
Протоколы динамической маршрутизации это
Обновлено: 16.05.2024
Описание из Вики: OSPF(англ. Open Shortest Path First) — протокол динамической маршрутизации, основанный на технологии отслеживания состояния канала (link-state technology) и использующий для нахождения кратчайшего пути алгоритм Дейкстры.
Для чего нужен OSPF и как применять его на сетях, построенных на Mikrotik RouterOS, мы и рассмотрим в этой статье.
Описание работы протокола OSPF
Все, кто работал с сетями, имеющими более одной подсети (провайдеры, компании с филиалами, несколько vlan и т.д.) знают о необходимости существования маршрутов из одной сети в другую. Иначе пакеты в соединении будут просто улетать на шлюз по умолчанию и дропаться где-то в интернете.
Для тех же, кто с этим не знаком, поясню. Представьте, что мы внезапно захотели попасть из Челябинска в Киев, не имя при этом ни карты, ни навигатора. Поедем по указателям - не зря же их ставили.
Таким образом посмотрев на 10-20-100 укзателей мы рано или поздно доберемся до Киева - пакет от отправителя ушел к адресату. Сделали там все свои дела и захотели обратно домой в Челябинск - приложение обработало пакет и отправило ответ инициатору соединения. Но дорогу то мы не помним (в пакете нет никаких данных о прохождении пути. На самом деле есть намеки на это, но с помощью них нельзя восстановить путь пакета). Не беда - поедем по указателям.
Так же как и в первый раз мы каким-то образом вернемся в точку, из которой выехали. Причем, очень важно то, что вернуться мы можем по другим дорогам - на каких то начали укладывать асфальт за время нашего пребывания в Киеве и поставили знаки объезда, где-то просто затор и мы решили объехать по менее нагруженным трассам. Но мы все равно доберемся до места, пусть и затратив большее время.
Итак, мы, инкапсулированные в автомобиль - это данные, инкапсулированные в IP-пакет. Перекрестки на дороге - маршрутизаторы, подключенные к разным сетям (дорогам). А указатели на перекрестках - таблицы маршрутизации отдельных маршрутизаторов, знающие куда повернуть, чтобы попасть в ту или иную точку. И если в одну сторону мы доедем по указателям, а в другую указателей не будет, то пиши пропало - до исходной точки не доберемся. Значит, маршруты до общающихся сетей должны быть прописаны на обеих сторонах. И очень важно понимать, что дорог-маршрутов может быть несколько. И если один перекресток-маршрутизатор в ремонте, то предыдущий может послать нас в объезд, но сначала он должен узнать, что его сосед сломался. И если мы ездим по разным дорогам, значит и время пинга у нас будет разное.
Итак, с маршрутами разобрались. Теперь поговорим о дорожниках, ставящих указатели.
Статические указатели на дорогах - хорошо. Но расстояние между Челябинском и Киевом 2400 км. А значит и указателей должно быть не меньше 24 - по одному на каждые 100 км. И если на одном из перекрестков идет ремонт, необходимо внести изменения на два смежных указателя. А вероятность одновременного ремонта на 24 перекрестах весьма высока. То есть нужна отдельная бригада дорожников, меняющих указатели.
Было бы неплохо соединить все указатели в сеть и позволить им самим оценивать ситуацию на своих участках и передевать эти данные между собой. К сожалению великие и ужасные службы обслуживания дорог об этом ещё не додумались, да и вряд ли это надо - деньги то пилить не получится. А вот айтишники придумали технологии, позволяющие динамически изменять таблицы маршрутизации и обмениваться этой информацией. Эти технологии называются Протоколы Динамической Маршрутизации. И один из них - OSPF, предназначенный для обмена информацией внутри одной автономной системы - AS.
Настрока протокола OSPF на оборудовании Mikrotik
Термины и работа OSPF хорошо описаны в вики микротика. Но я осмелюсь кое-что повторить и перефразировать.
Допустим, есть следующая сеть:

Как видим, к сети 172.16.1.0 можно попасть двумя путями: через R2 и через связку R3+R4. Cost’ы, написанные возле каждого линка задают стоимость линка, своеобразный аналог параметра distance в ip-route. Чем ниже значение cost’а, тем выше вероятность того, что трафик пойдет по этому пути. Но как видно на следующем рисунке суммарная стоимость обоих маршрутов к сети 172.16.1.0 составляет 20. Так по какому же пути пойдет трафик?

В таком случае в таблице маршрутизации увидим примерно такую картину - к одной сети имеем два шлюза. И трафик должен пойти через оба шлюза. В этом случае мы можем управлять тем, куда пойдет трафик. Называется эта технология Policy Based Routing, но тема управления трафиком -- это совсем другая история.

Сделать, чтобы OSPF “заработал” в Mikrotik RouterOS очень просто - нужно лишь добавить в backbone на каждом роутере в Routing - OSPF - Networks все ваши сети, между которыми вы хотите динамическую маршрутизацию и “оно заработает”.

Но мы ведь хотим управлять процессом. Тот, кто не хочет управлять дальше может не читать. Остальным - добро пожаловать!
Пример организации протокола OSPF
Рассматривать будем сеть, типичную для организации с несколькими филиалами. Имеем центральный офис (Headquarter на схеме, для краткости будем звать его ЦО) с сетью 192.168.0.0/24 (что я, кстати, не рекомендую при дефолтных настройках OSPF. Почему - скажу ниже). В ЦО расположены все основные элементы инфраструктуры - контроллер домена, сервер удаленного доступа, почтовый сервер и т.д. Все филиалы должны иметь доступ ко всем этим сервисам.
Несколько филиалов (Branche на схеме, для краткости - СП - Структурное Подразделение) с адресами 192.168.X.0/24. Между ЦО и каждым СП шифрованный туннель SSTP (или любой другой VPN) - адреса в туннелях из подсети 192.168.255.0/24 (192.168.255.10 - ЦО, 192.168.255.1 - СП1, 192.168.255.2 - СП2, . ). Между филиалами связь не нужна, т.к. все службы в ЦО. Когда филиалов 3, нам легко добавить 3 маршрута на роутер в ЦО и по одному на каждый из роутеров СП. Итого 6 движений мышкой. А что если СП у нас не 3, а 33 и необходимы маршруты от каждого каждому, а ещё есть подрядчики с доступом к нескольким СП? Тут и приходит на помощь OSPF.

Кому надо “быстро и все равно как оно работает”, могут пойти по схеме, предложенной выше - добавить в backbone все свои сети.
Добавление сетей в Backbone
Почему именно backbone? Backbone в переводе с английского - хребет, позвоночник. OSPF оперирует понятиями Area (область), Autonomous System (AS, автономная система). AS - все сети, которые принадлежат вам и между которыми может работать ваш протокол динамической маршрутизации. Area - часть этой сети. На картинке ниже показана одна AS с тремя Area, одна из которых - backbone (Area 0 с ID 0.0.0.0). Каждая Area имеет свой ID, похожий на IP адрес. Backbone всегда имеет ID 0.0.0.0. Все области в OSPF должны иметь линк с backbone. Иначе ничего работать не будет.
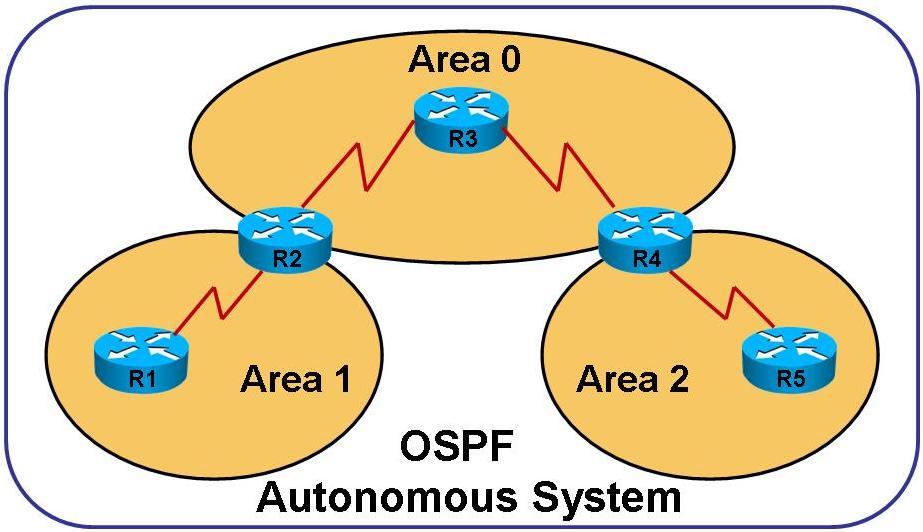
В нашем примере мы решили долго не думать и загнать все в backbone. По большому счету это ничем не грозит и работать будет. Но если провайдер отдает одному из ваших филиалов частный адрес из 192.168.0.0/16 (192.168.18.27/29, например), то в вашей таблице маршрутизации появится сеть провайдера. И если кто-то с другой стороны провайдера использует такие же настройки (или просто указал маршрут к вашим сетям), то он сможет беспрепятственно попасть в вашу сеть. А уж случайно это сделали или намеренно - узнаете когда данные из вашей БД всплывут в интернете.
В этом случае можно использовать авторизацию на каждом интерфейсе Routing - OSPF - Interfaces.

Или указать, что интерфейс, смотрящий к провайдеру будет в пассивном режиме.

Настройка OSPF в ручном режиме
Теперь поговорим о том, как сделать “правильно” - не вещать свои сети куда попало и позволить грамотно траблшутить работу OSPF.
Как мы говорили выше, каждая область имеет свой ID. Также и каждый участник OSPF имеет свой ID. По умолчаню он выставляется автоматически и выбирается из IP адресов, присвоенных интерфейсам роутера. Но нам надо проставить его в ручную, чтобы была какая-то логика в именовании и мы всегда знали откуда пришел запрос. Ставится это в Routing - OSPF - Instances - Router ID.

В нашей схеме имеется несколько областей. Как мы выяснили, основная область, соединяющая все остальные - backbone. Именно в этой области летают пакеты от одного роутера к другому, позволяющие обмениваться маршрутной информацией. Значит, этой областью должны быть туннели, соединяющие СП и ЦО, что видно на рисунке ниже.

Таким образом, нам необходимо выделить на каждом маршрутизаторе по две зоны - backbone и свою локальную сеть. На примере ЦО:
routing ospf area add name=Area0 area-id=192.168.0.0
routing ospf network add area=Area0 network=192.168.0.0/24
routing ospf network add area=backbone network=192.168.255.0/24
И точно так же на остальных маршрутизаторах, только заменив Area-ID, Area name и network на свои.
Теперь на каждом маршрутизаторе можем увидеть маршруты ко всем остальным сетям с буквами D и o в описании, что означает, что эти маршруты D - динамические (прилетели в резудльтате работы протоколов динамической маршрутизации) и o - из протокола OSPF.

Так мы получили простую и надежную настройку протокола динамической маршрутизации. У OSPF ещё имеется куча дополнительных настроек, таких как приоритет роутера, стоимость интерфейса, время определения состояний и многое, многое другое. Это позволяет очень гибко настроить маршрутизацию под свои нужды.

Маршрутизация является одной из самых фундаментальных областей сетей, которые должен знать администратор. Протоколы маршрутизации определяют, как ваши данные попадают в пункт назначения, и помогают максимально упростить этот процесс. Однако существует так много разных типов протокола маршрутизации, что может быть очень трудно отследить их все!
В этом посте мы собираемся обсудить ряд различных типов протоколов и концепций протоколов. Протоколы маршрутизатора включают в себя:
- Протокол маршрутизации информации (RIP)
- Протокол межсетевого шлюза (IGRP)
- Сначала откройте кратчайший путь (OSPF)
- Протокол внешнего шлюза (EGP)
- Усовершенствованный протокол маршрутизации внутреннего шлюза (EIGRP)
- Протокол пограничного шлюза (BGP)
- Промежуточная система-промежуточная система (IS-IS)
Прежде чем мы перейдем к рассмотрению самих протоколов маршрутизации, важно сосредоточиться на категориях протоколов. Все протоколы маршрутизации можно разделить на следующие:
- Протокол вектора расстояния или состояния соединения
- Протоколы внутреннего шлюза (IGP) или Протоколы внешнего шлюза (EGP)
- Классные или бесклассовые протоколы
Протокол вектора расстояния и состояния соединения
| Посылает всю таблицу маршрутизации во время обновлений | Предоставляет только информацию о состоянии ссылки |
| Отправляет периодические обновления каждые 30-90 секунд | Использует инициированные обновления |
| Обновления трансляций | Мультикаст обновления |
| Уязвим к петлям маршрутизации | Нет риска маршрутизации петли |
| RIP, IGRP | OSPF, IS-IS |
Протоколы векторного расстояния - это протоколы, которые использовать расстояние, чтобы определить лучший путь для пакетов в сети. Эти протоколы измеряют расстояние, основываясь на том, сколько данных прыжков должно пройти, чтобы добраться до места назначения. Количество прыжков - это, по сути, количество маршрутизаторов, необходимых для достижения пункта назначения..
Как правило, протоколы векторного расстояния отправляют таблицу маршрутизации, полную информации, на соседние устройства. Такой подход делает их низкими инвестициями для администраторов, поскольку их можно развернуть без особой необходимости в управлении. Единственная проблема заключается в том, что им требуется больше пропускной способности для отправки по таблицам маршрутизации, а также они могут работать в циклах маршрутизации..
Протоколы состояния канала
Протоколы состояния канала используют другой подход к поиску наилучшего пути, поскольку они обмениваются информацией с другими маршрутизаторами, находящимися поблизости. Маршрут рассчитывается исходя из скорости пути до пункта назначения и стоимость ресурсов. Протоколы состояния канала используют алгоритм для решения этой проблемы. Одно из ключевых отличий от протокола векторного расстояния состоит в том, что протоколы состояния канала не отправляют таблицы маршрутизации; вместо этого маршрутизаторы уведомляют друг друга при обнаружении изменений.
Маршрутизаторы, использующие протокол состояния канала, создают три типа таблиц; соседний стол, таблица топологии, и таблица маршрутизации. В таблице соседей хранятся сведения о соседних маршрутизаторах с использованием протокола состояния канала, в таблице топологии - вся топология сети, а в таблице маршрутизации - наиболее эффективные маршруты..
IGP и EGP
Протоколы маршрутизации также могут быть классифицированы как протоколы внутреннего шлюза (IGP) или протоколы внешнего шлюза (EGP). IGP - это протоколы маршрутизации, которые обмениваются информацией о маршрутизации с другими маршрутизаторами в пределах одной автономной системы (AS). AS определяется как одна сеть или совокупность сетей под управлением одного предприятия. Таким образом, компания AS отделена от ISP AS.
Каждое из следующего классифицируется как IGP:
- Сначала откройте кратчайший путь (OSPF)
- Протокол маршрутизации информации (RIP)
- Промежуточная система для промежуточной системы (IS-IS)
- Усовершенствованный протокол маршрутизации внутреннего шлюза (EIGRP)
С другой стороны, EGP - это протоколы маршрутизации, которые используются для передачи информации о маршрутизации между маршрутизаторами в разных автономных системах. Эти протоколы более сложные, и BGP - единственный протокол EGP, с которым вы, вероятно, столкнетесь. Однако важно отметить, что существует протокол EGP с именем EGP..
Примеры EGP включают в себя:
- Протокол пограничного шлюза (BGP)
- Протокол внешнего шлюза (EGP)
- Протокол междоменной маршрутизации ISO (IDRP)
Типы протокола маршрутизации
График маршрутизации
- 1982 - EGP
- 1985 - IGRP
- 1988 - RIPv1
- 1990 - есть
- 1991 - OSPFv2
- 1992 - EIGRP
- 1994 - RIPv2
- 1995 - BGP
- 1997 - RIPng
- 1999 - BGPv6 и OSPFv3
- 2000 - IS-ISv6
Протокол маршрутизации информации (RIP)
Протокол маршрутизации информации или RIP является одним из первых протоколов маршрутизации, которые будут созданы. RIP используется в обоих Локальные сети (Локальные сети) и Глобальные сети (WAN), а также работает на прикладном уровне модели OSI. Есть несколько версий RIP, включая RIPv1 и RIPv2. Исходная версия или RIPv1 определяет сетевые пути на основе IP-адреса и количества переходов в пути..
RIPv1 взаимодействует с сетью, передавая свою таблицу IP всем маршрутизаторам, подключенным к сети. RIPv2 немного сложнее и отправляет свою таблицу маршрутизации на адрес многоадресной рассылки. RIPv2 также использует аутентификацию для обеспечения большей безопасности данных и выбирает маску подсети и шлюз для будущего трафика. Основным ограничением протокола RIP является то, что он имеет максимальное число переходов 15, что делает его непригодным для больших сетей..
Смотрите также: Инструменты мониторинга локальной сети
Протокол межсетевого шлюза (IGRP)
Протокол внутреннего шлюза или IGRP - это протокол векторного расстояния, разработанный Cisco. IGRP был разработан на основе принципов, заложенных в RIP, для более эффективного функционирования в крупных сетях и снял колпачок на 15 прыжков это было помещено на RIP. IGRP использует такие показатели, как пропускная способность, задержка, надежность и нагрузка, для сравнения жизнеспособности маршрутов в сети. Однако в настройках IGRP по умолчанию используются только пропускная способность и задержка..
IGRP идеально подходит для больших сетей, потому что передает обновления каждые 90 секунд и имеет максимальное количество прыжков 255. Это позволяет поддерживать большие сети, чем протокол, такой как RIP. IGRP также широко используется, потому что он устойчив к петлям маршрутизации, потому что он автоматически обновляется, когда происходят изменения в сети.
Сначала откройте кратчайший путь (OSPF)
Протокол Open Shortest Path First или OSPF - это протокол IGP с состоянием канала, разработанный специально для IP-сетей, использующих Кратчайший путь первый (SPF) алгоритм. Алгоритм SPF используется для вычисления связующего дерева кратчайшего пути для обеспечения эффективной передачи пакетов. Маршрутизаторы OSPF поддерживают базы данных, детализирующие информацию об окружающей топологии сети. Эта база данных заполнена данными, взятыми из Объявления о состоянии ссылок (LSA) отправлено другими роутерами. LSA - это пакеты, которые содержат подробную информацию о том, сколько ресурсов займет данный путь..
OSPF также использует Алгоритм Дейкстры пересчитать сетевые пути при изменении топологии. Этот протокол также относительно безопасен, так как он может аутентифицировать изменения протокола для обеспечения безопасности данных. Он используется многими организациями, потому что его можно масштабировать до больших сред. Изменения топологии отслеживаются, и OSPF может пересчитать скомпрометированные маршруты пакетов, если ранее использованный маршрут был заблокирован.
Протокол внешнего шлюза (EGP)
Протокол внешнего шлюза или EGP - это протокол, который используется для обмена данными между хостами шлюза, которые соседствуют друг с другом в автономных системах. Другими словами, EGP предоставляет форум для маршрутизаторов для обмена информацией между различными доменами. Самым ярким примером EGP является сам Интернет. Таблица маршрутизации протокола EGP включает в себя известные маршрутизаторы, стоимость маршрутов и адреса соседних устройств. EGP широко использовался крупными организациями, но с тех пор был заменен на BGP.
Причина, по которой этот протокол потерял популярность, заключается в том, что он не поддерживает многопутевые сетевые среды. Протокол EGP работает, храня базу данных о близлежащих сетях и пути, по которым они могут добраться до них. Эта информация отправляется на подключенные маршрутизаторы. Как только он прибудет, устройства могут обновить свои таблицы маршрутизации и провести более осознанный выбор пути по всей сети..
Усовершенствованный протокол маршрутизации внутреннего шлюза (EIGRP)
Усовершенствованный протокол внутренней маршрутизации шлюза или EIGRP - это протокол маршрутизации вектора расстояния, который используется для IP, AppleTalk, и NetWare сетей. EIGRP является проприетарным протоколом Cisco, разработанным с учетом оригинального протокола IGRP. При использовании EIGRP маршрутизатор берет информацию из таблиц маршрутизации своих соседей и записывает их. Соседи запрашивают маршрут, и когда происходит изменение, маршрутизатор уведомляет своих соседей об этом изменении. Это приводит к тому, что соседние маршрутизаторы узнают о том, что происходит на соседних устройствах..
EIGRP оснащен рядом функций для максимальной эффективности, в том числе Надежный транспортный протокол (RTP) и Алгоритм диффузного обновления (DUAL). Пакетные передачи стали более эффективными, потому что маршруты пересчитываются для ускорения процесса конвергенции..
Протокол пограничного шлюза (BGP)
Протокол пограничного шлюза или BGP является протоколом маршрутизации Интернета, который классифицируется как протокол векторного пути. BGP был предназначен для замены EGP с децентрализованным подходом к маршрутизации. Алгоритм выбора лучшего пути BGP используется для выбора наилучших маршрутов для передачи пакетов. Если у вас нет пользовательских настроек, BGP выберет маршруты с кратчайшим путем к месту назначения..
Однако многие администраторы предпочитают менять решения о маршрутизации на критерии в соответствии со своими потребностями.. Алгоритм выбора лучшего пути можно настроить, изменив атрибут сообщества стоимости BGP. BGP может принимать решения о маршрутизации на основе таких факторов, как вес, локальные предпочтения, локально сгенерированный, длина AS_Path, тип источника, дискриминатор с несколькими выходами, eBGP через iBGP, метрика IGP, идентификатор маршрутизатора, список кластеров и адрес соседа.
BGP отправляет обновленные данные таблицы маршрутизатора только тогда, когда что-то меняется. В результате отсутствует автоматическое обнаружение изменений топологии, что означает, что пользователь должен настроить BGP вручную. С точки зрения безопасности протокол BGP может быть аутентифицирован, так что только утвержденные маршрутизаторы могут обмениваться данными друг с другом..
Промежуточная система-промежуточная система (IS-IS)
Промежуточная система-промежуточная система (IS-IS) - это состояние канала, протокол IP-маршрутизации и протокол IGPP, используемые в Интернете для отправки информации о IP-маршрутизации.. IS-IS использует модифицированную версию алгоритма Дейкстры. Сеть IS-IS состоит из ряда компонентов, включая конечные системы (пользовательские устройства), промежуточные системы (маршрутизаторы), области и домены..
В соответствии с IS-IS маршрутизаторы организованы в группы, называемые областями, и несколько областей группируются вместе, чтобы создать домен. Маршрутизаторы в этой области размещаются на уровне 1, а маршрутизаторы, которые соединяют сегменты, классифицируются как уровень 2. Существует два типа адресов, используемых IS-IS; Точка доступа к сетевой службе (NSAP) и Название сетевого объекта (СЕТЬ).
Классные и бесклассовые протоколы маршрутизации
Протоколы маршрутизации также могут быть классифицированы как классовые и бесклассовые протоколы маршрутизации. Различие между ними сводится к тому, как они выполняют обновления маршрутизации. Дискуссия между этими двумя формами маршрутизации часто упоминается как классовая или бесклассовая маршрутизация..
Классные протоколы маршрутизации
Классовые протоколы маршрутизации не отправляют информацию маски подсети во время обновлений маршрутизации, но бесклассовые протоколы маршрутизации делают. RIPv1 и IGRP считаются классными протоколами. Эти два являются классными протоколами, потому что они не включают информацию о маске подсети в свои обновления маршрутизации. Классовые протоколы маршрутизации с тех пор устарели бесклассовыми протоколами маршрутизации..
Бесклассовые протоколы маршрутизации
Как упоминалось выше, классовые протоколы маршрутизации были заменены бесклассовыми протоколами маршрутизации. Бесклассовые протоколы маршрутизации отправлять информацию маски IP-подсети во время обновления маршрутизации. RIPv2, EIGRP, OSPF и IS-IS - это все типы протоколов маршрутизации классов, которые включают информацию о маске подсети в обновлениях..
Протоколы динамической маршрутизации
Протоколы динамической маршрутизации - это еще один тип протоколов маршрутизации, которые имеют решающее значение для современных сетей корпоративного уровня. Протоколы динамической маршрутизации позволяют маршрутизаторам автоматически добавлять информацию в свои таблицы маршрутизации от подключенных маршрутизаторов. С помощью этих протоколов маршрутизаторы отправляют обновления топологии всякий раз, когда меняется топологическая структура сети. Это означает, что пользователю не нужно беспокоиться о том, чтобы постоянно обновлять сетевые пути..
Одним из основных преимуществ динамических протоколов маршрутизации является то, что они уменьшают необходимость управления конфигурациями. Недостатком является то, что это происходит за счет выделения ресурсов, таких как ЦП и пропускная способность, чтобы они работали на постоянной основе. OSPF, EIGRP и RIP считаются протоколами динамической маршрутизации..
Протоколы маршрутизации и метрики
Независимо от того, какой тип протокола маршрутизации используется, будут четкие метрики, которые используются для измерения того, какой маршрут лучше выбрать. Протокол маршрутизации может идентифицировать несколько путей к пункту назначения, но должен иметь возможность работать, что является наиболее эффективным. Метрики позволяют протоколу определять, какой путь следует выбрать, чтобы обеспечить сеть наилучшим обслуживанием..
Самая простая метрика для рассмотрения - это количество прыжков. Протокол RIP использует количество переходов для измерения расстояния, которое требуется для пакета до места назначения. Чем больше прыжков должен пройти пакет, тем дальше должен пройти пакет. Таким образом, протокол RIP направлен на выбор маршрутов, минимизируя, где это возможно, скачки. Существует много показателей, помимо числа переходов, которые используются протоколами IP-маршрутизации. Используемые метрики включают в себя:
- Количество прыжков - Измеряет количество маршрутизаторов, через которые должен пройти пакет
- Пропускная способность - выбирает путь на основе которого имеет наибольшую пропускную способность
- задержка - выбирает путь на основе которого занимает меньше всего времени
- надежность - Оценивает вероятность того, что ссылка потерпит неудачу, основываясь на количестве ошибок и предыдущих сбоях.
- Стоимость - значение, настроенное администратором или IOS, которое используется для измерения стоимости маршрута на основе одного показателя или диапазона показателей
- нагрузка - Выбор пути на основе использования трафика подключенных каналов
Метрики по типу протокола
| ПОКОЙСЯ С МИРОМ | Количество прыжков |
| RIPv2 | Количество прыжков |
| IGRP | Пропускная способность, задержка |
| OSPF | Пропускная способность |
| BGP | Выбранный администратором |
| EIGRP | Пропускная способность, задержка |
| IS-IS | Выбранный администратором |
Административное расстояние
Административное расстояние является одной из наиболее важных функций в маршрутизаторах. Административный - это термин, используемый для описания числового значения, которое используется для определения приоритетов, какой маршрут следует использовать при наличии двух или более доступных маршрутов. Когда один или несколько маршрутов расположены, в качестве маршрута выбран протокол маршрутизации с меньшим административным расстоянием. Существует административное расстояние по умолчанию, но администраторы также могут настраивать свои собственные.
| Подключенный интерфейс | 0 |
| Статический маршрут | 1 |
| Улучшенный сводный маршрут IGRP | 5 |
| Внешний BGP | 20 |
| Внутренний улучшенный IGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| IS-IS | 115 |
| ПОКОЙСЯ С МИРОМ | 120 |
| EIGRP внешний маршрут | 170 |
| Внутренний BGP | 200 |
| неизвестный | 255 |
Чем ниже числовое значение административного расстояния, тем больше маршрутизатор доверяет маршруту. Чем ближе числовое значение к нулю, тем лучше. Протоколы маршрутизации используют административное расстояние в основном как способ оценки надежности подключенных устройств. Вы можете изменить административное расстояние протокола, используя процесс расстояния в режиме субконфигурации.
Заключительные слова
Как вы можете видеть, протоколы маршрутизации могут быть определены и продуманы различными способами. Ключ заключается в том, чтобы рассматривать протоколы маршрутизации как протоколы векторов расстояния или состояния канала, протоколы IGP или EGP и классные или бесклассовые протоколы. Это общие категории, к которым относятся общие протоколы маршрутизации, такие как RIP, IGRP, OSPF и BGP..
Конечно, во всех этих категориях у каждого протокола есть свои нюансы в том, как он измеряет лучший путь, будь то по количеству переходов, задержке или другим факторам. Изучение всего, что вы можете узнать об этих протоколах, которые вы сохраняете во время повседневного общения, поможет вам как на экзамене, так и в реальной среде..
В рамках данной темы планируется написание цикла статей. Сегодня мы расскажем о динамической маршрутизации, которая используется практически в каждой более-менее крупной сети, будь то сеть предприятия или сеть провайдера.
- Что такое динамическая маршрутизация и для чего она используется.
- Протоколы динамической маршрутизации на коммутаторах SNR.
- Протокол OSPF и примеры настройки протокола OSPF на коммутаторах SNR.
Динамическая маршрутизация
Использование статической маршрутизации оправдано только в случае небольшого количества подсетей и полной уверенности в том, что конфигурация сети не будет меняться, ведь в случае изменений в сети необходимо реконфигурировать все маршруты вручную. Здесь и поможет применение одного (а то и нескольких) протоколов динамической маршрутизации, которые позволяют автоматически выстраивать и перестраивать маршруты в сети в случае аварий, при масштабировании сети, а также балансировке трафика.
Полностью теорию работы в рамках этой статьи мы рассматривать не будем, OSPF довольно популярный протокол и о нем написано очень много материалов, которые можно легко найти в сети. Например здесь или здесь. Однако для понимания конфигурации нам потребуются некоторые понятия. Рассмотрим их дальше.
Типы маршрутизаторов в OSPF
- Internal router - маршрутизатор, у которого все стыковочные интерфейсы находятся в одной зоне. Такой маршрутизатор не обменивается маршрутной информацией с другими AS и имеет одну LSDB.
- Area border router (ABR) - маршрутизатор, который находится на границе с магистральной зоной, и служит шлюзом для трафика, который проходит между зонами. Хотя бы один интерфейс такого маршрутизатора должен находиться в магистральной зоне. Для каждой зоны ABR имеет отдельную LSDB.
- Backbone router - магистральный маршрутизатор. Хотя бы один интерфейс такого маршрутизатора должен находиться в магистральной зоне. Внутренний маршрутизатор, у которого есть интерфейсы, принадлежащие нулевой зоне, тоже будет считаться магистральным. Может быть как ABR, так и не быть им.
- AS boundary router (ASBR) - такой маршрутизатор может обмениваться маршрутами с маршрутизаторами в других AS, или маршрутизаторами, использующими другой протокол маршрутизации. ASBR может быть в любом месте AS и являться как магистральным, так и внутренним или пограничным.
Типы зон OSPF
Разделение AS на зоны OSPF может снизить загрузку CPU маршрутизаторов, сократить размер LSDB и сократить количество пакетов LSA.
- Backbone (Area 0) - Магистральная зона OSPF. Это обычная зона, через которую происходят все взаимодействия между другими зонами.
- Normal - Зона с номером отличным от 0. Такой тип устанавливается по умолчанию, если в конфигурации не указан иной.
- Stub - Маршрутизаторы в такой зоне не принимают информацию об External-маршрутах, но принимают маршруты из других зон. Маршрутизатор в Stub-зоне не может выступать в качестве ASBR. Чтобы передавать трафик за границу AS, будет использован маршрут по умолчанию, транслируемый от ASR. Для настройки такого типа зон используется команда area X stub .
- Totally Stub - Stub-зона, которая принимает только маршрут по умолчанию. Для настройки такого типа зон используется команда area X stub no-summary .
- NSSA - Stub-зона, но маршрутизатор в такой зоне может выступать в качестве ASBR. Для трансляции External маршрутов используется LSA Type 7, которые трансформируются в LSA Type 5 на ASR. Для настройки такого типа зон используется команда area X nssa .
- Totally NSSA - Totally stub зона, но в ней может находиться ASBR. Имеет только маршрут по умолчанию. Для настройки такого типа зон используется команда area X nssa no-summary .
Базовая настройка OSPF
В качестве первого примера рассмотрим случай, если у нас всего одна магистральная зона (Area 0).
Допустим, у нас имеются коммутаторы SNR-S2995G-24FX, которые используются на уровне агрегации в сети оператора связи. На R1 терминируются клиенты с подсетью 10.10.11.0/24, которую мы хотим анонсировать и передать на BRAS, а также хотим, чтобы между коммутаторами была L3-связность.
Для такой ситуации оправдано применение протокола OSPF, т.к. количество коммутаторов и подсетей будет расти в будущем. Сложность масштабируемости и настройки статической адресации также будут быстро увеличиваться. В случае применения OSPF нам необходимо лишь выполнить первоначальную настройку и в будущем OSPF будет самостоятельно анонсировать добавленные подсети (добавленные на SVI подсети будут иметь тип Connected. Для того, чтобы OSPF перекладывал маршруты из Connected в OSPF, необходимо применить команду redistribute connected . Это мы рассмотрим во втором примере данной статьи).
В нашем примере схема будет выглядеть следующим образом:

conf t
vlan 10;3000
interface vlan 10
ip address 172.31.1.1 255.255.255.252
!
interface vlan 1000
ip address 10.10.11.1 255.255.255.0
!
interface Loopback1
ip address 10.10.10.11 255.255.255.255
!
interface E1/0/1
switchport access vlan 10
!
router ospf 1
ospf router-id 10.10.10.11
network 172.31.1.0/30 area 0
network 10.10.11.0/24 area 0
network 10.10.10.11/32 area 0
end
conf t
vlan 10
interface vlan 10
ip address 172.31.1.2 255.255.255.252
!
interface Loopback1
ip address 10.10.10.12 255.255.255.255
!
interface E1/0/1
switchport access vlan 10
!
router ospf 1
ospf router-id 10.10.10.12
network 172.31.1.0/30 area 0
network 10.10.10.12/32 area 0
end
- DOWN - начальное состояние;
- Init - после отправки Hello другому коммутатору, он ожидает от другого коммутатора свой hello. В этот момент он находится в состоянии Init;
- Full - когда коммутаторы получили всю информацию и LSDB синхронизирована, оба коммутатора переходят в состояние fully adjacent (FULL).
Убедимся, что соседство установилось и подсети R1 доступны через R2 и наоборот:

Как мы видим, соседство установилось и был выбран DR. В нашем случае, R2.

То же мы видим и на R2. Адрес Loopback1 и клиентская подсеть доступны с R2.
Настройка OSPF с использованием нескольких зон
Производительность коммутаторов ограничена. Размеры LSDB могут достигать размеров в тысячи маршрутов, при этом коммутатор тратит много ресурсов на просмотр своей таблицы маршрутизации, а если учесть, что помимо OSPF коммутатор должен обрабатывать и другие задачи, загрузка CPU может достигать критически высоких значений, что скажется на производительности коммутатора. В таких случаях целесообразно применение деления на зоны, которые помогут уменьшить количество маршрутов в LSDB, тем самым снизив нагрузку на CPU. Давайте рассмотрим пример использования NSSA и Totally Stubby area на следующей схеме:

R1:
vlan 1;100;300;1000
Interface Ethernet1/0/1
description R2
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 100
!
Interface Ethernet1/0/3
description R3
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 300
!
interface Vlan100
ip address 172.31.1.1 255.255.255.252
!
interface Vlan300
ip address 172.31.3.2 255.255.255.252
!
interface Vlan1000
ip address 10.10.100.1 255.255.255.0
!
interface Loopback1
ip address 10.10.10.1 255.255.255.255
!
router ospf 1
ospf router-id 10.10.10.1
passive-interface Vlan1000
network 172.31.1.0/30 area 0
network 172.31.3.0/30 area 0
redistribute connected
!
vlan 1;100;200;400
!
Interface Ethernet1/0/1
description R1
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 100
!
Interface Ethernet1/0/2
description R3
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 200
!
Interface Ethernet1/0/4
description R4
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 400
!
interface Vlan100
ip address 172.31.1.2 255.255.255.252
!
interface Vlan200
ip address 172.31.2.1 255.255.255.252
!
interface Vlan400
ip address 172.31.4.1 255.255.255.252
!
interface Loopback1
ip address 10.10.10.2 255.255.255.255
!
router ospf 1
ospf router-id 10.10.10.2
area 1 stub no-summary
network 172.31.1.0/30 area 0
network 172.31.2.0/30 area 0
network 172.31.4.0/30 area 1
redistribute connected
!
vlan 1;200;300;500
!
Interface Ethernet1/0/2
description R2
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 200
!
Interface Ethernet1/0/3
description R1
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 300
!
Interface Ethernet1/0/5
description R5
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 500
!
interface Vlan200
ip address 172.31.2.2 255.255.255.252
!
interface Vlan300
ip address 172.31.3.1 255.255.255.252
!
interface Vlan500
ip address 172.31.5.1 255.255.255.252
!
interface Loopback1
ip address 10.10.10.3 255.255.255.255
!
router ospf 1
ospf router-id 10.10.10.3
area 2 nssa default-information-originate
network 172.31.2.0/30 area 0
network 172.31.3.0/30 area 0
network 172.31.5.0/30 area 2
redistribute connected
!
vlan 1;400;3000
!
interface Vlan400
ip address 172.31.4.2 255.255.255.252
!
interface Vlan3000
ip address 10.10.120.1 255.255.255.0
!
Interface Ethernet1/0/4
description R2
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 400
!
interface Loopback1
ip address 10.10.10.4 255.255.255.255
!
router ospf 1
ospf router-id 10.10.10.4
passive-interface Vlan3000
area 1 stub
network 10.10.10.4/32 area 1
network 10.10.120.0/24 area 1
network 172.31.4.0/30 area 1
!
vlan 1;500;2000
!
Interface Ethernet1/0/5
description R3
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 500;2000
!
interface Vlan500
ip address 172.31.5.2 255.255.255.252
!
interface Vlan2000
ip address 10.10.110.1 255.255.255.0
!
interface Loopback1
ip address 10.10.10.5 255.255.255.255
!
router ospf 1
ospf router-id 10.10.10.5
passive-interface Vlan2000
area 2 nssa
network 172.31.5.0/30 area 2
redistribute connected
!
На данной схеме приведена сеть, в которой используется как Totally stubby (R2-R4), так и NSSA (R3-R5) зоны.
Внешние маршруты других зон в NSSA (R5) будут заменены на маршрут по умолчанию.
Для Totally stubby-зоны (R4) все маршруты будут заменены на маршрут по умолчанию.
Для анонса сетей, находящихся в Totally stubby зоне, необходимо указать их в Router OSPF.
Для анонса адресов Loopback в Area 0 используем команду redistribute connected . Это позволит нам не только упростить конфигурацию, но и сократить количество маршрутов, которые будут анонсироваться в другие типы зон, так как такие маршруты будут считаться External.
Для того, чтобы коммутаторы не искали соседей за SVI, на котором находятся клиентские подсети, применим команду passive-interface . Для R2 также применим команду redistribute connected metric-type 1 для того, чтобы увидеть разницу в типе метрик.
Посмотрим на таблицу маршрутов OSPF для маршрутизатора R1:

В данной таблице мы видим все маршруты, которые анонсируются на R1 путем OSPF. Маршруты до Loopback-адресов R2, R3 и R5 анонсируются как "E" (LSA Type 5), то есть, получены путем перекладывания маршрутов из другого протокола маршрутизации (в нашем случае из connected). Цифра 1 или 2 после буквы "E" показывает на тип метрики. 1 тип увеличивает метрику маршрута при расчете SPF, а 2 тип нет:

Давайте посмотрим на таблицу маршрутизации OSPF на R2 и R4:


Здесь мы наглядно видим зачем в принципе используются Totally stub - зоны. Вместо десятков маршрутов для нас доступен всего один - маршрут по умолчанию (для того, чтобы R2 анонсировал только маршрут по умолчанию, используем команду area 1 stub no-summary ). Несмотря на то, что маршрут всего один, все маршрутизаторы и сети доступны:

R4 не может генерировать LSA Type 5, так как находится в stub-зоне. Адрес Loopback и подсети, подключенные к R4 указаны вручную командой network .
Давайте посмотрим что у нас в NSSA на R5:

Как мы видим, маршруты, которые были redistribute, на R5 не попали, но они доступны через default, анонсируемый R3. Для того, чтобы R3 передавал информацию о маршруте по умолчанию мы применили команду area 2 nssa default-information-originate .

Так как R5 находится в NSSA, то он может выступать в качестве ASBR, а также перекладывать маршруты из других протоколов маршрутизации. Это значит, что в NSSA могут находится External-маршруты в виде специального LSA Type 7, который может находиться только в NSSA. На границе зоны пограничный коммутатор преобразует LSA Type 7 в LSA Type 5.
Для фильтрации маршрутов можно также воспользоваться функционалом ACL. Например, если на коммутаторе в NSSA-зоне мы хотим принимать только маршрут по умолчанию и маршруты из подсети 172.31.0.0/16, то необходимо создать ACL на R5 типа:
access-list 100 permit ip host-source 0.0.0.0 any-destination
access-list 100 permit ip 172.31.0.0 0.0.255.255 any-destination
access-list 100 permit ospf host-source 0.0.0.0 any-destination
access-list 100 permit ospf 172.31.0.0 0.0.255.255 any-destination
access-list 100 deny ospf any-source any-destination
access-list 100 deny ip any-source any-destination
!
router ospf 1
filter-policy 100
!
В таком случае таблица маршрутов будет иметь следующий вид:

Количество маршрутов сократилось, но все адреса Loopback и подсетей доступны через маршрут по умолчанию.
Заключение
В данной статье мы рассмотрели принципы работы протокола OSPF и его настройке на коммутаторах SNR. В будущем также планируется выход второй части данной статьи, посвященный протоколу BGP.
Во всех предыдущих разделах сам механизм управления маршрутами, порождения пакетов посети старательно обходился стороной, т.к. это предмет особого разговора. Программы управления маршрутами довольно сложны, а функции, которые они выполняют, являются критичными для всей системы в целом.
Основывается система маршрутизации на таблице маршрутов, которая определяет куда пакет с данным IP-адресом следует направлять. Ниже приведен пример такой таблицы, полученный при помощи команды netstat.
Пример 2.1. Таблица маршрутов
В данном примере в левой колонке указаны адреса возможных IP-адресов, которые система принимает из сети, далее идет адрес шлюза для данных адресов, затем флаги маршрутизации, степень использования данного маршрута и интерфейс, на котором данный маршрут обслуживается.
Однако, наша таблица не дает ответа на степень изменчивости данной таблицы. Для этого нам придется снова вернуться к изучению протоколов, но только теперь уже протоколов маршрутизации.
2.9.1. Статическая маршрутизация
Вообще говоря, из всей статической маршрутизации выделяют, так называемую, минимальную маршрутизацию. Такая маршрутизация возникает тогда, когда локальная сеть не имеет выхода в Internet и не состоит из подсетей. В этом случае достаточно выполнить команды ifconfig для интерфейса lo и интерфейса Ethernet и все будет работать:
В таблице маршрутов появятся только эти две строки, но так как сеть ограничена, и пакеты не надо отправлять в другие сети, то модуль ARP будет прекрасно справляться с доставкой пакетов по сети.
Если же сеть подключена к Internet, то в таблицу маршрутов надо ввести, по крайней мере, еще одну строку - адрес шлюза. Делается это при помощи команды route.
Команда route имеет следующий вид:
- add - добавить маршрут
- delete - удалить маршрут;
- get - получить информацию о маршруте.
В поле "сеть или хост" указывается адрес отправки пакета.
В поле "шлюз" указывается IP-адрес, через который следует отправлять пакеты, предназначенные хосту или сети из предыдущего поля.
Типичным примером применения команды route является назначение шлюза по умолчанию:
В данном примере все пакеты, адресаты которых не были найдены в локальной сети, отправляются на сетевой интерфейс с адресом 144.206.160.32. Метрика при этом принимается по умолчанию равная 1. Таким образом указывается, что это адрес шлюза.
Для того, чтобы получить таблицу маршрутов, приведенную в примере 2.1, нужно выполнить следующие команды:
Если сравнить эти записи с примером 2.1, то можно заметить, что одной строчки в списке команд не хватает. Это строка, которая описывает маршрут к сети 194.226.56 через шлюз 144.206.130.207. Дело в том, что поле флагов отчета netstat говорит нам, что такого маршрута в первоначальной таблице не было.
В поле флагов отчета netstat мы можем встретить следующие флаги:
U - говорит о том, что маршрут активен и может использоваться для маршрутизации пакетов;
H - говорит о том, что этот маршрут используется для посылки пакетов определенному в маршруте хосту;
G - говорит о том, что пакеты направляются на шлюз, который ведет к адресату;
D - этот флаг определяет тот факт, что данный маршрут был добавлен в таблицу по той причине, что с одного из шлюзов пришел ICMP-пакет, указывающий адрес правильного шлюза, который в нашей таблице отсутствовал.
Строчка, которая описывает не указанный в командах маршрут в таблице маршрутов выглядит следующим образом:
Если пользователи системы часто ходят в сеть 194.226.56.0, то в таблицу такой маршрут следует добавить:
При помощи команды route можно не только добавлять маршруты в таблицу маршрутов, но и удалять их от туда. Делается это по команде delete. Например, если нам надо изменить значение шлюза по умолчанию, то мы можем выполнить следующую последовательность команд:
В данном случае сначала мы удалим из таблицы (пример 2.1) маршрут умолчания, а затем добавим туда новый. При удалении маршрута достаточно назвать только адрес назначения, чтобы route идентифицировала маршрут, который следует удалить.
В заключении обсуждения вопросов статической маршрутизации хотелось бы сделать небольшое замечание по поводу Windows NT. До версии 4.0 в Windows NT штатно существовала только статическая маршрутизация. Для сетей локальных с надежными линиями связи этого вполне достаточно. Фактически, администратору нужно только указать IP-адреса на каждом из сетевых интерфесов, указать адрес шлюза по умолчанию и поднять флажок пересылки пакетов с одного интерфейса на другой. После этого все должно работать. Если локальная сеть подключается к провайдеру, то, как правило, все сводится к получению адреса из сети провайдера для внешнего интерфейса, т.е. интерфейса, который будет связывать вас с адресом шлюза провайдера и адресом своей сети или подсети. Если только провайдер не затеет изменения структуры своей сети, вес будет работать годами без каких-либо изменений. Для таких сетей шлюз на основе Windows NT можно организовать. Однако, не все так просто, когда речь идет о сети или подсети, которые подключаются в качестве части сети, которая не организована по иерархическому принципу. В этом случае возможно изменение наилучших маршрутов гораздо чаще, чем один раз в десятилетие и в этом случае статическая маршрутизация может оказаться недостаточной. Кроме того, важным фактором повышения надежности сетевого взаимодействия является наличие нескольких маршрутов к одним и тем же информационным ресурсам. В случае отказа одного из них можно использовать другие. Но проблема заключается в том, что система всегда использует тот маршрут, который первым встретился в таблице маршрутов, хотя и существуют мультимаршрутные системы, но они распространены, мягко говоря не очень широко. Следовательно, маршруты из таблицы надо удалять и вносить. Если сеть работает не устойчиво, то это превращается в головную боль администратора. Вот почему до версии Windows NT 4.0 рассматривать эту систему в качестве реального претендента на маршрутизатор не представляется возможным. В Windows NT 4.0 появилась поддержка динамической маршрутизации в лице протокола RIP, но поддержки других протоколов маршрутизации пока еще нет.
Таким образом, мы подошли к проблеме автоматического управления таблицей маршрутов на основе информации, получаемой из сети. Такая процедура называется динамической маршрутизацией.
2.9.2. Динамическая маршрутизация
Прежде чем вникать в подробности и особенности динамической маршрутизации обратим внимание на двухуровневую модель, в рамках которой рассматривается все множество машин Internet. В рамках этой модели весь Internet рассматривают как множество автономных систем (autonomous system - AS). Автономная система - это множество компьютеров, которые образуют довольно плотное сообщество, где существует множество маршрутов между двумя компьютерами, принадлежащими этому сообществу. В рамках этого сообщества можно говорить об оптимизации маршрутов с целью достижения максимальной скорости передачи информации. В противоположность этому плотному конгломерату, автономные системы связаны между собой не так тесно как компьютеры внутри автономной системы. При этом и выбор маршрута из одной автономной системы может основываться не на скорости обмена информацией, а надежности, безотказности и т.п.
Рис. 2.24. Схема взаимодействия автономных систем
Сама идеология автономных систем возникла в тот период, когда ARPANET представляла иерархическую систему. В то время было ядро системы, к которому подключались внешние автономные системы. Информация из одной автономной системы в другую могла попасть только через маршрутизаторы ядра. Такая структура до сих пор сохраняется в MILNET.
На рисунке 2.24 автономные системы связаны только одной линией связи, что больше соответствует тому, как российский сектор подключен к Internet. В классических публикациях по Internet взаимодействие автономных частей чаще обозначают пересекающимися кругами, подчеркивая тот факт, что маршрутов из одной автономной системы в другую может быть несколько.
Внешние протоколы служат для обмена информацией о маршрутах между автономными системами.
Внутренние протоколы служат для обмена информацией о маршрутах внутри автономной системы.
В реальной практике построения локальных сетей, корпоративных сетей и их подключения к провайдерам нужно знать, главным образом, только внутренние протоколы динамической маршрутизации. Внешние протоколы динамической маршрутизации необходимы только тогда, когда следует построить закрытую большую систему, которая с внешним миром будет соединена только небольшим числом защищенных каналов данных.
Мы уже знакомы со статической маршрутизацией, где необходимо маршруты создавать вручную. Однако такой способ маршрутизации неприемлем для больших сетей. На помощь приходят протоколы маршрутизации, которые позволяют вычислять оптимальный маршрут к каждой сети. Причем в случае изменении топологии сети протоколы оперативно реагируют на любые изменения в сети и просчитывают новые маршруты.
Существуют 2 типа протоколов маршрутизации.
IGP (Interior Gateway Protocol) - Протокол внутреннего шлюза.
EGP (Exterior Gateway Protocol) - Протокол внешнего шлюза.
IGP используются внутри автономных систем, а EGP - для связи автономных систем друг с другом.
Что такое автономная система?
Автономная система представляет собой сеть под единым доменом управления. Это может быть сеть одного провайдера или сеть большого предприятия

В свою очередь протоколы IGP делятся на 2 класса: дистанционно-векторные и по состоянию канала (LSA - Link State Algorithm)
Векторные протоколы
Протоколы по состоянию канала
Протокол IGRP является разработкой Cisco и сейчас практически не используется, поэтому рассматривать его не будем.
Краткая теория о векторном алгоритме маршрутизации
Принцип дистанционно-векторных протоколов основан на вычислении метрики - расстояния до сети назначения. Под расстоянием понимают количество узлов (участков сети), которые необходимо пройти пакету до сети назначения

Максимальная метрика в протоколе RIP равна 15. Метрика со значением 16 означает, то сеть недостижима.
Почему нельзя метрику увеличить?
Это связано с зацикливанием маршрутов, которое происходит в случае изменения топологии сети. Об этом подробнее ниже.
Все маршрутизаторы, на которых запущен данный протокол, периодически рассылают соседям свою таблицу маршрутизации. RIP рассылает свою таблицу каждые 30с.
Приняв такую таблицу маршрутизатор обновляет записи в своей таблице, а затем формирует новую рассылку таблицы на основе полученной информации.
Вот как выглядит процесс рассылки в трейсе

Векторный алгоритм не учитывает скорость и надежность канала. Механизм векторных протоколов позволяет балансировать нагрузку в случае, если до сети назначения будут найдены несколько маршрутов.
Проблемы векторных протоколов и способы их решения
Векторные протоколы не лишены недостатков:
- Маршрутизаторы периодически рассылает всю таблицу своим соседям и тем самым загружают канал связи.
- Медленная сходимость (convergence), то есть при изменении топологии сети (обрыв кабеля или выход из строя одного из маршрутизаторов) уходит много времени на оповещение всех маршрутизаторов и дальнейший расчет таблицы маршрутизации.
- Нельзя использовать в больших сетях.
- Не учитывается скорость канала при выборе наилучшего маршрута
Рассмотрим сеть ниже в нормальном состоянии

Теперь разберем процесс, когда происходит обрыв в сети.
Произошел обрыв и сеть Е недоступна. Маршрутизатор C отмечает, что маршрут до сети Е недостижим метрикой 16.
Однако остальные маршрутизаторы пока ничего не знают


Маршрутизатор C увеличивает метрику на 1 и помещает запись в свою таблицу. Если сеть большая, то данный процесс может привести к зацикливанию недостижимого маршрута, когда при передаче обновлений от маршрутизатора к маршрутизатору метрика будет все больше и больше увеличиваться. Поэтому было принято установить максимальную метрику равную 15.
Получается маршрутизатор C должен успеть передать обновление, иначе это приведет к зацикливанию и неверным записям в таблицах?
Все верно. Период обновления равен 30 с и это очень много. Поэтому были разработаны технологии для увеличения сходимости и устойчивой работы протокола.
Triggered update (немедленные обновления) - как только маршрутизатор обнаруживает обрыв, то сразу высылает обновления своим соседям. Однако это может загрузить канал связи, особенно, если изменения в сети происходят очень часто.
Split Horizon (расщепление горизонта) - маршрутизатор никогда не отправит информацию о сети через порт, с которого получил данную информацию.
Например, маршрутизатор B получил от маршрутизатора C информацию, что сеть E достижима с метрикой 1. Когда маршрутизатор B начнет свою рассылку маршрутизатору C, то в ней не будет указано ничего о маршруте до сети E

Poison reverse (опасный путь) - технология напоминает технологию Split Horizon, но с небольшим отличием. В технологии Split Horizon маршрутизатор не отправит обновление о сети обратно на тот интерфейс, через который получил обновление о данной сети. Poison reverse же наоборот отправляет это обновление о сети, о которой узнал через данный порт, однако помечает эту сеть недостижимой, то есть с метрикой 16.
Обе технологии решают одну и ту же задачу, но немного разными способами.
Таймеры векторных алгоритмов
Когда новый маршрут вычислен и помещен в таблицу маршрутизации, то запись о маршруте может находится в одном из ниже описанных состояний в зависимости от ситуации. Все значения будут указаны только для протокола RIP.
UP ( Update timer ) - маршрут в рабочем состоянии и присутствует в таблице маршрутизации. Каждые 30с маршрутизатор получает обновление о том, что маршрут достижимый. Частота обновления задается таймером Update timer.
Invalid (Holddown timer) - если по каким-то причинам маршрутизатор не получил обновление маршрута по истечении Update timer (30c), то маршрут помечается недостижимым, то есть с метрикой 16. Либо сосед уведомил, что маршрут недостижимый. Одновременно запускается Holddown timer равный 180с. Если в течении 180с маршрутизатор получит обновление маршрута с лучшей метрикой, то таймер обнуляется и маршрут помечается как достижимый.
Garbage collection (Flush timer) - если маршрутизатор в течении таймера Holddown не получил обновление, то по истечении таймера запускается Flush timer равный 240с. Если в течении данного времени будет получен маршрут с лучшей метрикой, то таймер обнуляется, а маршрут становится снова достижимым. В противном случае вся информация о маршруте удаляется из базы данных маршрутизатора.
Читайте также:
- По итогам проверки данных банк отказал в подписании договора по смс
- Какой документ закрепляет право получения документов
- Бви можно ли подать заявление на бви в несколько вузов 2021
- Кто по регламенту компании готовит заявку на основной договор этажи
- Если человек забрал заявление и претензий не имеет все равно заведут дело