эффективно, а остальные 68% остаются без внимания. Более того, во многих организациях собирается лишь половина данных, которые потенциально могут быть получены в результате их деятельности. Данные таят в себе огромные возможности извлечения ценности, но эти возможности часто упускают.
Ожидается, что к 2025 году 44% всех данных, созданных в центре и на периферии, будут использоваться для аналитики, искусственного интеллекта и глубокого обучения, а данные с растущего числа IoT-устройств будут передаваться на периферию корпоративной сети. Центр тяжести данных смещается и в направлении центра, и в направлении периферии. К тому же 2025 году почти 80% всех данных в мире будут храниться в центре и на периферии и, как предполагает IDC, емкость запоминающих устройств (жестких и оптических дисков, твердотельных и ленточных накопителей), используемых предприятиями, составит 12,6 зеттабайт. Поставщики облачных услуг будут управлять 51% этой емкости.
С одной стороны, системы бизнес-аналитики разрабатываются и внедряются довольно давно, существуют у каждого предприятия в том или ином виде, с другой стороны, не хватает согласованной терминологии. Также на существующих аналитических системах мы часто сталкиваемся с тем, что в них отсутствует изначально заложенный фундамент, обеспечивающий управляемое функционирование и органическое развитие таких систем.
Что такое аналитические системы
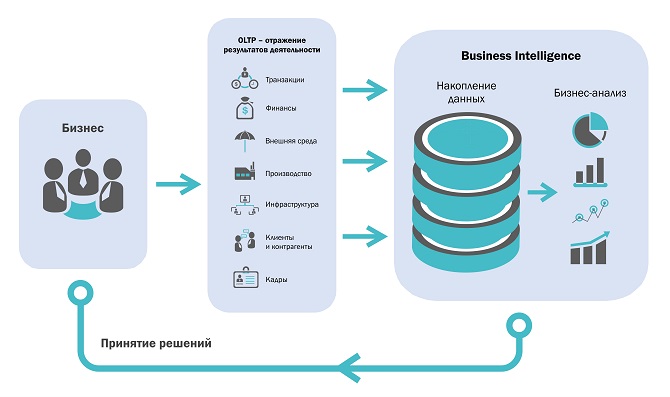
Прежде всего хотелось бы рассказать про категоризацию ИТ-систем в целом. Они делятся на два больших класса — оперативные системы (OLTP) и аналитические системы (BI).
Классификация BI-систем
Чтобы лучше разобраться в типах BI-систем давайте обратимся к истории развития аналитических систем.
Вначале автоматизировалась регламентная (стандартизованная) отчетность путем оптимизации процессов ее подготовки с помощью ИТ-системы. Такое применение аналитической системы упрощает, ускоряет подготовку отчетности и делает ее более надежной и качественной, но принципиально не изменяет подходы к анализу данных.
С развитием технологий появилась возможность создания решений для динамического интерактивного анализа. Такие решения позволяют проводить в онлайн-режиме различные виды анализа, конструировать аналитику по произвольным атрибутам, настраивать различные фильтры, оперативно конфигурировать любой требуемый табличный и графический вид представления отчетности.
Наконец, прогнозная (предиктивная) аналитика позволяет с помощью методов машинного обучения и искусственного интеллекта создавать новые данные, находить неявные закономерности, делать прогнозы на будущее, проводить what-if анализ.
В соответствии с этой классификацией можно говорить о функциональном разделении BI-систем, причем конкретная система может выполнять одну или несколько функций:
Как связаны аналитические системы и хранилище данных
Хранилище данных (ХД) является основой и ядром аналитической системы. Стоит отметить, что это не просто некая база данных, хранящая данные на постоянной или временной основе и используемая в процессе подготовки аналитических материалов (что часто соответствует интуитивному и несколько вульгарному представлению о сущности ХД), а информационная система, обладающая определенными свойствами.
ХД — важнейшая часть процесса принятия управленческих решений — и это еще раз говорит о том, что аналитическая система нацелена на высокоуровневый обзор состояния компании.
ХД является предметно-ориентированной системой: данные организуются в объектную модель, отвечающую предметной области конкретной компании.
ХД неволатильно, то есть всегда достаточно статично и организовано таким образом, что обновление данных происходит за счет отслеживания изменений, произошедших в информационных системах-источниках. Например, данный принцип запрещает полную перезаливку данных при обновлении, что порой встречается на хранилищах небольшого объема. Такой подход хоть и быстрее в реализации, но приводит к проблемам в долгосрочной перспективе. В ХД должны быть предусмотрены механизмы инкрементальной загрузки данных.
ХД хранит всю истории деятельности компании. Это означает, что хранятся все данные, загруженные из любых источников. Переход с одной производственной системы на другую, архивация данных и изменение горизонта хранения данных в исходной системе не должны влиять на базовый принцип хранения данных в ХД за все время.
Важным моментом являются надежность и адаптивность ХД. Оно должно быть построено таким образом, чтобы гибко реагировать на структурные изменения в системах-источниках. ХД должно быть робастным, что означает, что изменения входящих данных определенного масштаба должны приводить к изменениям в хранилище такого же или меньшего масштаба, например, изменение или удаление какого-то поля одной таблицы не должно приводить к остановке обновления всего хранилища. Появление нового источника данных должно укладываться в существующую архитектуру, а не приводить к запуску нового проекта по переделке хранилища, а то и построению новой системы рядом со старой.
В силу того, что ХД объединяет данные всей компании, инициативы по ее внедрению должны координироваться между всеми отделами — потенциальными пользователями системы, то есть принято бизнес-средой. Каждое из подразделений, поставляющих данные в ХД и планирующее использовать результаты внедрения системы, должно быть активно вовлечено в проект развития ХД, проверять качество данных, принимать результаты на всех этапах проекта. В противном случае, легко может произойти ситуация, когда после завершения проекта результаты не используются в должной мере из-за их несогласованности с потребностями конкретных бизнес-пользователей. Здесь мы видим еще одно принципиальное различие между оперативными и аналитическими системами. Развитие первых – в первую очередь зона ответственности ИТ-отдела, вторые инициируются и развиваются как мероприятие стратегического уровня с зоной курирования топ менеджментом компании.
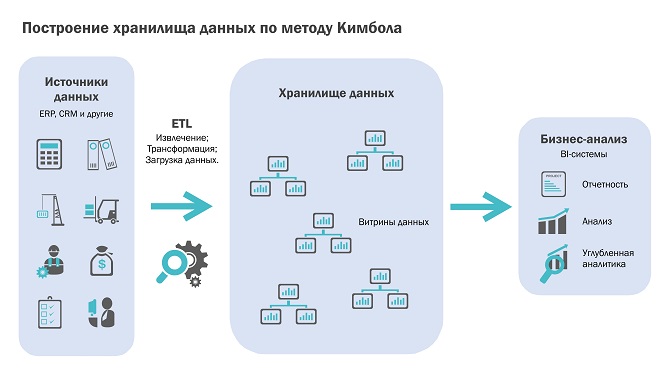
Подходы и методики по построению ХД
Наиболее известными методиками к построению ХД являются подходы Инмона и Кимбола.
Метод проектирования Кимбола работает от частного к общему (Bottom-up дизайн) и означает соединение разрозненных витрин данных, построенных для решения определенных задач предметной области, в единое ХД. При этом такие витрины данных (денормализованные по определению) являются одновременно и пользовательскими базами для построения отчетности, и местом хранения данных.
Несмотря на некоторые плюсы, к которым относится относительная быстрота разработки, следование этому подходу на сложных комплексных проектах приводит к существенным проблемам, среди которых дублирование алгоритмов и процессов загрузки, избыточность и противоречивость данных, сильная зависимость модели ХД от бизнес-требований, что приводит к волатильности модели, сложности поддержки инкрементальной загрузки и проблемам при поддержке клиентов, которым требуется не многомерная витрина данных (например, при использовании ХД как источника данных для других ИС, в том числе оперативных).
В целом можно сказать, что подход Кимбола больше подходит для пилотных проектов и небольших проектов с простой структурой источников и витрин данных.
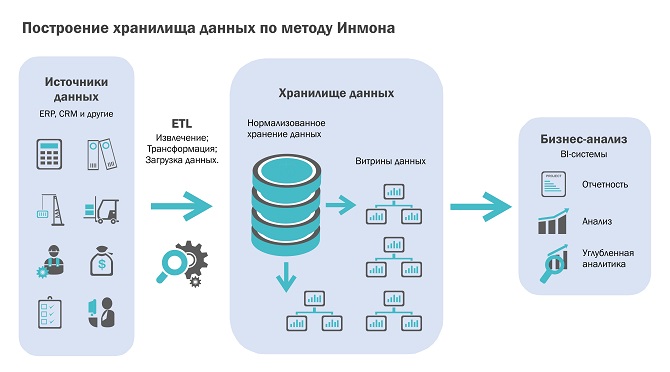
Другой подход — методология Инмона, состоящая в концепции построения единого централизованного места хранения данных и порождении пользовательских витрин данных уже из него (Top-down дизайн). Иногда считают, что этот подход противоположен методике Кимбола, но скорее можно говорить о том, что подход Инмона включает в себя концепцию витрин данных, глубоко проработанную Кимболом, нежели противоречит ей. Водораздел же между двумя концепциями заключается именно в наличии единой базы данных, которая является централизованным местом хранения данных и служит источником для витрин данных. Это положении крайне важно и поэтому заслуживает повторения и акцентирования внимания.
Таким образом, при проектировании ХД мы начинаем с построения объектной модели предметной области бизнеса и проекции этой модели на информационный уровень. При этом не обязательно строить всю модель и только потом приступать к построению витрин, вполне допустим итерационной подход.
Несмотря на некоторые минусы, к которым относится более сложная структура ХД и ETL, дополнительные затраты на первый запуск, этот подход обладает важными преимуществами, которые в долговременной перспективе могут оказать принципиальное влияние на исход проекта в целом. К ним относятся создание объектной модели бизнеса, единый язык аналитиков, разработчиков и пользователей, возможность разделения задач между разработчиками ХД и разработчиками витрин данных и отчетности, повторное использование алгоритмов и данных, непротиворечивость данных (single version of truth), устойчивость модели данных к изменчивым требованиям к отчетности и поддержка историчности мастер-данных.
Существует еще третий, менее известный подход — data vault, который заключается в развитии идеи о централизованном хранении данных, но с большим акцентом на разнородность и изменчивость данных, то есть на обеспечение таких свойств ХД, как интегрированность и адаптивность.
В наших проектах мы стараемся учитывать специфику каждого проекта для выбора оптимальной архитектуры, но магистральный подход, которого мы придерживаемся – развитие по возможности единой интегрированной универсальной базы (в силу вышеописанных преимуществ методики Инмона), которая является ядром хранилища, и на базе которого строятся пользовательские витрины данных.
Отдельным вопросом стоят формирования требования к проекту и оценка подобных проектов, но это тема для отдельной статьи.
К проектированию хранилищ данных обычно предъявляются следующие требования:
· структура данных хранилища должна быть понятна пользователям;
· должны быть выделены статические данные, которые регулярно модифицируются: ежедневно, еженедельно, ежеквартально;
· должны быть упрощены требования к запросам с целью исключения запросов, которые могли бы требовать множественных утверждений SQL в традиционных реляционных СУБД;
· должна быть обеспечена поддержка сложных запросов SQL, которые требуют последовательной обработки тысяч или миллионов записей [1].
ХД это огромный проект, включающий в себя согласование между многими частями организации. Соответствующая архитектура может помочь созданию проекта. На рис. 2.1 приводится распространенный вариант двухуровневой архитектуры построения хранилища данных.
В рамках этой архитектуры данные из операционной СУБД проходят через процесс трансформации (ETL – процесс) и затем загружаются в хранилище данных через сервер хранилища данных. Доступ к хранилищу данных для извлечения данных для принятия решений осуществляется через сервер.
Трансформационный процесс достаточно трудоемкий. Для него необходимо иметь четкое понятие о предметной области хранилища данных. Для лучшего понимания предметной области необходимо начать построение хранилища данных с концептуальной модели.
Рис. 2.1. Двухуровневая архитектура построения хранилищ данных
Преимущества подобной архитектуры заключаются в следующем:
- данные хранятся в единственном экземпляре;
- минимальные затраты на хранение данных;
- отсутствуют проблемы, связанные с синхронизацией нескольких копий данных;
- данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса.
Недостатки двухуровневой архитектуры:
- данные не структурируются для поддержки потребностей отдельных пользователей или групп пользователей;
- возможны проблемы с производительностью системы;
- возможны трудности с разграничением прав пользователей на доступ к данным.
В случае выбора архитектуры СППР на основе трехуровневого хранилища данных, последнее представляет собой единый централизованный источник информации для всего предприятия. Витрины данных отражают подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса (рис. 2.2).
Рис. 2.2. Трехуровневая архитектура построения хранилищ данных
Eе преимущества заключаются в том, что:
- создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных;
- имеется (построена) общая структура данных предприятия;
- витрины данных синхронизированы и совместимы с общей структурой данных предприятия;
- существует возможность сравнительно легкого расширения хранилища и добавления новых витрин данных;
- гарантированная производительность.
Недостатки трехуровневой архитектуры:
- избыточность данных, ведущая к росту объема хранилища;
- требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу).
Тем не менее, несмотря на указанные недостатки, последняя конструкция наилучшим образом отвечает возможности решения самых разнообразных аналитических и управленческих задач в любой сфере деятельности.
Очевидно, что для принятия качественного решения необходим достаточно полный и глубокий анализ данных, который просто невозможно провести без специального программного обеспечения. Конечно, можно было бы воспользоваться и более простыми программными продуктами такими, как электронные таблицы. Но это годилось бы только для единичных решений, имеющих место один раз в большой промежуток времени.
Предприятие, как правило, ставит перед собой задачу консолидации – накопления – данных различных отделов, для того, чтобы в будущем избежать проволочек с ее получением, а также для ее своевременного обновления. Кроме того, принятие решения в условиях современности предполагает автоматизацию всего процесса анализа данных, начиная от сбора данных и заканчивая формированием необходимой аналитической отчетности. И, наконец, самым важным в формировании механизма принятия решений является возможность поставить его на поток, т. е. обеспечить неоднократное его использование.
Все эти функции сочетают в себе аналитические платформы. Сегодня на рынке программного обеспечения предлагается большое количество таких программных решений. В настоящих методических указаниях мы остановимся на одном из них, а именно платформе Deductor Studio Academic 5.2. Поскольку предоставление полного лицензионного пакета осуществляется на коммерческой основе, работа с данной платформой будет осуществляться в рамках учебной версии.
Кроме возможности работать с единым источником информации, руководители и аналитики должны иметь удобные средства визуализации данных, агрегирования, поиска тенденций, прогнозирования. Несмотря на многообразие аналитической деятельности, можно выделить типовые технологии анализа данных, каждой из которых соответствует определенный набор инструментальных средств. Вместе с хранилищем данных эти средства обеспечивают полное решение для автоматизации аналитической деятельности и создания корпоративной информационно-аналитической системы.
Читайте также:
- Как называется массовое собрание граждан по поводу злободневных как правило политических вопросов
- Когда можно ездить за рулем после маммопластики
- Россия сняла с себя обязательства по защите граждан во время войны что это значит
- Поиск файлов и папок можно осуществлять с помощью
- Кл час что значит быть ответственным на улицах и дорогах 2 класс