
Что называется глубиной рекурсии текущим уровнем рекурсии рекурсивным спуском и возвратом
Обновлено: 02.07.2024
При первом знакомстве с концепцией рекурсии, она может показаться странной и отталкивающей. Это кажется почти парадоксальным: как мы можем найти решение проблемы, используя решение той же проблемы? Несмотря на это, в большинстве проектов, рекурсию используют в программировании уже на ранних стадиях производства.
Я думаю, что тем, кто пытается постигнуть концепцию рекурсии, следует сначала понять, что рекурсия — это больше, чем просто практика в программировании. Это философия решения проблем, которые можно решать частями, не трогая основную часть проблемы, при этом, проблема упрощается или становится меньше. Рекурсия применима не только в программировании, но и в простых повседневных задачах. Например, возьмите меня, пишущего эту статью: допустим, я хочу написать около 1000 слов, и ставлю цель писать 100 слов каждый раз, когда сажусь за работу. Получается, что в первый раз я напишу 100 слов и оставляю 900 слов на потом. В следующий раз я напишу ещё 100 слов, а оставлю 800. Я буду продолжать, пока не останется 0 слов. Каждый раз, я частично решаю проблему, а оставшаяся часть проблемы уменьшается.
Работу над статьей можно представить в виде такого кода:
Также, этот алгоритм можно реализовать итеративно:
Если рассматривать вызов функции write_words(1000) в любой из этих реализаций, вы обнаружите, одинаковое поведение. На самом деле, каждую задачу, которую можно решить с помощью рекурсии, мы также можем решить с помощью итерации (циклы forи while). Так почему же стоит использовать именно рекурсию?
Почему рекурсия?
Суть рекурсии
Предположим, у нас есть фактические данные определённого типа, назовём их dₒ. Идея рекурсии состоит в том, чтобы предположить, что мы уже решили задачу или вычислили желаемую функцию f для всех форм этого типа данных. Каждая из этих форм проще общей сложности dₒ, которую нам нужно определить. Следовательно, если мы можем найти способ выражения f(dₒ) , исходя из одной или нескольких частей f(d) , где все эти d проще, чем dₒ , значит мы нашли решение для f(dₒ) . Мы повторяем этот процесс, и рассчитываем, что в какой-то момент оставшиеся f(d) станут настолько простыми, что мы сможем легко реализовать фиксированное, окончательное решение для них. В итоге, решением исходной задачи станет поэтапное решение более простых задач.
В приведённом выше примере (про написание статьи), данными является текст, содержащийся в документе, который я должен написать, а степень сложности — это длина документа. Это немного надуманный пример, но если предположить, что я уже решил задачу f(900) (написать 900 слов), то все, что мне нужно сделать, чтобы решить f(1000) , ― это написать 100 слов и выполнить решение для 900 слов, f(900) .
Давайте рассмотрим пример получше: с числами Фибоначчи, где 1-е число равно 0, второе равно 1, а nᵗʰ число равно сумме двух предыдущих. Предположим, у нас есть функция Фибоначчи, которая сообщает нам n ᵗʰ число:
Как будет выглядеть выполнение такой функции? Возьмём для примера fib(4):
Визуализация древа рекурсии, показывающая рекурсивное вычисление, которое приводит к fib(4) = 3. Обратите внимание, что вычисление сначала выполняется в глубину.
Визуализация древа рекурсии, показывающая рекурсивное вычисление, которое приводит к fib(4) = 3. Обратите внимание, что вычисление сначала выполняется в глубину.
Рекурсивная стратегия
Рекурсивный подход — дело тонкое, и зависит от того, какую проблему вы пытаетесь решить. Тем не менее, есть некоторая общая стратегия, которая поможет вам двигаться в правильном направлении. Эта стратегия состоит из трёх шагов:
- Упорядочить данные
- Решить малую часть проблемы
- Решить большую часть проблемы
Как я уже говорил, я думаю, что для обучения полезно приводить пример, но помните, что рекурсивный подход зависит от конкретной задачи. Поэтому старайтесь сосредоточиться на общих принципах. Мы рассмотрим простой пример с реверсом строки. Мы напишем функцию reverse,которая будет работать так: reverse('Hello world') = 'dlrow olleH'. Я рекомендую вернуться назад и посмотреть, как эти шаги применяются к функции Фибоначчи, а затем попробовать применить их на других примерах (в интернете можно найти много упражнений).
Упорядочивание данных
Этот шаг является ключевым для решения проблем рекурсивным способом, и все же его часто упускают из виду или выполняют неявно. Какие бы данные мы ни использовали, будь то числа, строки, списки, бинарные древа или люди, необходимо явно найти целесообразный порядок, который даст нам видение, как упростить задачу. Порядок полностью зависит от конкретной задачи, но для начала стоит подумать об очевидных вариантах. Например: числа можно упорядочить по величине, строки и списки можно упорядочить по длине, бинарные древа по глубине, а люди могут быть упорядочены бесконечным количеством разумных способов: рост, вес или должность в организации. Это упорядочивание должно соответствовать степени сложности задачи, которую мы пытаемся решить.
После того, как мы упорядочили данные, нам нужно подумать об этом, как о чём-то, что мы можем сократить. На самом деле, мы можем записать наш порядок в виде последовательности:
0, 1, 2, …, n для чисел (т.е. для int данных d, степень(d) = d)
[], [■], [■, ■], …, [■, … , ■] для списков (len = 0, len = 1, …, len = n и т.д. для списка d, степень(d) = len(d))
Решаем малую часть проблемы
Как правило это самая лёгкая часть. После того, как мы определились с порядком, мы должны выделить в нём самые маленькие элементы, и решить, как мы будем обрабатывать их. Обычно, можно найти очевидное решение: в случае reverse(s), как только мы дойдём до len(s) == 0, имея при этом reverse(''), это будет знаком, что мы нашли ответ, потому что реверс пустой строки ничего не даст, т.е. нам вернётся пустая строка, так как у нас нет символов, которые можно перемещать. Если мы знаем решение для базового случая, и мы знаем порядок, то для нас, степень сложности решения общего случая, уменьшается в зависимости от степени сложности данных, которыми мы оперируем, приближаясь к базовым случаям. Мы должны быть внимательны, чтобы не пропустить ни одного базового случая: они и называются базовыми, потому что образуют основу порядка. Пропуск маленького шага считается распространённой ошибкой в сложных рекурсивных задачах, и приводит к бессмысленным данным или ошибкам.
Переходим к общим случаям
На этом этапе мы обрабатываем данные двигаясь вправо, то есть в сторону высокой степени. Как правило, мы рассматриваем данные произвольной степени, и ищем способ решения проблемы, упрощая её до выражения, представляющего ту же проблему, но в меньшей степени. Например, в случае с числами Фибоначчи мы начали с произвольного значения n и упростили fib(n) до fib(n-1) + fib(n-2), что является выражением, содержащим два экземпляра той же задачи, но в меньшей степени (n-1 и n-2, соответственно).
Возвращаясь к алгоритму reverse, мы можем рассмотреть произвольную строку с длинной n, и предположить, что наша reverseфункция работает для всех строк с длинной меньше n. Как мы можем использовать это, решая задачу для строки с длинной n? Мы могли бы сделать реверс строки, переместив всё, кроме последнего символа, а затем вставить этот последний символ в начало. В коде:
reverse(string) = reverse(string[-1]) + reverse(string[:-1])
где string[-1] соответствует последнему символу, а string[:-1]соответствует строке без последнего символа (это питонизм). Последний член функции reverse(string[:-1]), и является нашей исходной задачей, но он оперирует со строкой длины n-1. Таким образом, мы выразили нашу исходную задачу в решении той же задачи, но в уменьшенной степени.
Любая функция (метод) в своем теле может вызывать сама себя. Рекурсия – это такой способ определения функции, при котором результат возврата из функции для данного значения аргумента определяется на основе результата возврата из той же функции для предыдущего (меньшего или большего) значения аргумента.
Если функция (метод) вызывает сам себя, то такой вызов называется рекурсивным вызовом функции. При каждом рекурсивном вызове запоминаются предыдущие значения внутренних локальных переменных и полученных параметров функции. Чтобы следующий шаг рекурсивного вызова отличался от предыдущего, значение как-минимум одного из параметров функции должно быть изменено. Остановка процесса рекурсивных вызовов функции происходит, когда изменяемый параметр достиг некоторого конечного значения, например, обработан последний элемент в массиве.
2. Объяснения к реализации задач на рекурсию. Как правильно организовать рекурсивный вызов функции?
Рекурсивное обращение к функции может быть осуществлено, если алгоритм определен рекурсивно.
Чтобы циклический процесс преобразовать в рекурсивный, нужно уметь определить (выделить) три важных момента:
- условие прекращения последовательности рекурсивных вызовов функции. Например, если счетчик или итератор с именем k изменяется от 1 до 10 в возрастающем порядке, то условие прекращения есть достижение значения k =10. Условие прекращения указывается в операторе return ;
- формулу следующего элемента или итератора, который используется в рекурсивном процессе. Эта формула указывается в операторе return ;
- список параметров, которые передаются в рекурсивную функцию. Один из параметров обязательно есть итератор (счетчик) изменяющий свое значение. Другие параметры являются дополнительными, например, ссылка на массив, над которым осуществляется обработка.
3. Поиск суммы элементов массива. Пример
По подобному примеру можно создавать собственные рекурсивные функции, которые определяют любые суммы элементов любых массивов.
Задача. Задан массив чисел A . Разработать рекурсивную функцию, которая находит сумму элементов массива:
где n – количество элементов массива. Программный код функции следующий:
Как видно из примера, в рекурсивную функцию Sum() передается 3 параметра:
- текущее значение итератора i ;
- массив A ;
- количество элементов массива n .
Выход из функции осуществляется, если будет обработан последний элемент массива. Условие прекращения рекурсивного процесса имеет вид:
Для суммирования текущего значения A[i] со следующими указывается строка:
где рекурсивный вызов Sum(i+1, A, n) означает следующее значение массива A . Параметр i+1 указывает, что на следующем уровне вызова рекурсивной функции будет взят следующий после данного элемент массива.
Использование функции Sum() в другом программном коде может быть, например, таким:
4. Пример подсчета количества вхождений заданного символа в строке
В данном примере реализована рекурсивная функция Count() , которая определяет количество вхождений заданного символа c в строке s . Функция получает 3 параметра:
- символ c , который нужно сравнить с каждым символом строки s ;
- строка s ;
- дополнительная переменная i , которая есть счетчиком рекурсивного цикла.
Реализация функции Count() следующая:
5. Пример нахождения факториала числа – n!
Вычисление факториала числа методом рекурсии есть почти в каждом учебнике. Факториал числа вычисляется по формуле
Рекурсивный вызов можно организовать двумя способами:
- в порядке возрастания 1, 2, …, n ;
- в порядке убывания n , n -1, …, 2, 1.
В данном примере разработаны две функции, которые находят факториал обоими способами. Программный код функций следующий:
В первую функцию Fact1() передаются 2 параметра. Первый параметр определяет максимально возможное значение n , которое может быть умножено. Второй параметр определяет текущее значение i которое умножается.
Во второй функции Fact2() передается 1 параметр – максимально возможное значение n , принимающее участие в рекурсивном умножении. Второго параметра здесь не нужно, поскольку условие прекращения рекурсивного процесса есть известно и равно 1. В функции Fact2() рекурсивный процесс завершается при n =1.
Использование функций в другом программном коде может быть следующим:
6. Программа нахождения наибольшего общего делителя (алгоритм Евклида). Пример
В примере определяется наибольший общий делитель по формуле Евклида:
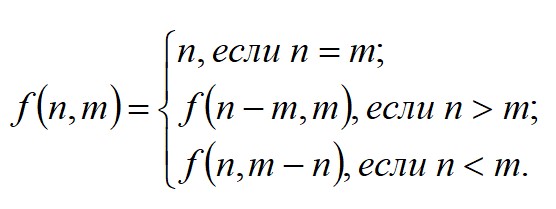
Программный код функции следующий:
Использование функции MaxDiv() может быть следующим:
7. Подсчет количества элементов массива, больших заданного числа. Пример
Демонстрируется метод Count() , возвращающий количество элементов, больших заданного числа num . В метод передается 4 параметра:
- число num , которое нужно сравнивать с каждым элементом массива;
- массив чисел A[ ] ;
- количество элементов массива n ;
- текущее значение счетчика в массиве.
Использование метода Count() в другом методе
8. Преимущества использования рекурсии в программах. Пример
Рекурсию часто сравнивают с итерацией. Организация циклического процесса с помощью рекурсии имеет свои преимущества и недостатки.
Обычно есть вызывающая процедура и собственно рекурсивная функция. Собственно, теоретическая часть статьи заключается в изложении структуры рекурсивной функции. Изучать рекурсию проще используя процедуру с параметрами, а не функцию, возвращающую значение.

Для деревьев вместо условия применяется цикл. Деревья рассмотрим ниже.
Задача - научиться понимать эти пять блоков команд.
Самая известная тема для рекурсии — это расчет факториала:
Очень красивый код, но не очень понятный …
Напишем код расчета факториала согласно нашей модели (Листинг 1):
Не так красиво, как (2), но мы учимся.
н – значение для вычисления факториала;
Ф – факториал (для н=4 будет 24).
Код достаточно понятный. Заметим только то, что Ф рассчитывается на прямом пути. На обратном пути (Возврат) – ничего не происходит. Полезно отследить изменение параметров в отладчике:

Здесь использованы блоки 1 и 2.
Блок1 – как правило на практике, нужен для подготовки Условия.
Блок2 – нужен для подготовки вызова рекурсивной процедуры (функции);
Теперь можно изменить процедуру Факториал убрать параметр к и приблизить её к каноническому виду (1).
На следующем шаге заменим процедуру на функцию и уберем вычисление Ф в Блоке2.
Для полного понимания предварительно рассмотрим следующий вариант:
Возвращаться будет 1.
Строки Останов = Истина добавлены для анализа переменных Ф и н в отладчике. Теперь нет параметра Ф в виде ссылки и возвращается локальное значение Ф, которое было зафиксировано при первом входе в рекурсию.
Исправим, добавим возврат переменной Ф. И увидим, что такое локальная переменная в рекурсивной функции – в отладчике. Это важно понимать.

На рисунке выше момент, когда вернулись в функцию, в которую входили с н = 2 и Ф = 12. Значение Ф сохранилось как для локальной переменной.
Это момент, когда еще не присвоено Ф возвращаемое значение функцией Факториал.

И вот на следующем шаге Ф переприсваивается.
В итоге функция отработает правильно.
Здесь мы не пишем функцию факториал, мы смотрим для чего нужны Блоки 1-5, как ведут себя переменные.
Рассмотрим простые примеры рекурсий в 1С.
Эта универсальная функция полезна для фиксации шапки отчета при программном выводе его:
Здесь Кз - высота заголовка, Кг – высота шапки.
Функция упрощена для примера. Настройки – настройки варианта макета, объявленные в Перем:
Рекурсивная функция написана в стиле листинга 1 и предельно понятна.
Основное применение рекурсии нашли при работе с деревьями. В 1С это в основном работа с иерархическими справочниками.
В теории деревьев различают корень, ветки и листья. Корень (ствол) это один элемент.
В 1С корня в классическом понимании у справочника нет. Корень — это сам иерархический справочник. Группы самого верхнего уровня имеют значение метода Уровень () = 0.
Рассмотрим пример определения самого старшего родителя для произвольного элемента справочника.
Каждый узел дерева имеет в точности одного родителя, за исключением корня, у которого нет родителей.
Это значит, что при движении по дереву вверх циклы не понадобятся.
Рассмотри пример использования рекурсий при обходе иерархического справочника с целью расчета себестоимости объектов строительства.
Есть объекты строительства. Объекты связаны иерархической моделью.
Нижние уровни дерева (листья) имеют прямые затраты. Их родители имеют косвенные затраты, которые нужно распределить на нижний уровень пропорционально прямым затратам объектов (листьев).
Прямые затраты – стоимость оборудования, косвенные – работы, необходимые для монтажа и ввода в эксплуатацию оборудования.
Вот пример из реальной БД:


Для решения задачи разберем алгоритм на следующей модели:
Рис. 1. Схема дерева

Рис.2. Дерево в справочнике объектов
Три уровня иерархии. Шесть объектов строительства с прямыми затратами и три с косвенными (группы).
Рассчитаем косвенные для объектов вручную.
База распределения для объекта Объект1 = 3000+2000 = 5000;
Косвенные от Объекта1:
для Объекта11 косвенные = 500 * 3000 / 5000 = 300.
для Объекта12 косвенные = 500 * 2000 / 5000 = 200.
База распределения для объекта Объект2 = 3000+2000+1000 = 6000;
Косвенные от Объекта2:
для Объекта21 косвенные = 600 * 3000 / 6000 = 300.
для Объекта22 косвенные = 600 * 2000 / 6000 = 200.
для Объекта23 косвенные = 600 * 1000 / 6000 = 100.
База распределения для объекта Объект0 – 5000+6000+1000 = 12000;
Для Объекта01 косвенные = 2400 * 1000 / 12000 = 200.
Для Объекта11 косвенные = 2400 * 3000 / 12000 = 600.
Для Объекта12 косвенные = 2400 * 2000 / 12000 = 400.
Для Объекта21 косвенные = 2400 * 3000 / 12000 = 600.
Для Объекта22 косвенные = 2400 * 2000 / 12000 = 400.
Для Объекта23 косвенные = 2400 * 1000 / 12000 = 200.
В итоге косвенные:
Для Объекта01 косвенные = 200
Для Объекта11 косвенные = 600 + 300 = 900
Для Объекта12 косвенные = 400 + 200 = 600
Для Объекта21 косвенные = 600 + 300 = 900
Для Объекта22 косвенные = 400 + 200 = 600
Для Объекта23 косвенные = 200 + 100 = 300
Итого косвенных 3500

В запросе должно быть так:
Следующий момент - куда лучше выгружать данные:
Мы выбираем дерево, потому что
В отладчике можно посмотреть данные.
Код более понятный – объект, строки, цикл.
Есть возможность реквизиты дерева использовать для алгоритма (записывать в реквизиты данные).
В интернете много статей обхода дерева как такового. А вот обход дерева, сгенерированного запросом, рассмотрен крайне скупо. Для выборки - статей написано много.
Поэтому рассмотрим алгоритм обхода дерева вниз и вверх - подробно.
Объявляем переменную ОбъектыДляПриемки, которая будет видна во всех серверных функциях.
По кнопке с клиента вызываем серверную процедуру, в которой выполняем Запрос с итогами в иерархии. Выгружаем Результат Запроса в Дерево.
с типом обхода ПоГруппировкамСИерархией. Передаем в рекурсивную функцию Строки объекта строительства, который принимаем в эксплуатацию.
Здесь важно – Объект0, это не корневой узел справочника! Но в дереве
он становится корневым (отбор по объекту).
Посмотрим данные дерева в отладчике:
Окно 1: Корень объекта строительства и его строки (Объект0)
Окно 2: Строка корня, нажимаем на ней F2
Окно 3: Строка корня раскрылась и видим Строки
Окно 4: После нажатия F2 на строке Строки
В четвертом окне 4 строки.

Проанализируем этот список (отмечен цифрой 4).
Первая строка – Объект01 – объект, который мы будем принимать к учету (это последний уровень, лист). Эта строка аналог записи в Выборке с типом – ДетальнаяЗапись.
Вторая строка – итоги по объекту Объект0. Эта строка аналог записи в Выборке с типом – ИтогПоИерархии.
Третья и четвертые строки – узлы дерева, их нужно раскрывать рекурсией.
Ниже приведены рекурсивные функции для расчета распределенных косвенных затрат.
В функции Рекурсия анализируем, какой тип строки дерева. Для детальной записи количество строк = 1 (своя строка). Для узла количество записей рано количеству потомков +1.
Запросом рассчитали суммарные значения прямых затрат для каждого узла дерева.
Во второй части условия проверяется ссылка Родителя, а если он не определён в первой части? Ответ: Если первая часть = Ложь то компилятор в условии И
не проверяет сведущие составляющие условия.
Поставим точку останова в функции КосвеныеОбъектовНаСервере как показано на рисунке ниже:

Увидим результаты запроса.

Так выглядит запись для корневой строки дерева после прохождения рекурсии. Сумма прямых затрат всех объектов нижних уровней равна 12 000.
На прямом пути для элемента самого нижнего уровня создаем строку в таблице значений:

Чтобы увидеть в отладчике ставим точку останове, показанную на рисунке ниже.

И сразу вызываем вторую рекурсивную функцию Косвенные.
Эта функция рассчитывает косвенные расходы для этого объекта от каждого родителя.
В итоге таблица ОбъектыДляПриемки будет выглядеть следующим образом:

Результат соответствует ручному расчету (Листинг 3).
Но основная цель статьи рассмотреть использование различных областей рекурсивно функции. Перепишем ее следующим образом.
Добавим в таблицу ОбъектыДляПриемки колонку Прямые.
В результате расчета получим такую таблицу:

В этом варианте не используется вторая рекурсивная функция на прямом обходе дерева. Рассчитываем необходимые данные на обратном ходе. Конечно
Можно и нужно оптимизировать быстродействие этого решения, но цель здесь другая.
Выводы являются субъективным мнением автора.
При разработке алгоритмов с рекурсиями целесообразно использовать параметры функций, для возврата на верхние уровни значений, рассчитанных на нижних уровнях. Или использовать объявление переменных со сквозной видимостью в рекурсиях.
Рассматривать целесообразность и использовать обратный ход рекурсивного расчета (область кода после выхода из рекурсивной функции).
Рекурсия — это что-то, что описывает само себя.
Представить рекурсию проще всего на примере зеркального коридора — когда напротив друг друга стоят два зеркала. Если посмотреть в одно, то в нём будет отражение второго, во втором — отражение первого и так далее.
Второй пример, чуть более академически правильный — это фрактал. Тот же треугольник Серпинского — это пример рекурсии, потому что часть фигуры — это одновременно вся фигура.

Треугольник состоит из 3 точно таких же треугольников.
Рекурсия в программировании
В программировании под рекурсией чаще всего понимают функцию, которая вызывает саму себя.
При решении некоторых задач мы можем обнаружить, что решение можно разбить на несколько простых действий и более простой вариант той же задачи.
Например, при возведении числа в степень мы берём число, умножаем его на себя несколько раз. Эту операцию можно представить в виде:
Но это же можно представить в виде нескольких последовательных умножений на 2:
При таком представлении всё возведение в степень — это лишь умножение предыдущего результата на 2:
Именно такие задачи называются рекурсивными — когда часть условия ссылается на всю задачу в целом (или похожую на неё).
У рекурсии 2 составляющие: повторяющиеся операции и базовый случай.
Повторяющиеся операции
В примере с возведением в степень повторяющиеся операции — это умножение.
Такие операции могут быть сложными и включать в себя несколько подзадач. Такое, например, часто встречается в математике.
Знаменитая сумма всех натуральных чисел контринтуитивно равняется -1/12. А доказывается это именно рекурсивно.
Базовый случай
Вторая важная часть рекурсии — это базовый случай.
Базовый случай — это условие, при выполнении которого рекурсия заканчивается и функция больше не вызывает саму себя.
Например, при возведении в степень базовый случай наступает, когда значение степени становится равно искомому.

Как только выполнение доходит до базового случая, оно останавливается.
Без базового случая любая рекурсивная функция уйдёт в бесконечное выполнение, потому что будет вызывать себя без конца.
В JS это приводит к переполнению стека вызовов, и функция останавливается с ошибкой.

Если выполнить функцию без базового случая, которая лишь вызывает себя, получим ошибку.
Цикл и рекурсия
Из-за повторяющихся операций рекурсия схожа с циклом. Их часто считают взаимозаменяемыми, но это всё же не совсем так.
Рекурсия проигрывает циклу в следующем:
- Отлаживать рекурсию значительно сложнее, чем цикл, а если функция написана плохо — то и просто читать.
- Она может приводить к переполнению стека. Особенно это ощутимо в таких языках как JS, где переполнение стека может наступить раньше базового случая с высокой вероятностью.
- Её выполнение может (хотя необязательно) занимать больше памяти.
Цикл же проигрывает рекурсии в таких вещах:
- Его нельзя использовать в функциональном программировании, потому что он императивен.
- Циклом гораздо сложнее обходить вложенные структуры данных, например, каталоги файлов.
- Результат выполнения рекурсивной функции проще закэшировать, чтобы ускорить выполнение, с циклом это сделать сложнее.
- При работе с общими ресурсами или асинхронными задачами чаще удобнее использовать рекурсивные функции из-за замыканий.
Давайте решим одну и ту же задачу с использованием цикла и рекурсии, чтобы увидеть разницу в подходах. Будем писать функцию для нахождения факториала.
Факториал числа — это произведение всех чисел от единицы до этого числа. Например, факториал 5 — это произведение (1 × 2 × 3 × 4 × 5) = 120.
Факториал с помощью цикла
Сперва решим задачу нахождения факториала с помощью цикла.
В этой функции мы используем цикл, чтобы умножить каждое число на результат предыдущего умножения. То же самое мы можем сделать и рекурсивно.
Факториал с помощью рекурсии
Для расчёта факториала рекурсивно мы создадим функцию, в которой в первую очередь опишем базовый случай, а уже потом — повторяющиеся действия.
Хорошим правилом при работе с рекурсией считается первым делом описывать базовый случай (как ранний выход, early return) и только потом — всё остальное. Это позволяет сделать работу с рекурсией безопаснее.

В виде блок-схемы мы можем представить алгоритм факториала как условие и под-вызов той же функции.
Кроме того, что функция стала заметно короче, она теперь выражает непосредственно математическую суть факториала.

Процесс вычисления факториала 5 будет состоять из 4 под-вызовов функции factorial() .
Разберём по шагам, что происходит с переменной n и результатом функции factorial после каждого вызова:
Минусы такой реализации:
- Много областей видимости (замыканий), которые относительно требовательны к памяти.
- Относительно просто читать, но сложнее отлаживать, чем цикл.
- Если мы часто считаем факториалы, мы можем кэшировать результаты выполнения, чтобы не считать факториалы заново. Рекурсивная функция с кешем будет возвращать посчитанный ранее результат сразу же, цикл же будет считать заново.
- Невозможно повлиять на процесс подсчёта как-то извне, замыкания не дают внешнему миру получить доступ к переменным внутри.
Рекурсивные структуры данных
Раньше мы упомянули, что в программировании чаще всего под рекурсией понимают функцию, которая вызывает сама себя. Но кроме рекурсивных функций ещё есть рекурсивные структуры данных.
Структура данных — это контейнер, который хранит данные в определённом формате. Этот контейнер решает, каким образом внешний мир может эти данные считать или изменить.
Структуры данных, части которых включают в себя такие же структуры, называются (вы угадали) рекурсивными. Работать с такими структурами в цикле не очень удобно. Чтобы понять почему, рассмотрим пример одной из рекурсивных структур данных — дерева.
Деревья
У каждого дерева есть корень — узел, из которого берут начало остальные узлы. Корень DOM-дерева выше — это элемент html .
Работать с деревьями с помощью циклов (итеративно) неудобно. Представьте, что мы хотим получить названия всех элементов на странице. Да, мы можем пройтись циклом по 1-му уровню или 2-му, но дальше нужно думать, как определять, где мы были, где ещё нет и куда идти дальше.
С рекурсией обход дерева становится немного проще.
Рекурсивный обход
В случае с рекурсией мы можем придумать например такой алгоритм для обхода дерева:
- базовый случай: если у узла дерева нет дочерних узлов вовсе, или мы обошли их все — возвращаем название этого элемента;
- повторяемые операции: рекурсивно обходим каждый дочерний элемент, собирая их названия.
Таким образом, начав с элемента html , мы пройдём по каждому элементу дерева и запишем их названия. В псевдокоде это выглядело бы так:
Когда использовать рекурсию
Сама по себе рекурсия — это всего лишь инструмент. Нет чётких правил, когда её надо использовать, а когда — нет. Есть лишь некоторые рекомендации.
Читайте также:
- Как написать должность преподавателя на титульном листе
- Нужно ли брать диплом в армию
- Выплачивали ли в китае деньги при коронавирусе
- Гражданин копылов обратился с вопросом к юристу можно ли при государственной регистрации
- Можно ли понять и простить человека совершившего преступление моцарт и сальери