
Какие два интерфейса предоставляют возможность хранить объекты в виде пары ключ значение
Обновлено: 17.05.2024
Ситуации для хранения и обработки данных в браузере включают:
- сохранение состояния клиентского приложения, такого как текущий экран, введенные данные, пользовательские настройки и т. д.
- утилиты, которые обращаются к локальным данным или файлам и имеют строгие требования к конфиденциальности
- прогрессивные веб-приложения (PWA), которые работают в автономном режиме
Вот десять вариантов хранения данных браузера:
В этой статье рассматриваются эти десять различных способов хранения данных в браузере, рассматриваются их ограничения, плюсы и минусы, а также наилучшее использование каждого метода. Прежде чем мы перейдем к вариантам, сделаем небольшое примечание о сохранении данных.
Сохранение данных
Как правило, данные, которые сохраняются, будут:
- Постоянные (persistent): они остаются до тех пор, пока ваш код не решит удалить их, или
- изменяемые (volatile) : они остаются до завершения сеанса браузера, обычно, когда пользователь закрывает вкладку
Постоянные данные могут быть заблокированы или удалены пользователем, операционной системой, браузером или плагинами в любой момент. Браузер может принять решение об удалении более старых или больших элементов по мере приближения к граничной емкости, выделенной для этого типа хранилища.
Браузеры также записывают состояние страницы. Вы можете уйти с сайта и кликнуть назад или закрыть и снова открыть вкладку; страница должна выглядеть идентично. Переменные и данные, доступные только для сеанса, по-прежнему доступны.
1. Переменные JavaScript
- размер — нет строгих ограничений, но при заполнении памяти может произойти замедление работы браузера или сбои
- скорость чтения / записи — самый быстрый вариант
- сохранность — плохая: данные стираются при обновлении браузера
Сохранение состояния в переменных JavaScript — самый быстрый и простой вариант. Я уверен, что вам не нужен пример, но …
- легко использовать
- быстрота
- нет необходимости в сериализации или десериализации
- ненадежность: обновление или закрытие вкладки стирает все
- сторонние скрипты могут исследовать или перезаписывать глобальные значения (window). Вы уже используете переменные. Вы можете рассмотреть возможность сохранения состояния переменной при выгрузке страницы .
2. Хранилище узлов DOM
- размер — нет строгих ограничений, но не идеально для большого количества данных
- скорость чтения / записи — Быстрый
- сохранность — плохая: данные могут быть удалены другими скриптами или обновлением
Большинство элементов DOM на странице или в памяти могут хранить значения в именованных атрибутах. Безопаснее использовать имена атрибутов с префиксом data-:
- атрибут никогда не будет иметь связанных функций HTML
- Вы можете получить доступ к значениям с помощью свойства dataset или через методы .setAttribute() и .getAttribute().
Значения хранятся в виде строк, поэтому может потребоваться сериализация и десериализация. Например:
- вы можете определять значения в JavaScript или HTML, например
- полезно для хранения состояния конкретного компонента
- DOM работает быстро! (вопреки распространенному мнению)
- ненадёжно: обновление или закрытие вкладки стирает значения
- только строки: требуется сериализация и десериализация
- большой DOM влияет на производительность
- сторонние скрипты могут исследовать или перезаписывать значения
Хранилище узлов DOM работает медленнее, чем переменные. Используйте его экономно в ситуациях, когда удобно хранить состояние компонента в HTML.
3. Web хранилище (localStorage и sessionStorage)
- размер — 5 МБ на домен
- скорость чтения / записи — синхронная работа: может быть медленной
- сохранность — данные остаются до тех пор, пока не будут удалены
Веб-хранилище предоставляет два похожих API для определения пар имя/значение. Используйте:
- window.localStorage для хранения постоянных данных и
- window.sessionStorage для сохранения данных только сеанса, пока вкладка браузера остается открытой
Храните или обновляйте именованные элементы с помощью .setItem():
Получайте их с помощью .getItem():
И удалите их с помощью .removeItem():
Другие свойства и методы включают:
- .length: количество хранимых элементов
- .key(N): имя N-го ключа
- .clear(): удаление всех сохраненных элементов
Изменение любого значения вызывает событие хранения в других вкладках / окнах браузера, подключенных к тому же домену. Ваше приложение может ответить соответствующим образом:
- простой API (пары имя / значение)
- параметры сеанса и постоянного хранилища
- хорошая поддержка браузера
- Только строки: требуется сериализация и десериализация
- неструктурированные данные без транзакций, индексации или поиска
- синхронный доступ повлияет на производительность больших наборов данных
Веб-хранилище идеально подходит для простых, небольших и разовых значений. Оно менее практично для хранения больших объемов структурированной информации, но вы можете избежать проблем с производительностью, записывая данные при выгрузке страницы.
4. IndexedDB
- размер — зависит от устройства. Не менее 1 ГБ, но может составлять до 60% оставшегося дискового пространства
- скорость чтения / записи — быстрый
- сохранность — данные остаются до тех пор, пока не будут удалены
IndexedDB предлагает низкоуровневый API, похожий на NoSQL, для хранения больших объемов данных. Хранилище можно индексировать, обновлять с помощью транзакций и выполнять поиск с помощью асинхронных методов.
IndexedDB API сложен и требует некоторого манипулирования событиями. Следующая функция открывает соединение с базой данных при передаче имени, номера версии и дополнительной функции обновления (вызываемой при изменении номера версии):
Следующий код подключается к базе данных myDB и инициализирует хранилище объектов todo (аналогично таблице SQL или MongoDB). Затем он определяет автоматически увеличивающийся ключ с именем id:
Как только соединение будет готово, вы можете с помощью .add добавить новые элементы данных в транзакцию:
И вы можете получить значения, например, первый элемент:
- гибкое хранилище данных с самым большим пространством
- надежные транзакции, возможности индексации и поиска
- хорошая поддержка браузера
- сложный обратный вызов и API на основе событий
- IndexedDB — лучший вариант для надежного хранения больших объемов данных, но вам может понадобиться библиотека-оболочка, такая как idb , Dexie.js или JsStore .
5. Cache API
- размер — зависит от устройства, но Safari ограничивает каждый домен до 50 МБ
- скорость чтения / записи — быстрый
- сохранность — данные остаются до очистки или через две недели в Safari
Аналогичная функция может получить элемент из кеша. В этом примере она возвращает основной текст ответа:
- хранит любой сетевой ответ
- может улучшить производительность веб-приложений
- позволяет веб-приложению работать в автономном режиме
- современный API
- не практично для хранения состояния приложения
- возможно менее полезно за пределами прогрессивных веб-приложений
Apple недоброжелательно относится к PWA и Cache API
Cache API — лучший вариант для хранения файлов и данных, полученных из сети. Вы, вероятно, могли бы использовать его для хранения состояния приложения, но он не предназначен для этой цели, и есть варианты получше.
5.5 AppCache
AppCache был предшественником Cache API . Это не то решение для хранения, которое вы ищете. Здесь ничего нет. Пожалуйста, двигайтесь дальше.
6. API доступа к файловой системе
- размер — зависит от оставшегося места на диске
- скорость чтения / записи — зависит от файловой системы
- сохранность — данные остаются до тех пор, пока не будут удалены
API доступа к файловой системе позволяет браузеру читать, записывать, изменять и удалять файлы из локальной файловой системы. Браузеры работают в изолированной среде, поэтому пользователь должен предоставить разрешение на определенный файл или каталог. Чтобы веб-приложение могло читать или записывать данные, как настольное приложение, используют FileSystemHandle.
Следующая функция сохраняет объект Blob в локальный файл:
- веб-приложения могут безопасно читать и записывать в локальную файловую систему
- меньше необходимости загружать файлы или обрабатывать данные на сервере
- отличная функция для прогрессивных веб-приложений
- минимальная поддержка браузера (только Chrome)
- API может измениться
Этот вариант хранения для меня очень интересен, но вам придется подождать пару лет, прежде чем он станет жизнеспособным для производственного использования.
7. API записей файлов и каталогов
- размер — зависит от оставшегося места на диске
- скорость чтения / записи — неизвестный
- сохранность — данные остаются до тех пор, пока не будут удалены
API записей файлов и каталогов предоставляют песочницы файловой системы доступной для домена, которые могут создавать, писать, читать и удалять каталоги и файлов.
- нестандартные, несовместимость между реализациями и поведение могут измениться.
MDN прямо заявляет: не используйте это на производственных сайтах . Поддержка будет в лучшем случае через несколько лет.
8. Файлы cookie
- размер — 80 КБ на домен (20 файлов cookie размером до 4 КБ в каждом)
- скорость чтения / записи — быстрый
- сохранность — хорошая: данные остаются до тех пор, пока они не будут удалены или не истечет время их жизни
document.cookie устанавливает значения cookie в клиентском JavaScript. Вы должны определить строку с именем и значением, разделенными символом равенства (=). Например:
Значения не должны содержать запятых, точек с запятой или пробелов, поэтому может потребоваться encodeURIComponent():
К дополнительным настройкам файлов cookie можно добавить разделители через точку с запятой, в том числе:
Пример: установить файл cookie, срок действия которого истекает через 10 минут и доступен по любому пути в текущем домене:
document.cookie возвращает строку, содержащую каждую пару имени и значения, разделенную точкой с запятой. Например:
Функция ниже анализирует строку и преобразует ее в объект, содержащий пары имя-значение. Например:
- надежный способ сохранить состояние между клиентом и сервером
- ограничен доменом
- автоматический контроль истечения срока действия с помощью max-age (секунд) или Expires (дата)
- используется в текущем сеансе по умолчанию (установите дату истечения срока, чтобы данные сохранялись после обновления страницы и закрытия вкладки)
Избегайте файлов cookie, используйте их если нет реальной альтернативы.
9. window.name
- размер — варьируется, но должно быть несколько мегабайт
- скорость чтения / записи — быстрый
- сохранность — данные сеанса остаются до закрытия вкладки
Свойство window.name устанавливает и получает имя контекста активного окна. Вы можете установить одно строковое значение, которое будет сохраняться между обновлениями браузера. Например:
Исследуйте значение, используя:
- легко использовать
- может использоваться только для данных сеанса
- Только строки: требуется сериализация и десериализация
- страницы в других доменах могут читать, изменять или удалять данные (никогда не используйте их для конфиденциальной информации)
Window.name не предназначен для хранения данных. Это хак, и есть варианты получше.
10. WebSQL
- размер — 5 МБ на домен
- скорость чтения / записи — медленная
- сохранность — данные остаются до тех пор, пока не будут удалены
WebSQL был попыткой перенести в браузер хранилище баз данных, подобное SQL. Пример кода:
Chrome и некоторые версии Safari поддерживают эту технологию, но против нее выступили Mozilla и Microsoft в пользу IndexedDB.
- разработан для надежного хранения и доступа к данным на стороне клиента
- знакомый синтаксис SQL, часто используемый серверными разработчиками
- ограниченная поддержка браузеров
- несогласованный синтаксис SQL в браузерах
- асинхронный, но медленный API на основе обратного вызова
- плохая работа
Не используйте WebSQL! Он не был жизнеспособным вариантом с тех пор, как устарела его спецификация в 2010 году.
Тщательная проверка хранилища
API хранилища может исследовать пространство , доступное для веб-хранилища, IndexedDB, и Cache API. Все браузеры, кроме Safari и IE, поддерживают это API, которое предлагает метод .estimate() для вычисления значений quota (пространства, доступного для домена) и usage (пространства, уже используемого). Например:
Доступны еще два асинхронных метода:
- .persist() : возвращает true если у сайта есть разрешение на хранение постоянных данных, и
- .persisted() : возвращает true если сайт уже сохранил постоянные данные
Заключение
Ни одно из этих решений для хранения не является идеальным, и вам нужно будет внедрить несколько решений в сложное веб-приложение. Это означает изучение дополнительных API. Но иметь выбор — это хорошо — конечно, при условии, что вы можете подобрать подходящий вариант!

В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Sportmaster Lab , Санкт-Петербург , От 150 000 до 200 000 ₽
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:

База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
- Get(key) возвращает значение, связанное с переданным ключом;
- Put(key, value) связывает значение с ключом;
- Multi-get(key1, key2, . keyN) возвращает список значений, связанных с переданным ключами;
- Delete(key) удаляет запись для ключа из хранилища.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.

Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
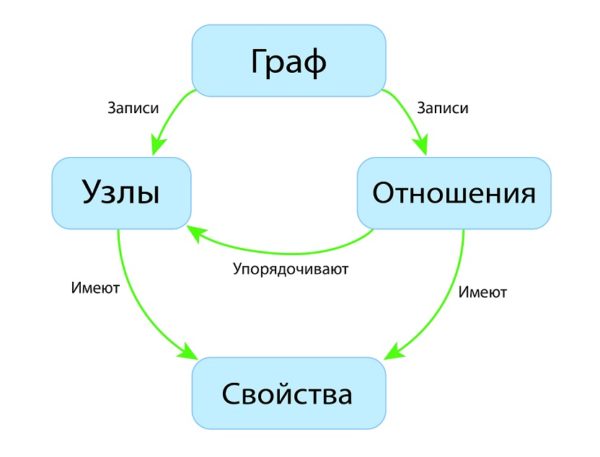
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.

Контейнерная иерархия документоориентированной базы данных содержит данные без схемы, которые можно представить в виде дерева, которое является графом. Если обращаться к документам или их элементам в этом дереве, можно получить более выразительное представление данных, в котором можно легко ориентироваться с помощью Neo4j.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
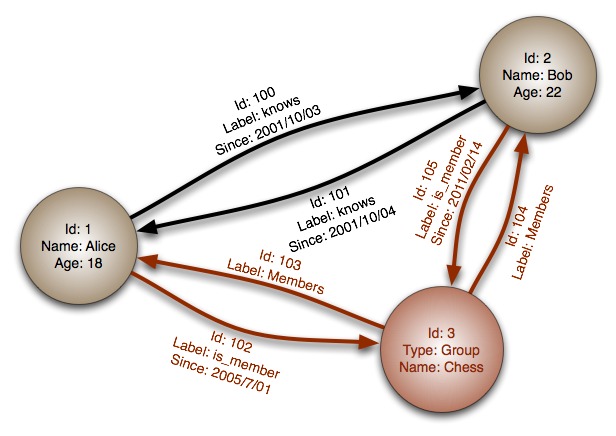
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Пример использования
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
Что такое коллекция?
Коллекция часто сравнивается с массивом. Оба хранят группы связанных объектов. Однако есть и некоторые ключевые отличия. Например, коллекции являются одномерными в отличие от массивов, которые могут иметь много измерений. Массивы, как правило, фиксируются по размеру, тогда как коллекции могут варьироваться по длине и могут позволять вставку в любой позиции в наборе.
Одним из наиболее важных преимуществ, предоставляемых коллекциями, является то, что они устраняют необходимость разработки общих структур и алгоритмов. К ним относятся уже упомянутые очередь и стек, сортированные списки, битовые массивы и ассоциативные массивы , также известные как словари или коллекции пар ключ-значение.
Упаковка и распаковка
В следующем примере показано значение, которое упаковывается и распаковывается.
Примечание: при добавлении типов значений и структур в коллекцию упаковка происходит автоматически. При извлечении значения из коллекции оно должно быть распаковано с помощью оператора cast.
Тип коллекций
- Общего назначения. Коллекции общего назначения используются для предоставления стандартных структур данных, которые содержат любой тип объекта. К ним относятся массив динамического размера, стек и очередь. Они также включают справочники, которые содержат пары ключ-значение; каждая запись имеет как уникальный ключ, так и отдельный объект value.
- Битовые коллекции. Битовые коллекции содержат группы двоичных цифр. Функциональные возможности этих коллекций специфичны для обработки битовых массивов, включая установку и сброс отдельных битов и выполнение побитовых логических операций.
- Специализированный. Специализированные коллекции предназначены для оптимизированной обработки конкретных типов данных или структуры.
Интерфейсы коллекции
Все типы коллекций используют набор общих интерфейсов. Интерфейс - это концепция объектно-ориентированного программирования. Проще говоря, интерфейсы описывают ряд общих свойств и методов, которые должны быть предоставлены любым классом, реализующим интерфейс. Общие интерфейсы определяют основные функциональные возможности каждого класса коллекций. Это означает, что один тип коллекции часто может быть легко заменен другим, поскольку их поведение будет сходным.
Каждый из ключевых интерфейсов описан ниже. Обратите внимание, что не все коллекции реализуют каждый интерфейс.
Интерфейс ICollection
Первый интерфейс - это ICollection . Каждая коллекция реализует этот интерфейс, его свойства и методы. Свойства и методы описаны в следующих разделах с примерами для ключевых элементов.
Примечание: все интерфейсы коллекции имеют префикс "I". Это общее соглашение об именовании.
ICollection.CopyTo
Метод CopyTo позволяет скопировать каждый элемент из коллекции в массив. Основной метод CopyTo принимает два параметра. Первый - это массив для заполнения. Второй - это целое число, представляющее индекс первого элемента в массиве для копирования. Каждый элемент из коллекции помещается в последующие индексы массива.
В приведенном ниже примере коллекция копируется в нулевой индекс массива, который является первым элементом. В этом примере демонстрируется использование CopyTo для ArrayList, обычно используемой коллекции, предоставляющей одномерную динамическую структуру массива. ArrayList находится в System.Collections пространстве имён, так что, чтобы выполнить пример, добавьте с using System.Collections; к исходному коду.
Примечание: строки используются на протяжении всей этой статьи в примерах. Они используются только для удобства демонстрации и могут быть заменены любым типом объекта.
ICollection.Count
Свойство Count возвращает количество элементов, существующих в коллекции, в виде целого значения.
При написании программ, которые являются многопоточными, возможно, что несколько потоков выполнения может получить доступ к коллекции одновременно. Если многие потоки считываются и записываются в коллекцию, могут возникнуть непредвиденные проблемы. Для облегчения этой проблемы коллекции могут быть синхронизированы. Синхронизированная коллекция позволяет писать из нескольких потоков.
Чтобы определить, синхронизирована ли коллекция, можно проверить свойство Boolean IsSynchronized. По умолчанию коллекции не синхронизируются.
ICollection.SyncRoot
Свойство SyncRoot возвращает объект, который может быть использован для синхронизации в целях потокобезопасности. Даже при синхронизации коллекции возникают ситуации, когда она не является потокобезопасной. Например, при циклическом переборе или перечислении элементов коллекции другой поток может изменять коллекцию. Это приводит к возникновению исключения. Чтобы гарантировать потоковую безопасность в этой ситуации, исключения могут быть перехвачены и обработаны, или коллекция может быть заблокирована с помощью объекта SyncRoot. В то время как заблокирован, никакие другие потоки не могут получить доступ к коллекции.
В следующем примере показано, как коллекция может быть заблокирована. Коллекция остается недоступной для других потоков до конца блока кода, связанного с оператором lock.
Интерфейс IList
Интерфейс IList объявляет свойства и методы коллекции, представляющей собой список пронумерованных элементов.свойства и методы: Каждый элемент в списке имеет индекс на основе нуля, который аналогичен индексу массива. Это не случайно, что массивы имеют такое поведение, поскольку они также реализуют интерфейс IList.
Члены интерфейса IList описаны ниже. Обратите внимание, что не все коллекции поддерживают каждое поведение. Если метод или свойство не поддерживается, вызывая его вызывает NotSupportedException . Интерфейс IList является производным от ICollection или наследует его. Это означает, что все коллекции, поддерживающие поведение IList, также реализуют ICollection.
Метод Add добавляет новый объект в коллекцию; объект для добавления передается в единственный параметр. Метод возвращает целочисленное значение, указывающее позицию индекса, в которую был вставлен новый объект. Помните, что индекс начинается с нуля, поэтому первая запись находится в нулевой позиции.
IList.Remove
Метод Remove удаляет объект из коллекции, используя сам объект в качестве параметра поиска. Если объект имеет несколько вхождений в списке, удаляется только первое совпадение. Если объект не существует в коллекции, операция ничего не сделает.
IList.Insert
Метод Insert аналогичен методу Add, так как он позволяет добавлять новые элементы в коллекцию. При вставке указывается индекс нового элемента. Объект вставляется в указанный индекс, а существующие объекты перемещаются в более высокий индекс, чтобы освободить место. Если указанный номер индекса слишком велик, создается исключение ArgumentOutOfRangeException.
Метод RemoveAt удаляет элемент из коллекции, используя номер индекса для идентификации объекта для удаления. Все элементы в коллекции с более высоким индексом перемещаются, чтобы гарантировать, что индексы остаются непрерывными.
Метод Clear является последним методом IList, используемым для изменения содержимого коллекции. Он удаляет все элементы из коллекции.
IList.Contains
Иногда необходимо определить, существует ли объект в коллекции. Метод Contains может быть использован для этой цели путем передачи объекта для поиска в качестве единственного параметра. Метод возвращает true, если элемент присутствует, и false в противном случае.
IList.IndexOf
Конечным методом интерфейса IList является IndexOf . Этот метод аналогичен методу Contains, так как он используется для определения наличия объекта в коллекции. Если объект существует, то возвращается его порядковый номер. Если объект не существует, возвращаемое значение равно -1.
IList.IsFixedSize Хотя большинство коллекций предоставляют динамическую группу элементов, можно иметь коллекции фиксированного размера. Коллекция фиксированного размера может быть изменена, но новые элементы не могут быть добавлены, а существующие элементы не могут быть удалены. Если какая-либо операция предпринята, создается исключение NotSupportedException. Чтобы проверить, является ли коллекция фиксированной по размеру, прочитайте свойство Boolean IsFixedSize.
IList.IsReadOnly
Еще одним шагом вперед по сравнению с коллекцией фиксированного размера является коллекция только для чтения. Такой список никоим образом не может быть изменен. Чтобы проверить, доступна ли коллекция только для чтения, прочитайте свойство IsReadOnly.
Примечание: коллекции фиксированного размера и только для чтения обычно являются оболочками для существующих коллекций, которые ограничивают доступ к записи. Если базовая коллекция изменена, ограниченная версия отражает изменения без выброса исключения.
Свойство Item предоставляет прямой доступ к любому объекту в коллекции с использованием номера индекса. Для указания номера индекса используются квадратные скобки, как и в массивах. В следующем примере создается и заполняется ArrayList с помощью метода Add. Значение одного из элементов коллекции затем считывается, изменяется и снова считывается номер индекса.
Примечание: это свойство называется индексатором для коллекции IList.
IDictionary Interface
Dictionary - это коллекция, содержащая связанные пары ключ-значение. Каждая запись в коллекции состоит из двух объектов. Первый, называемый ключом, является уникальным объектом, который идентифицирует запись в коллекции. Второй - это объект value. Это значение не обязательно должно быть уникальным.
Интерфейс IDictionary реализован во всех коллекциях справочников. Как и в случае с IList, IDictionary наследует ICollection, поэтому также поддерживает все поведение ICollection.
IDictionary.Add
Метод Add в IDictionary аналогичен методу IList.Метод add. Он используется для добавления нового элемента в словарь. Поскольку словари идентифицируются указанным ключом, а не номером индекса, значение не возвращается.
В следующих примерах поведения IDictionary используется класс Hashtable . Этот тип справочника предоставляет быстрый метод извлечения элементов из коллекции путем хэширования ключа в код, который используется в качестве индекса.
Метод Remove удаляет объект из справочника, используя уникальный ключ в качестве единственного параметра. Если ключ не существует в коллекции, операция не имеет эффекта.
IDictionary.Clear
Метод Clear удаляет все элементы из справочника. Этот метод аналогичен методу Clear интерфейса IList.
IDictionary.Contains
Метод Contains предоставляет аналогичные функциональные возможности для IList.Содержит. Он возвращает логическое значение, указывающее, существует ли определенный ключ в словаре.
В описании свойств интерфейса IList было объяснено, что коллекции могут иметь фиксированный размер или быть доступны только для чтения. Это верно для коллекций словарей, поэтому IDictionary предоставляет свойства IsFixedSize и IsReadOnly; оба возвращают логическое значение.
IDictionary.Item
Интерфейс IDictionary определяет свойство Item в качестве индексатора для классов словарей. Это позволяет идентифицировать отдельные элементы коллекции с помощью индекса, заключенного в квадратные скобки. В случае словарей используется ключевой объект, а не номер индекса.
IDictionary.Keys и IDictionary.Values
Словари можно рассматривать как два связанных набора: один набор ключей и один набор значений. Эта концепция может быть реализована путем извлечения любой группы как коллекции в своем собственном праве. Свойства ключей и значений предоставляют доступ к этим двум наборам значений, возвращая их в виде коллекции.
Возвращаемый тип коллекции не определен и может варьироваться в зависимости от опрашиваемого словаря. Однако возвращенные коллекции всегда будут наследовать интерфейс ICollection. Таким образом, возвращаемое значение может быть объявлено с помощью имени интерфейса ICollection, а базовый тип можно безопасно игнорировать.
В следующем примере оба эти свойства используются для циклического перебора каждого ключа и значения независимо.
Enumerators
В приведенных выше примерах команда foreach использовалась для циклического перебора элементов в коллекции. Это возможно, потому что интерфейс ICollection поддерживает интерфейс IEnumerable.
К списку вопросов по всем темам
Вопросы
1. Дайте определение понятию “коллекция”.
2. Назовите преимущества использования коллекций.
3. Какие данные могут хранить коллекции?
4. Какова иерархия коллекций?
5. Что вы знаете о коллекциях типа List?
6. Что вы знаете о коллекциях типа Set?
7. Что вы знаете о коллекциях типа Queue?
8. Что вы знаете о коллекциях типа Map, в чем их принципиальное отличие?
9. Назовите основные реализации List, Set, Map.
10. Какие реализации SortedSet вы знаете и в чем их особенность?
11. В чем отличия/сходства List и Set?
12. Что разного/общего у классов ArrayList и LinkedList, когда лучше использовать ArrayList, а когда LinkedList?
13. В каких случаях разумно использовать массив, а не ArrayList?
14. Чем отличается ArrayList от Vector?
15. Что вы знаете о реализации классов HashSet и TreeSet?
16. Чем отличаются HashMap и TreeMap? Как они устроены и работают? Что со временем доступа к объектам, какие зависимости?
17. Что такое Hashtable, чем она отличается от HashMap? На сегодняшний день она deprecated, как все-таки использовать нужную функциональность?
18. Что будет, если в Map положить два значения с одинаковым ключом?
19. Как задается порядок следования объектов в коллекции, как отсортировать коллекцию?
20. Дайте определение понятию “итератор”.
21. Какую функциональность представляет класс Collections?
22. Как получить не модифицируемую коллекцию?
23. Какие коллекции синхронизированы?
24. Как получить синхронизированную коллекцию из не синхронизированной?
25. Как получить коллекцию только для чтения?
26. Почему Map не наследуется от Collection?
27. В чем разница между Iterator и Enumeration?
28. Как реализован цикл foreach?
29. Почему нет метода iterator.add() чтобы добавить элементы в коллекцию?
30. Почему в классе iterator нет метода для получения следующего элемента без передвижения курсора?
31. В чем разница между Iterator и ListIterator?
32. Какие есть способы перебора всех элементов List?
33. В чем разница между fail-safe и fail-fast свойствами?
34. Что делать, чтобы не возникло исключение ConcurrentModificationException?
35. Что такое стек и очередь, расскажите в чем их отличия?
36. В чем разница между интерфейсами Comparable и Comparator?
37. Почему коллекции не наследуют интерфейсы Cloneable и Serializable?
Ответы
Тема коллекций невероятно обширная и для того, чтобы ответить на каждый вопрос глубоко нужна отдельная статья почти под каждый вопрос. При проработке этого раздела рекомендую прочитать дополнительный материал, указанный в ответах.
1. Дайте определение понятию “коллекция”.
Коллекциями/контейнерами в Java принято называть классы, основная цель которых – хранить набор других элементов.
2. Назовите преимущества использования коллекций.
Массивы обладают значительными недостатками. Одним из них является конечный размер массива, как следствие, необходимость следить за размером массива. Другим — индексная адресация, что не всегда удобно, т.к. ограничивает возможности добавления и удаления объектов. Чтобы избавиться от этих недостатков уже несколько десятилетий программисты используют рекурсивные типы данных, такие как списки и деревья. Стандартный набор коллекций Java служит для избавления программиста от необходимости самостоятельно реализовывать эти типы данных и снабжает его дополнительными возможностями.
3. Какие данные могут хранить коллекции?
Коллекции могут хранить любые ссылочные типы данных.
4. Какова иерархия коллекций?

Здесь следует обратить внимание, что interface Map не входит в иерархию interface Collection.
С Java 1.6 классы TreeSet и TreeMap имплементируют интерфейсы NavigableSet и NavigableMap, которые расширяют интерфейсы SortedSet и SortedMap соответственно (SortedSet и SortedMap расширяют Set и Map).
5. Что вы знаете о коллекциях типа List?
List — это упорядоченный список. Объекты хранятся в порядке их добавления в список. Доступ к элементам списка осуществляется по индексу.
6. Что вы знаете о коллекциях типа Set?
Set — множество неповторяющихся объектов. В коллекции этого типа разрешено наличие только одной ссылки типа null .
7. Что вы знаете о коллекциях типа Queue?
Queue — коллекция, предназначенная для хранения элементов в порядке, нужном для их обработки. В дополнение к базовым операциям интерфейса Collection, очередь предоставляет дополнительные операции вставки, получения и контроля.
Метод offer() вставляет элемент в очередь, если это не удалось — возвращает false . Этот метод отличается от метода add() интерфейса Collection тем, что метод add() может не выполнить добавление элемента только с использованием unchecked исключения.
Методы remove() и poll() удаляют верхушку очереди и возвращают ее. Какой элемент будет удален (первый или последний) зависит от реализации очереди. Методы remove() и poll() отличаются лишь поведением, когда очередь пустая: метод remove() генерирует исключение, а метод poll() возвращает null .
Методы element() и peek() возвращают (но не удаляют) верхушку очереди.
java.util.Queue реализует FIFO–буфер. Позволяет добавлять и получать объекты. При этом объекты могут быть получены в том порядке, в котором они были добавлены.
Реализации: java.util.ArrayDeque , java.util.LinkedList .
java.util.Deque наследует java.util.Queue . Двунаправленная очередь. Позволяет добавлять и удалять объекты с двух концов. Так же может быть использован в качестве стека.
Реализации: java.util.ArrayDeque , java.util.LinkedList .
8. Что вы знаете о коллекциях типа Map, в чем их принципиальное отличие?
Интерфейс java.util.Map используется для отображения каждого элемента из одного множества объектов (ключей) на другое (значений). При этом, каждому элементу из множества ключей ставится в соответствие множество значений. В то же время одному элементу из множества значений может соответствовать 1, 2 и более элементов из множества ключей. Интерфейс java.util.Map описывает функциональность ассоциативных массивов.
Реализации: java.util.HashMap , java.util.LinkedHashMap , java.util.TreeMap , java.util.WeakHashMap .
java.util.SortedMap наследует java.util.Map . Реализации этого интерфейса обеспечивают хранение элементов множества ключей в порядке возрастания (см. java.util.SortedSet). Реализации: java.util.TreeMap .
9. Назовите основные реализации List, Set, Map.
| Интерфейс | Класс/Реализация | Описание |
|---|---|---|
| List | ArrayList | Список |
| LinkedList | Список | |
| Vector | Вектор | |
| Stack | Стек | |
| Set | HashSet | Множество |
| TreeSet | Множество | |
| SortedSet (расширяющий интерфейс) | Отсортированное множество | |
| Map | HashMap | Карта/Словарь |
| TreeMap | Карта/Словарь | |
| SortedMap (расширяющий интерфейс) | Отсортированный словарь | |
| Hashtable | Хеш-таблица |
10. Какие реализации SortedSet вы знаете и в чем их особенность?
Реализации: java.util.TreeSet — коллекция, которая хранит свои элементы в виде упорядоченного по значениям дерева. TreeSet инкапсулирует в себе TreeMap, который в свою очередь использует сбалансированное бинарное красно-черное дерево для хранения элементов. TreeSet хорош тем, что для операций add, remove и contains потребуется гарантированное время log(n).
11. В чем отличия/сходства List и Set?
Оба унаследованы от Collection , а значит имеют одинаковый набор и сигнатуры методов. List хранит объекты в порядке вставки, элемент можно получить по индексу. Set не может хранить одинаковых элементов.
12. Что разного/общего у классов ArrayList и LinkedList, когда лучше использовать ArrayList, а когда LinkedList?
ArrayList реализован внутри в виде обычного массива . Поэтому при вставке элемента в середину, приходится сначала сдвигать на один все элементы после него, а уже затем в освободившееся место вставлять новый элемент. Зато в нем быстро реализованы взятие и изменение элемента – операции get, set , так как в них мы просто обращаемся к соответствующему элементу массива.
LinkedList реализован внутри по-другому. Он реализован в виде связного списка : набора отдельных элементов, каждый из которых хранит ссылку на следующий и предыдущий элементы. Чтобы вставить элемент в середину такого списка, достаточно поменять ссылки его будущих соседей. А вот чтобы получить элемент с номером 130, нужно пройтись последовательно по всем объектам от 0 до 130. Другими словами операции set и get тут реализованы очень медленно . Посмотри на таблицу:
| Описание | Операция | ArrayList | LinkedList |
|---|---|---|---|
| Взятие элемента | get | Быстро | Медленно |
| Присваивание элемента | set | Быстро | Медленно |
| Добавление элемента | add | Быстро | Быстро |
| Вставка элемента | add(i, value) | Медленно | Быстро |
| Удаление элемента | remove | Медленно | Быстро |
Если необходимо вставлять (или удалять) в середину коллекции много элементов, то лучше использовать LinkedList. Во всех остальных случаях – ArrayList.
LinkedList требует больше памяти для хранения такого же количества элементов, потому что кроме самого элемента хранятся еще указатели на следующий и предыдущий элементы списка, тогда как в ArrayList элементы просто идут по порядку
13. В каких случаях разумно использовать массив, а не ArrayList?
Если коротко, то Oracle пишет — используйте ArrayList вместо массивов. Если ответить на этот вопрос нужно по-другому, то можно сказать следующее: массивы могут быть быстрее и кушать меньше памяти. Списки теряют в производительности из-за возможности автоматического увеличения размера и сопутствующих проверок. Плюс к этому, что размер списка увеличивается не на 1, а на большее кол-во элементов (+15)*. Так же доступ к [10] в массиве может быть быстрее чем вызов get(10) у списка.
14. Чем отличается ArrayList от Vector?
Vector deprecated. У Vector некоторые методы синхронизированы и поэтому они медленные. В любом случае Vector не рекомендуется использовать вообще.
15. Что вы знаете о реализации классов HashSet и TreeSet?
Название Hash… происходит от понятия хэш-функция. Хэш-функция — это функция, сужающая множество значений объекта до некоторого подмножества целых чисел. Класс Object имеет метод hashCode() , который используется классом HashSet для эффективного размещения объектов, заносимых в коллекцию. В классах объектов, заносимых в HashSet , этот метод должен быть переопределен (override).
HashSet реализован на основе хеш-таблицы, а TreeSet — на основе бинарного дерева.
HashSet гораздо быстрее чем TreeSet (константное время против логарифмического для большинства операций, таких как add , remove , contains ), но TreeSet гарантирует упорядоченность объектов. Оба не синхронизированы.
- время для базовых операций add() , remove() , contains() — log(n)
- гарантирует порядок элементов
- не предоставляет каких-либо параметров для настройки производительности
- предоставляет дополнительные методы для упорядоченного списка: first() , last() , headSet() , tailSet() и т.д.
16. Чем отличаются HashMap и TreeMap? Как они устроены и работают? Что со временем доступа к объектам, какие зависимости?
В целом ответ про HashSet и TreeSet подходит и к этому вопросу.
HashMap работает строго быстрее TreeMap .
TreeMap реализован на красно-черном дереве, время добавления/поиска/удаления элемента — O(log N), где N — число элементов в TreeMap на данный момент.
У HashMap время доступа к отдельному элементу — O(1) при условии, что хэш-функция ( Object.hashCode() ) определена нормально (что является правдой в случае Integer ).
Общая рекомендация — если не нужна упорядоченность, использовать HashMap . Исключение — ситуация с вещественными числами, которые в качестве ключей почти всегда очень плохи. Для них нужно использовать TreeMap , предварительно поставив ему компаратор, который сравнивает вещественные числа так, как это нужно в данной задаче. Например, для обычных геометрических задач два вещественных числа могут считаться равными, если отличаются не более, чем на 1e-9.
17. Что такое Hashtable, чем она отличается от HashMap? На сегодняшний день она deprecated, как все-таки использовать нужную функциональность?
Некоторые методы HashTable синхронизированы, поэтому она медленнее HashMap .
- HashTable синхронизирована, а HashMap нет.
- HashTable не позволяет иметь null ключи или значения. HashMap позволяет иметь один null ключ и сколько угодно null значений.
- У HashMap есть подкласс LinkedHashMap , который добавляет возможности по итерации. Если вам нужна эта функциональность, то можно легко переключаться между классами.
Общее замечание — не рекомендуется использовать HashTable даже в многопоточных приложениях. Для этого есть ConcurrentHashMap .
18. Что будет, если в Map положить два значения с одинаковым ключом?
Последнее значение перезапишет предыдущее.
19. Как задается порядок следования объектов в коллекции, как отсортировать коллекцию?
Класс ТгееМар полностью реализует интерфейс SortedMap . Он реализован как бинарное дерево поиска, значит его элементы хранятся в упорядоченном виде. Это значительно ускоряет поиск нужного элемента. Порядок задается либо естественным следованием элементов, либо объектом, реализующим интерфейс сравнения Comparator .
В этом классе четыре конструктора:
ТгееМар() — создает пустой объект с естественным порядком элементов;
TreeМар(Comparator с) — создает пустой объект, в котором порядок задается объектом сравнения с;
ТгееМар(Map f) — создает объект, содержащий все элементы отображения f, с естественным порядком его элементов;
ТгееМар(SortedMap sf) — создает объект, содержащий все элементы отображения sf, в том же порядке.
Интерфейс Comparator описывает два метода сравнения:
int compare(Object obj1, object obj2) — возвращает отрицательное число, если obj1 в каком-то смысле меньше obj2 ; нуль, если они считаются равными; положительное число, если obj1 больше obj2 . Для читателей, знакомых с теорией множеств, скажем, что этот метод сравнения обладает свойствами тождества, антисимметричности и транзитивности;
boolean equals(Object obj) — сравнивает данный объект с объектом obj , возвращая true , если объекты совпадают в каком-либо смысле, заданном этим методом.
Для каждой коллекции можно реализовать эти два метода, задав конкретный способ сравнения элементов, и определить объект класса SortedMap вторым конструктором. Элементы коллекции будут автоматически отсортированы в заданном порядке.
Читайте также:
- Норма этой системы права носит казуистический характер так как она модель конкретного решения
- Какую направленность имеет российская правовая модель социального предпринимательства тест
- Принцип законности в деятельности государственных органов означает что
- У осетинцев какой паспорт
- Как на гранте отрегулировать фары лево право