Для чего необходим прямой доступ к памяти для обеспечения
Обновлено: 12.05.2024
В МПС используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно управляемая передача и прямой доступ к памяти ПДП ( Direct Memory Access - DMA ).
Программно управляемая передача данных осуществляется при непосредственном участии и под управлением процессора. Например, при пересылке блока данных из внешнего устройства в оперативную память процессор должен выполнить следующую последовательность шагов:
- сформировать начальный адрес области обмена ОП;
- занести длину передаваемого массива данных в один из своих внутренних регистров, который будет играть роль счетчика;
- выдать команду чтения информации из ВУ; при этом на шину адреса из МП выдается адрес ВУ, на шину управления - сигнал чтения данных из ВУ, а считанные данные заносятся во внутренний регистр МП;
- выдать команду записи информации в ОП; при этом на шину адреса из МП выдается адрес ячейки оперативной памяти, на шину управления - сигнал записи данных в ОП, а на шину данных выставляются данные из регистра МП, в который они были помещены при чтении из ВУ;
- модифицировать регистр, содержащий адрес оперативной памяти;
- уменьшить счетчик длины массива на длину переданных данных;
- если переданы не все данные, то повторить шаги 3-6, в противном случае закончить обмен.
Как мы видим, программно управляемый обмен ведет к нерациональному использованию мощности микропроцессора, который вынужден выполнять большое количество относительно простых операций, приостанавливая работу над основной программой. При этом действия, связанные с обращением к оперативной памяти и к внешнему устройству, обычно требуют удлиненного цикла работы микропроцессора, что приводит к еще более существенным потерям производительности.
Альтернативой программно управляемому обмену служит прямой доступ к памяти - способ быстродействующего подключения внешнего устройства, при котором оно обращается к оперативной памяти, не прерывая работы процессора. Такой обмен происходит под управлением отдельного устройства - контроллера прямого доступа к памяти (КПДП).
Схема включения КПДП в состав микропроцессорной системы представлена на рис. 8.4.

Перед началом работы контроллер ПДП необходимо инициализировать: занести начальный адрес области ОП, с которой производится обмен, и длину передаваемого массива данных. В дальнейшем по сигналу запроса прямого доступа контроллер фактически выполняет все те действия, которые обеспечивал микропроцессор при программно управляемой передаче.
Последовательность действий КПДП при запросе на прямой доступ к памяти со стороны внешнего устройства следующая:
- Принять запрос на ПДП (сигнал DRQ ) от ВУ.
- Сформировать запрос к МП на захват шин (сигнал HRQ ).
- Принять сигнал от МП ( HLDA ), подтверждающий факт перевода микропроцессором своих шин в третье состояние.
- Сформировать сигнал, сообщающий устройству ввода-вывода о начале выполнения циклов прямого доступа к памяти ( DACK ).
- Сформировать на шине адреса компьютера адрес ячейки памяти, предназначенной для обмена.
- Выработать сигналы, обеспечивающие управление обменом ( IOR , MW для передачи данных из ВУ в оперативную память и IOW , MR для передачи данных из оперативной памяти в ВУ).
- Уменьшить значение в счетчике данных на длину переданных данных.
- Проверить условие окончания сеанса прямого доступа (обнуление счетчика данных или снятие сигнала запроса на ПДП ). Если условие окончания не выполнено, то изменить адрес в регистре текущего адреса на длину переданных данных и повторить шаги 5-8.
Прямой доступ к памяти позволяет осуществлять обмен данными между внешним устройством и оперативной памятью параллельно с выполнением процессором программы.
Структура КПДП представлена на рис. 8.5.
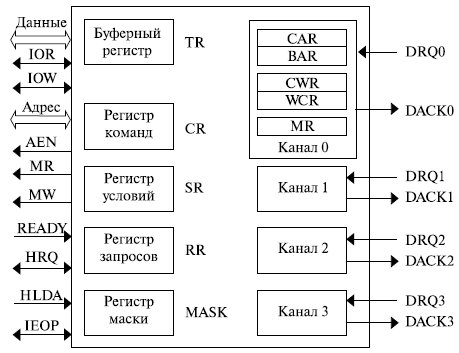
Контроллер состоит из 4 идентичных каналов, позволяющих подключить к системе до четырех устройств, работающих в режиме ПДП .
В состав каждого канала входят следующие регистры:
- MR ( Mode Register ) - регистр режима. Определяет следующие параметры передачи:
- порядок изменения (увеличения или уменьшения) адреса ОП при передаче;
- возможность автоинициализации;
- режим обслуживания:
- одиночная передача (контроллер возвращает магистраль процессору после каждого цикла ПДП );
- блочная передача (контроллер владеет магистралью в течение передачи всего массива);
- по требованию (окончание передачи определяется снятием сигнала DRQ или подачей сигнала IEOP на внешний вход КПДП);
- каскадирование;
Значения в регистрах BAR и WCR устанавливаются при инициализации и в ходе циклов ПДП не меняются. В регистры CAR и CWR в начале выполнения ПДП заносятся значения из регистров BAR и WCR соответственно. При выполнении ПДП эти регистры изменяются.
Управляющие регистры, общие для всего контроллера:
- CR ( Command Register ) - регистр команд - определяет:
- режим память-память или обычный. В режиме память-память осуществляется обмен по схеме ПДП между двумя областями ОП (только для каналов 0 и 1) с использованием буферного регистра TR ( Temporary Register );
- запрет/разрешение ПДП ;
- порядок изменения приоритетов каналов:
- фиксированный приоритет;
- циклическое изменение приоритета после обработки запроса на ПДП по одному из каналов;
- явное указание наиболее приоритетного канала;
- уровень сигналов DRQ и DACK (настройка на активный уровень сигналов под особенности работы внешних устройств);
Во избежание ложных срабатываний внешних устройств, не использующих в данный момент режим прямого доступа, контроллер ПДП во время режима ПДП вырабатывает сигнал AEN , который блокирует работу остальных внешних устройств:
![AEN=\begin</p>
<p>\mbox\\ \mbox \end]()
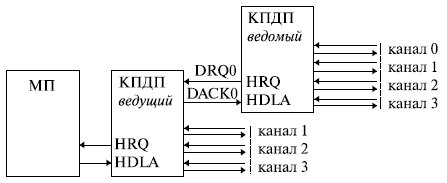
Для увеличения количества внешних устройств, которые могут быть подключены к микропроцессору в режиме ПДП , используется каскадное включение КПДП (рис. 8.6).
При этом ведомый КПДП подключается к одному из каналов ведущего контроллера по схеме подключения внешнего устройства, а непосредственно с микропроцессором связывается только ведущий контроллер . В стандартной конфигурации персональной ЭВМ применяются два КПДП (ведущий и ведомый), которые позволяют подключить до 7 внешних устройств, причем 2 канала закреплены за накопителями на жестком и гибком
![Каскадное включение контроллеров прямого доступа к памяти]()
дисках. В максимальной конфигурации при использовании ведущего и 4 ведомых КПДП, подключенных к каждому из каналов ведущего, к МП можно подключить до 16 внешних устройств, работающих в режиме ПДП .
Прямой доступ к памяти (ПДП) является одним из способов обмена данными с ПУ. В этом режиме обмен данными между ПУ и памятью микропроцессорной системы происходит без участия процессора. Обменом в режиме ПДП управляет не программа, выполняемая процессором, а внешнее по отношению к процессору специальное устройство, называемое контроллером ПДП (КПДП). ПДП используется для быстрого ввода/вывода блоков данных и разгрузки процессора от управления операциями ввода/вывода. Обмен блоками данных с помощью программно-управляемого обмена осуществляется относительно медленно, так как на обмен каждым байтом затрачивается несколько команд процессора. ПДП освобождает процессор от управления операциями ввода/вывода, позволяя тем самым осуществлять параллельно во времени выполнение процессором программы с обменом данными между ПУ и памятью, производить этот обмен со скоростью, ограниченной только пропускной способностью памяти или ПУ. Таким образом, ПДП, разгружая процессор от обслуживания операций ввода/вывода, способствует возрастанию общей производительности микропроцессорной системы.
Для реализации режима ПДП необходимо обеспечить непосредственную связь контроллера ПДП и памяти микропроцессорной системы, т.е. специальный информационный канал, по которому осуществляется обмен в режиме ПДП, – канал ПДП. Для этой цели можно использовать специально выделенную магистраль, связывающую контроллер ПДП с памятью. Однако такое решение нельзя признать оптимальным, так как это приведет к значительному усложнению микропроцессорной системы в целом, особенно при подключении нескольких ПУ. С целью сокращения количества линий в шинах микропроцессорной системы контроллер ПДП подключается к памяти посредством шин системной магистрали. При этом возникает проблема совместного использования шин системной магистрали процессором и контроллером ПДП. Можно выделить два основных способа ее решения:
- реализация обмена в режиме ПДП с захватом цикла;
- реализация обмена в режиме ПДП с блокировкой процессора.
Существует две разновидности прямого доступа к памяти с захватом цикла. Наиболее простой способ организации ПДП состоит в том, что для обмена используются те циклы процессора, в которых он не обменивается данными с памятью. В такие циклы контроллер ПДП может обмениваться данными с памятью, не мешая работе процессора. Однако возникает необходимость выделения таких циклов, чтобы не произошло временного перекрытия обмена ПДП с операциями обмена, инициируемыми процессором. В некоторых процессорах формируется специальный управляющий сигнал, указывающий циклы, в которых процессор не использует память. Если процессор не формирует такого сигнала, то для выделения свободных циклов необходимо применение в контроллере ПДП специальной схемы, что приводит к усложнению последнего. Применение этого способа организации ПДП не снижает производительности системы, но при этом обмен в режиме ПДП возможен только в случайные моменты времени одиночными словами.
Управляющий сигнал HOLD формируется контроллером ПДП. Процессор, получив этот сигнал, приостанавливает выполнение текущей команды, не дожидаясь ее завершения, отключается от шин системной магистрали и выдает контроллеру ПДП управляющий сигнал HLDA. С этого момента все шины системной магистрали управляются контроллером ПДП. Контроллер ПДП, используя шины системной магистрали, осуществляет обмен одним словом данных с памятью и затем, сняв сигнал HOLD, возвращает управление системной магистралью процессору. Как только контроллер ПДП будет готов к обмену следующим словом данных, он вновь захватывает цикл процессора и т.д. В промежутках между захватами циклов контроллером ПДП процессор продолжает выполнять команды программы. Тем самым выполнение программы замедляется, но значительно в меньшей степени, чем при обмене в режиме прерывания.
Передача блока данных с использованием ПДП предполагает выполнение определенной последовательности действий (рис. 32):
1) начальная установка (предварительная подготовка) контроллера ПДП;
2) запуск контроллера ПДП;
3) многократное занятие цикла процессора;
4) завершение обмена.
Рис. 32 – Алгоритм передачи блока данных с использованием контроллера ПДП
Программа используется только для начальной установки и пуска обмена через канал ПДП. После этого процессор может выполнять основную программу, которая не связана с обменом. Во время выполнения этой программы каждый раз при поступлении запроса на ПДП контроллер ПДП будет занимать цикл процессора, и осуществлять передачу. После окончания обмена для передачи управления программе завершения обмена в режиме ПДП используется прерывание. Затем основная программа может быть продолжена.
Рассмотрим организацию контроллера ПДП, обеспечивающего ввод данных в память микропроцессорной системы в режиме ПДП (рис. 33).
Рис. 33 – Организация контроллера ПДП
Начальная подготовка к обмену в режиме ПДП состоит в выделении ПУ области памяти, используемой при обмене, и указании ее размера, т.е. количества записываемых в память или читаемых из памяти слов информации. Следовательно, контроллер ПДП должен иметь в своем составе регистр адреса и счетчик слов. Перед началом обмена с ПУ в режиме ПДП процессор должен выполнить программу загрузки, которая обеспечивает запись в указанные регистры контроллера ПДП начального адреса выделенной ПУ памяти и ее размера в словах заданной разрядности.
Таким образом, перед началом ввода из ПУ очередного блока данных процессор загружает в регистры контроллера ПДП следующую информацию: в счетчик слов – количество принимаемых слов, а в регистр адреса – начальный адрес области памяти для вводимых данных. Тем самым контроллер подготавливается к выполнению операции ввода данных из ПУ в память в режиме ПДП.
Запуск контроллера ПДП осуществляется командой вывода, по которой устанавливается в 1 триггер пуска. Триггер пуска подключает ПУ к контроллеру ПДП. После команды пуска контроллера ПДП должна быть команда разрешения прерывания. В дальнейшем ввод блока данных через канал ПДП осуществляется без участия команд программы.
- сброса триггера запроса;
- увеличения содержимого регистра адреса на 1;
- уменьшения содержимого счетчика слов на 1.
По каждому сигналу HLDA из содержимого счетчика слов вычитается 1, и когда оно становится равным 0, устанавливается в 1 триггер окончания передачи блока данных, сигнал с выхода которого используется в качестве запроса на прерывание и поступает на соответствующий вход процессора. Процессор прерывает выполнение программы и передает управление подпрограмме обработки прерывания для завершения обмена.
Завершение обмена осуществляется путем отключения ПУ от контроллера ПДП командой вывода, по которой сбрасывается в 0 триггер пуска. Кроме того, аналогичным образом сбрасывается в 0 триггер окончания передачи блока данных. По окончании обработки прерывания управление возвращается основной программе.
Если нет необходимости продолжать выполнение некоторой программы параллельно с передачей в режиме ПДП, используется в качестве сигнала готовности, который доступен процессору через регистр состояния контроллера ПДП. В этом случае прерывание не используется (выход триггера окончания передачи не подключается к входу запроса на прерывание процессора или прерывание в процессоре запрещается). В течение обмена через канал ПДП процессор находится в цикле ожидания окончания передачи, опрашивая соответствующий разряд готовности регистра состояния контроллера ПДП по команде ввода. Как только процессор обнаружит готовность, он переходит к процедуре завершения обмена (шаг 4 рассмотренной выше последовательности), после чего выполнение программы продолжается.
Выше были рассмотрены только процесс подготовки контроллера ПДП и непосредственно передача данных в режиме ПДП. На практике любой сеанс обмена данными с ПУ в режиме ПДП всегда включает также и этап подготовки ПУ к обмену. На этом этапе процессор в режиме программно-управляемого обмена опрашивает состояние ПУ, проверяя его готовность к обмену, и посылает в ПУ команды, обеспечивающие его подготовку к обмену данными по каналу ПДП. Такая подготовка может сводиться, например, к перемещению головок на требуемую дорожку в НМД. Затем выполняется загрузка регистров контроллера ПДП, после чего обмен данными в режиме ПДП начинается либо по инициативе контроллера ПДП, как это было рассмотрено выше, либо по инициативе ПУ.
Следует отметить, что использование в микропроцессорной системе обмена в режиме ПДП с захватом цикла требует от программиста очень ясного понимания процессов, происходящих в системе при выполнении программы, и четкой синхронизации процесса выполнения программы и ввода /вывода по каналу ПДП.
Принцип работы RDMA (удаленный прямой доступ к памяти) графическое подробное объяснение + сравнение с традиционным режимом связи
Каталог статей
Прочтите руководство: Эта статья длинная, пожалуйста, прочтите ее внимательно, и вы можете пропустить раздел 3.1. Если у вас есть понимание концепций RDMA, вы можете начать читать прямо с раздела 3.2.
1 Традиционный режим связи
Приложения, использующие протокол TCP / IP, обычно используют интерфейс прикладного программирования: UNIX BSD socket (сокет) для обеспечения связи между сетевыми процессами. На данный момент почти все приложения используют сокеты.Независимо от того, написана ли программа-клиент или программа-сервер, система должна создавать дескриптор сокета для каждого TCP-соединения. Это приводит к управлению ОС и стеком протоколов для каждой передачи данных.Следовательно, будь то синхронная связь через Socket или асинхронная связь, будет явление чрезмерной загрузки ЦП.
1.1 Традиционный сетевой процесс коммуникации
![]()
Видно, что традиционный режим связи вызовет повторное копирование данных, переключение контекста и обработку ЦП.
2 Основные принципы и преимущества RDMA
2.1 Основные принципы
RDMA - это новая технология прямого доступа к памяти. RDMA позволяет компьютеру напрямую обращаться к памяти других компьютеров без обработки процессором. RDMA быстро перемещает данные из одной системы в память удаленной системы, не затрагивая операционную систему.
RDMA:
Удаленный: данные передаются между сетью и удаленным компьютером.Прямой: без участия ядра весь контент, связанный с отправкой и передачей, выгружается на сетевую карту.
Память: прямая передача данных между виртуальной памятью в пользовательском пространстве и сетевой картой RNIC не требует использования ядра системы, и нет никакого дополнительного перемещения и копирования данных.
Доступ: отправка, получение, чтение, запись, атомарные операции
Видно, что традиционный метод должен проходить через пользовательский режим -> ядро -> оборудование.
RDMA напрямую проходит только через пользовательский режим, а доступ к данным напрямую управляется оборудованием RDMA.Преимущества использования RDMA следующие:
3 Подробное объяснение принципа RDMA
3.1 Сетевой протокол, поддерживающий RDMA
В настоящее время существует три основных сетевых протокола, поддерживающих RDMA.
iWARP(RDMA over TCP/IP)Используйте зрелую IP-сеть; наследуйте преимущества RDMA; стоимость аппаратной реализации TCP / IP высока, но если будет принята стратегия потери пакетов традиционной IP-сети, производительность будет значительно снижена.
** RDMA over Converged Ethernet (RoCE) ** - это сетевой протокол, который позволяет приложениям реализовывать удаленный доступ к памяти через Ethernet. В настоящее время существует две версии протокола RoCE.
RoCE v1Это протокол канального уровня, который обеспечивает прямой доступ любым двум хостам в одном и том же широковещательном домене.
RoCE v2Это протокол уровня Интернета, который может реализовывать функции маршрутизации. Хотя эти преимущества протокола RoCE основаны на характеристиках конвергентного Ethernet, протокол RoCE также может использоваться в традиционных сетях Ethernet или неконвергентных сетях Ethernet.
RoCE и InfiniBand, один определяет, как запускать RDMA в Ethernet, а другой определяет, как запускать RDMA в сетях IB (в основном, кластерные приложения)
RoCE и iWARP, один основан на протоколе UDP без установления соединения, другой - на протоколе с установлением соединения (например, TCP).![]()
В настоящее время, хотя три технологии RDMA: IB, Ethernet RoCE и Ethernet iWARP используют единый API, они имеют разные физические и канальные уровни. В решении Ethernet RoCE имеет очевидные преимущества перед iWARP, которые отражаются в задержке, пропускной способности и загрузке процессора. RoCE поддерживается многими основными решениями и включен в служебное программное обеспечение Windows.
3.2 Основные концепции
Организация под названием OpenFabric Alliance) предоставляет серию API-интерфейсов Verbs для передачи RDMA, разрабатывает стек протоколов OFED (Open Fabric Enterprise Distribution) и поддерживает несколько протоколов уровня передачи RDMA.
Уровень программного транспортного интерфейса (Software Transport Interface) между приложением RDMA и RNIC (контроллер сетевого интерфейса с поддержкой RDMA) называется Verbs или RDMA API.
RDMA API (глаголы) в основном имеет два вида глаголов:
Глаголы памяти (Memory Verbs), также называемые One-SidedRDMA. Включая чтение RDMA, запись RDMA, атомарный RDMA. Доступ к RDMA в этом режиме вообще не требует подтверждения от удаленного компьютера.
3.2.1 Основные понятия
- Во время процесса передачи данных прикладная программа не может изменять память, в которой находятся данные.
- Операционная система не может выгружать страницу памяти, в которой расположены данные - соответствие между физическим адресом и виртуальным адресом должно быть исправлено.
2. Очереди | Очередь
RDMA поддерживает всего три очереди, очередь отправки (SQ) и очередь приема (RQ), а также полную очередь (CQ). Среди них SQ и RQ обычно создаются парами и называются парами очередей (QP).4. Операция чтения / записи
Операции чтения RDMA по сути являются операциями извлечения, Вытяните данные из удаленной системной памяти обратно в локальную системную память.
- Получатель должен предоставить виртуальный адрес и remote_key целевой памяти хранилища.
- Получатель должен инициировать и принять уведомление с напоминанием, отправитель полностью пассивен и не принимает никаких уведомлений
Операция записи RDMA - это, по сути, операция Push, Переместите данные из памяти локальной системы в память удаленной системы.
- Отправитель должен предоставить виртуальный адрес и remote_key, чтобы цель могла прочитать память.
- Отправителю необходимо инициировать и принять уведомление с напоминанием, получатель полностью пассивен и не будет принимать никаких уведомлений.
3.2.2 Рабочий процесс RDMA
Чтобы использовать RDMA, сначала установите путь данных от RDMA к памяти приложения. Эти пути данных могут быть установлены через собственный интерфейс интерфейса команд RDMA.Как только путь данных установлен, можно получить прямой доступ к буферу пользовательского пространства.
Рабочий процесс RDMA выглядит следующим образом:
Более подробное описание процесса:
Двусторонняя операция RDMA (отправка / получение)
Например, для двусторонних операций процесс отправки данных из A в B выглядит следующим образом:
Во-первых, A и B должны создать и инициализировать свои соответствующие QP, CQ.
A и B соответственно регистрируют WQE в своем WQ. Для A, WQ = SQ, и описание WQE указывает на часть данных, ожидающих отправки; для B, WQ = RQ, описание WQE указывает на буфер для хранения данных.
Односторонняя операция RDAM (читать)
Для односторонних операций возьмите в качестве примера операцию чтения от B до A, поток данных выглядит следующим образом:
Односторонний режим передачи данных является самым большим отличием RDMA от традиционной сетевой передачи.Он требует только прямого доступа к удаленному виртуальному адресу без участия удаленных приложений.Этот метод подходит для массовой передачи данных.。
Примечание: уровень автора ограничен, пожалуйста, поправьте меня, если есть ошибка
Прямой доступ к памяти (DMA) - это метод непосредственного обращения к памяти, минуя процессор. Процессор отвечает только за программирование DMA: настройку на определенный тип передачи, задание начального адреса и размера массива обмениваемых данных. Обычно DMA используется для обмена массивами данных между системной памятью и устройствами ввода-вывода. Он применяется в тех случаях, когда нужно перенести большой блок информации из одной области памяти в другую. Либо байт за байтом выдать блок информации на один из портов ввода/вывода. Либо наоборот, получить блок информации байт за байтом из порта ввода/вывода, и записать его в какую ни, будь область памяти. Под блоком информации естественно подразумевается некую последовательность байтов, хранящуюся в памяти в смежных ячейках (например, с адреса ADDR1 по адрес ADDR2). Хороший пример такой задачи – вывод текста на печать.
57. Сетевое оборудование
Профессиональное сетевое оборудование
Прежде чем приступить к выбору современного электрооборудования для своего предприятия, офиса или дома нужно построить структуру сетевых коммуникаций помещения. Возможности современной системной интеграции предоставляют огромный выбор сетевого оборудования, начиная от организации простых локально-вычислительных сетей, и заканчивая построением полнофункциональных решений на базе СКС и систем умный дом.
При выборе сетевого оборудования необходимо учесть несколько параметров. Понятно, что важное значение имеют технические характеристики (производительность, организация сетевых настроек, системы защиты информации и т.д.). Не менее важно определить стоимость. Это не только начальные вложения (стоимость оборудования), но и стоимость владения. Для оборудования первого уровня она равна нулю, поскольку сами устройства очень просты. Эксплуатация решений второго и третьего уровня требует помощи квалифицированных специалистов, без чего оборудование невозможно использовать в полной мере.
58. Персональные эвм
В настоящее время ПЭВМ являются самым массовым типом. Именно им отводится решающая роль при переходе общества к информатизации - наиболее полному использованию информационных технологий.
С появлением персональных ЭВМ наметился новый этап в организации и обеспечении вычислений - этап “персональных вычислений”. Суть его выражается девизом “One man - one job - one computer“ (человек - работа -компьютер). Таким образом, персональные ЭВМ призваны решать в первую очередь те задачи, которые возникают у специалистов различного профиля в определенные моменты времени, непосредственно на рабочих местах, т.е. там, где находятся источники данных, подлежащие обработке.
При этом самым распространенным режимом работы является режим непосредственного доступа к ресурсам ЭВМ, “один на один с компьютером”. Подобный режим работы уже использовался при работе с первыми ЭВМ, однако при централизованном управлении он был крайне неэффективен (см. п. 9.5.). Если ранее за пультом большой ЭВМ должен был находиться профессиональный программист, то за персональным компьютером обычно находится “непрограммирующий профессионал”. Так обычно называют специалиста конкретной предметной области (бухгалтера, экономиста, инженера-исследователя и т.п.), но не специалиста в вычислительной технике и программировании. Поэтому возврат к режиму непосредственного доступа происходит на качественно новой основе.
При широком применении ПЭВМ в различных сферах деятельности человека выдвигаются требования к их надлежащему программному обеспечению. В настоящее время число профессиональных программистов в индустриально развитых странах составляет не более 0,5% населения. Фирмы - разработчики программного обеспечения не могут обеспечить каждого пользователя ПЭВМ требуемым набором программ. Их усилия сосредоточены на производстве пакетов прикладных программ и систем программирования, рассчитанных на массового пользователя. Именно поэтому такой взрывной характер имеют спрос, производство и распространение подобных пакетов. Они составляют фундамент для последующей разработки собственных программ пользователя, учитывающих всю специфику требуемых вычислений, т.е., как и во всех науках, специализация является надстройкой унификации. Это позволяет пользователям - специалистам с невысокой математической, вычислительной и программистской подготовкой необязательно самыми эффективными средствами и способами ставить и решать задачи специальной обработки данных.
Основная цель использования ПЭВМ - формализация профессиональных знаний. Здесь, в первую очередь, автоматизируется рутинная часть работ специалистов, которая занимает более 75% их рабочего времени. Применение ПЭВМ позволяет сделать труд специалистов более творческим, интересным, эффективным. Персональные ЭВМ используются повсеместно, во всех сферах деятельности людей. Новые сферы применения изменили и характер вычислительных работ. Так, инженерно-технические расчеты составляют не более 9%, автоматизация управления сбытом, закупками, управление запасом - 16%, финансово-экономические расчеты -15%, делопроизводство - более 10%, игровые задачи - 8% и т.д.
Читайте также: