
Как обеспечить связь между массивами или структурами и функциями
Обновлено: 30.06.2024
Первая часть лабораторного цикла включает в себя 9 работ, направленных на получение навыков использования основных структур данных и алгоритмов их обработки.
Лабораторные работы ориентированы на применение языка С++, хотя может быть использован и другой язык программирования.
Рекомендуемая литература
1. Вирт Н. Алгоритмы и структуры данных.: Пер. С англ. - М.: Мир, 2001.
2. Топп У., Форд У. Структуры данных в С++. 1999.
3. Седжвик Р. Фундаментальные алгоритмы на C++. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск. 2001.
4. Хэзфилд Р., Кирби Л. Искусство программирования на C. Фундаментальные алгоритмы, структуры данных и примеры приложений. 2001.
5. Подбельский В.В. Язык Си++. - М.: Финансы и статистика, 1995.
Требования к оформлению отчетов по лабораторным работам
Отчет по лабораторной работе должен содержать название работы, предварительно составленный в соответствии с заданием текст программы, необходимый для допуска к выполнению работы, текст отлаженной работающей программы, результаты выполнения программы и выводы для тех пунктов задания, для которых это требуется.
Лабораторная работа №1
Массивы автоматические, статические и динамические
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить в функции main() переменные и массивы по таблице 1 в соответствии с вариантом:
1. Одномерный символьный массив;
2. Указатель на тип char ;
3. Статический одномерный массив целых чисел;
4. Указатель на массив целых чисел;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный массив плавающих чисел;
2. Указатель на тип float ;
3. Статический одномерный массив беззнаковых целых чисел;
4. Указатель на массив unsigned int ;
5. Трехмерный массив символов;
6. Указатель на двумерный массив символов.
1. Одномерный массив целых чисел;
2. Указатель на тип int ;
3. Статический одномерный символьный массив;
4. Указатель на массив символов;
5. Трехмерный массив плавающих чисел;
6. Указатель на двумерный массив плавающих чисел.
1. Одномерный символьный массив;
2. Указатель на тип char ;
3. Статический одномерный массив типа double ;
4. Указатель на массив типа double ;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный символьный массив;
2. Указатель на тип char ;
3. Статический одномерный массив длинных чисел;
4. Указатель на массив длинных целых чисел;
5. Трехмерный массив плавающих чисел;
6. Указатель на двумерный массив плавающих чисел.
1. Одномерный массив целых чисел;
2. Указатель на тип int ;
3. Статический одномерный массив плавающих чисел;
4. Указатель на массив плавающих чисел;
5. Трехмерный массив символов;
6. Указатель на двумерный массив символов.
1. Одномерный массив длинных целых чисел;
2. Указатель на тип long int ;
3. Статический одномерный массив символов;
4. Указатель на массив символов;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный массив типа double ;
2. Указатель на тип double ;
3. Статический одномерный массив беззнаковых целых чисел;
4. Указатель на массив unsigned int ;
5. Трехмерный массив символов;
6. Указатель на двумерный массив символов.
1. Одномерный массив типа float ;
2. Указатель на тип float ;
3. Статический одномерный массив символов;
4. Указатель на массив символов;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный массив беззнаковых целых чисел;
2. Указатель на тип unsigned int ;
3. Статический одномерный массив символов;
4. Указатель на массив символов;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный символьный массив;
2. Указатель на тип char ;
3. Статический одномерный массив коротких целых чисел;
4. Указатель на массив коротких целых чисел;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный массив типа float ;
2. Указатель на тип float ;
3. Статический одномерный массив символов;
4. Указатель на массив символов;
5. Трехмерный массив unsigned int ;
6. Указатель на двумерный массив беззнаковых целых чисел.
1. Одномерный массив коротких целых чисел;
2. Указатель на тип short int ;
3. Статический одномерный массив символов;
4. Указатель на массив символов;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный символьный массив;
2. Указатель на тип char ;
3. Статический одномерный массив плавающих чисел;
4. Указатель на массив плавающих чисел;
5. Трехмерный массив целых чисел;
6. Указатель на двумерный массив целых чисел.
1. Одномерный массив типа double ;
2. Указатель на тип double ;
3. Статический одномерный массив целых чисел;
4. Указатель на массив целых чисел;
5. Трехмерный массив символов;
6. Указатель на двумерный массив символов.
1. Одномерный массив целых чисел;
2. Указатель на тип int ;
3. Статический одномерный массив типа double ;
4. Указатель на массив типа double ;
5. Трехмерный массив символов;
6. Указатель на двумерный массив символов.
2. В функции main() выполнить следующие действия:
Проверить содержимое массива №1 (с помощью цикла for и операции вывода cout >).
Еще раз проверить содержимое этого массива, сделать выводы.
Присвоить указателю №2 адрес массива №1, вывести на экран адреса массива и указателя и содержимое указателя. Сделать выводы.
Повторить пункт 3 для указателя, содержащего адрес массива. Сделать выводы.
Повторить пункты 1 – 3 для статического массива №3. Сделать выводы.
Используя имеющийся указатель №2, создать динамический массив и повторить для него пункты 1 – 3. Сделать выводы.
Удалить динамический массив. Используя указатель №4, создать двумерный динамический массив и повторить для него пункты 2, 3. Сделать выводы. Удалить двумерный динамический массив.
Вывести на экран любой из элементов трехмерного массива №5, используя операцию индексации.
Повторить пункт 9, используя имя массива как указатель и операцию доступа по указателю.
Присвоить указателю №6 на двумерный массив адрес трехмерного массива №5. Повторить для этого указателя пункт 10. Сделать выводы.
Сохранить файл с текстом программы для следующей работы.
По каким признакам классифицируются структуры данных?
К какой группе структур данных относятся автоматические массивы?
Какую информацию можно извлечь из типа данных?
К какой группе структур данных относятся статические массивы?
К какой группе структур данных относятся динамические массивы?
Что такое указатели?
Какие операции можно выполнять над указателями?
В чем заключается связь между указателями и массивами?
Какие операции обязательны при работе с динамическими массивами?
Свойства динамических массивов.
В чем заключается отличие между автоматическими и статическими массивами?
Можно ли изменить размер динамического массива при исполнении программы? Если да, то как это сделать?
Какое требование нужно соблюдать при присваивании адреса массива указателю?
Какие ограничения накладываются на определение многомерных динамических массивов?
В чем заключается отличие между именем массива и указателем?
Лабораторная работа №2
Массивы и структурированные типы данных
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить структурный тип, содержащий следующие поля:
символьный массив, используемый для хранения строки, например, с именем студента,
указатель на тип char – для организации динамического массива, хранящего строку, например, с фамилией студента.
Остальные поля выбрать по варианту, приведенному в таблице 2.
Использовать одну из переменных для хранения некоторого идентификатора (номера); указатель на несимвольный тип – для организации динамического массива целых или плавающих чисел; другую переменную – для хранения размера этого массива;
Дополнить структурный тип любыми полями по своему выбору.
1. Переменная длинного целого типа;
2. Указатель на целый тип;
3. Переменная целого типа.
1. Переменная плавающего типа;
2. Указатель на тип float ;
3. Переменная беззнакового целого типа.
1. Переменная целого типа;
2. Указатель на тип int ;
3. Переменная плавающего типа.
1. Переменная типа double ;
2. Указатель на тип double ;
3. Переменная целого типа.
1. Переменная беззнакового длинного целого типа;
2. Указатель на длинный целый тип;
3. Переменная плавающего типа.
1. Переменная целого типа;
2. Переменная плавающего типа;
3. Указатель на плавающий тип.
1. Переменная длинного целого типа;
2. Указатель на тип long int ;
3. Переменная целого типа.
1. Переменная беззнакового целого типа;
2. Указатель на тип unsigned int ;
3. Переменная символьного типа.
1. Переменная типа float ;
2. Указатель на тип float ;
3. Переменная символьного типа.
1. Переменная беззнакового целого типа;
2. Указатель на тип unsigned int ;
3. Переменная целого типа.
1. Переменная символьного типа;
2. Указатель на короткий целый тип;
3. Переменная короткого целого типа.
1. Переменная типа float ;
2. Указатель на тип float ;
3. Переменная типа unsigned int .
1. Переменная короткого целого типа;
2. Указатель на тип short int ;
3. Переменная символьного типа.
1. Переменная плавающего типа;
2. Указатель на плавающий тип;
3. Переменная целого типа.
1. Переменная типа double ;
2. Указатель на тип double ;
3. Переменная символьного типа.
1. Указатель на тип int ;
2. Переменная типа double ;
3. Переменная символьного типа.
2. Определить функции:
заполнения массива чисел;
вывода на экран массива чисел;
ввода информации в строки имени и фамилии и другие поля;
вывода на экран всех полей структуры, кроме массива чисел;
функцию освобождения динамической памяти.
У половины функций, по выбору студента, одним из аргументов должен быть указатель на структуру, у второй половины – ссылка на структуру.
3. Определить функцию main(), в которой создать:
объект ранее определенного структурного типа
указатель на этот структурный тип.
С помощью указателя создать динамический массив объектов структурного типа из 3-х – 4-х элементов.
Для объекта последовательно вызывать функции инициализации, заполнения массива чисел, ввода данных в остальные поля, показа массива, показа полей.
Для каждого элемента массива структур выполнить в цикле (for) функции инициализации, заполнения массива и ввода данных.
Вывести на экран содержимое полей каждого элемента массива структур в цикле (for) с помощью соответствующих функций.
В конце функции main() вызвать функцию освобождения памяти для объекта структурного типа и в цикле для каждого элемента массива объектов.
Удалить динамический массив.
Сохранить файл с текстом программы для следующей работы.
Создать в функции main() блок, в котором определить локальный объект структурного типа. Ввести данные в поля локального объекта.
Попытаться вывести на экран содержимое полей локального объекта за пределами блока. Сделать выводы.
Что представляет собой структурный тип данных?
Данные каких типов могут входить в состав структур?
Данные каких типов не могут входить в состав структур?
По каким признакам классифицируются структуры данных?
К какой группе структур данных относятся автоматические массивы?
Какую информацию можно извлечь из типа данных?
К какой группе структур данных относятся статические массивы?
К какой группе структур данных относятся динамические массивы?
Что такое указатели?
Какие операции можно выполнять над указателями?
В чем заключается связь между указателями и массивами?
Какие операции обязательны при работе с динамическими массивами?
Каковы свойства динамических массивов?
Как обеспечить связь между массивами или структурами и функциями?
Лабораторная работа №3
Похожие документы:
Структуры и алгоритмы обработки данных литература
Структуры и алгоритмы обработки данных Лектор: Колинько Павел Георгиевич, кафедра . Н. Алгоритмы и структуры данных. – СПб., 2001 (и более ранние издания). Ахо Дж., Хопкрофт А., Ульман Дж. Структуры данных и алгоритмы .
“СТРУКТУРЫ И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ”
“СТРУКТУРЫ И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ” (2)
“СТРУКТУРЫ И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ” (3)
“СТРУКТУРЫ И АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ” (4)
среда, 7 января 2015 г.
Структуры в языке Си.
Видео урок.
Прежде чем говорить о структурах, вспомним массивы. Как вы, наверное, помните, массивы предназначены для хранения однотипных данных. Другими словами каждый элемент массива представляет собой значение определенного типа: целое число, символ, строка. Но зачастую, в программах, требуется хранить в одном месте данные разных типов. В качестве примера, в этом уроке будем рассматривать программу каталог книг. Про каждую книгу нам известно: название, автор, год издания, количество страниц, стоимость.
Типы переменных, используемые для хранения подобных данных очевидны:
char[] – автор, название.
int – год издания, количество страниц.
float – стоимость.
На ум сразу приходит следующий вариант реализации. Завести для каждого отдельного качества отдельный массив. Например:
int book_date[100]; // дата издания
int book_pages[100]; // количество страниц
char book_author[100][50]; // автор
char book_title[100][100]; // название книги
float book_price[100]; //стоимость
Тогда, обращаясь по i -му номеру к соответствующему массиву, мы могли бы получить требуемую информацию. Например, вот так мы могли бы вывести на экран автора, название и количество страниц четвертой книги (не забываем, что нумерация элементов массива начинается с нуля).
Оставим пока что эту реализацию, и посмотрим, как выполнить такую же задачу с использованием структур. Но прежде всего, определим, что такое структура.

Задумаемся, что такое структура в обычном понимании этого слова. Структура – это строение или внутренне устройство какого-либо объекта.
Структура в языке Си – это тип данных, создаваемый программистом, предназначенный для объединения данных различных типов в единое целое.
Прежде чем использовать в своей программе структуру, необходимо её описать, т.е. описать её внутреннее устройство. Иногда это называю шаблоном структуры. Шаблон структуры описывается следующим образом.
На картинке слева, мы описали шаблон структуры с именем point . В любом шаблоне структуры можно выделить две основных части: заголовок (ключевое слово struct и имя структуры) и тело (поля структуры, записанные внутри составного оператора).
Точка с запятой в конце обязательна, не забывайте про неё.
Возвращаясь к нашему примеру, опишем структуру book с полями date, pages, author, title, price соответствующих типов.
struct book
int date; // дата издания
int pages; // количество страниц
char author[50]; // автор
char title[100]; // название книги
float price; // стоимость
>;
Попутно отметим, что в качестве полей структуры могут выступать любые встроенные типы данных и даже другие структуры. Подробнее об этом я расскажу в другом уроке. На имена полей накладываются те же ограничения, что и на обычные переменные. Внутри одной структуры не должно быть полей с одинаковыми именами. Имя поля не должно начинаться с цифры. Регистр учитывается.
После того, как мы описали внутреннее устройство структуры, можно считать, что мы создали новый тип данных, который устроен таким вот образом. Теперь этот тип данных можно использовать в нашей программе.
ПРИМЕЧАНИЕ: Обычно структуры описываются сразу после подключения заголовочных файлов. Иногда, для удобства, описание структур выносят в отдельный заголовочный файл.
Объявление структурной переменной происходит по обычным правилам.
struct book kniga1;
Такое объявление создает в памяти переменную типа book , с соответствующими полями.

Отличие структурной переменной от обычной переменной удобно проиллюстрировать на примере с коробками. Считаем, что обычная переменная это просто коробка, в которую можно положить объект определенного типа, например, целое число.
Структурная переменная, это тоже коробка, внутри которой есть отдельные секции для хранения различных данных. Количество этих секций и типы данных, которые мы можем там хранить, задаются шаблоном структуры. На рисунке я постарался схематично изобразить устройство структурной переменной.
Отмечу, что я сознательно не касаюсь вопроса о том, как хранится структура в памяти, так как считаю, что для новичков эти тонкости будут излишни.
Кроме того, еще одну удобную интерпретацию структуры дает нам книга K&R. Можно думать о ней, как о строчке в таблице, где столбцами выступают поля структуры.

Если кто-то имел дело с реляционными базами данных (MySQL, Oracle), то вам эта такая интерпретация будет очень знакома.
Хорошо, переменную мы объявили. Самое время научиться сохранять в неё данные, иначе, зачем она нам вообще нужна. Мы можем присвоить значения сразу всем полям структуры при объявлении. Это очень похоже на то, как мы присваивали значения массиву при его объявлении.

Важный момент. Порядок и тип аргументов, должен совпадать с порядком и типом полей, описанных в шаблоне структуры. В нашем примере мы сначала записали дату, потом количество страниц, имя автора, название книги и стоимость. Пропустить какой-то аргумент нельзя, но можно не объявлять несколько последних. Т.е. вполне допустима следующая конструкция:
Для обращения к отдельным полям структуры используется оператор доступа "." . Да-да, обычная точка.
Примеры:
kniga1.pages = 250; // записываем в поле pages переменной kniga1
// значение 250.
printf( "%s-%s %d page" , kniga1.author, kniga1.title, kniga1.pages);
Задание: Проверить, что хранится в полях структуры до того, как им присвоено значение.
Сейчас, в одной переменной типа book храниться вся информация об одной книге. Но так как в каталоге вряд ли будет всего одна книга, нам потребуется много переменных одного и того же типа book . А значит что? Правильно, нужно создать массив таких переменных, то есть массив структур. Делается это аналогично, как если бы мы создавали массив переменных любого стандартного типа.
Каждый элемент этого массива это переменная типа book . Т.е. у каждого элемента есть свои поля date, pages, author, title, price . Тут-то и удобно вспомнить о второй интерпретации структуры. В ней массив структур будет выглядеть как таблица.
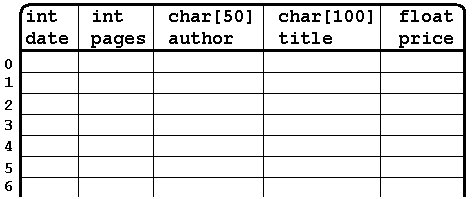
Используя массив структур получить информацию об отдельной книге можно следующим образом.
Обращаясь к kniga[3].author мы обращаемся к четвертой строке нашей таблицы и столбику с именем author . Удобная интерпретация, не правда ли?
На данном этапе мы научились основам работы со структурами. Точнее мы переписали с использованием структур тот же код, который использовал несколько массивов. Кажется, что особой разницы нет. Да, на первый взгляд это действительно так. Но дьявол, как обычно, кроется в мелочах.
Например, очевидно, что в нашей программе нам часто придется выводить данные о книге на экран. Разумным решением будет написать для этого отдельную функцию.
Если бы мы пользуемся несколькими массивами, то эта функция выглядела бы примерно так:
void print_book ( int date, int pages, char *author,
char *title, float price)
printf( "%s-%s %d page.\nDate: %d \nPRICE: %f rub.\n" ,
author, title, pages,date, price);
>
А её вызов выглядел как-то вот так:
Не очень-то и компактно получилось, как вы можете заметить. Легче было бы писать каждый раз отдельный printf(); .
Совсем другое дело, если мы используем структуры. Так как структура представляет собой один целый объект (большую коробку с отсеками), то и передавать в функцию нужно только его. И тогда нашу функцию можно было бы записать следующим образом:
void sprint_book (book temp)
printf( "%s-%s %d page.\nDate: %d \nPRICE: %f rub." ,
temp.author,temp.title, temp.pages,
temp.date, temp.price);
>
И вызов, выглядел бы приятнее:
Вот это я понимаю, быстро и удобно, и не нужно каждый раз писать пять параметров. А представьте теперь, что полей у структуры бы их было не 5, а допустим 10? Вот-вот, и я о том же.
Стоит отметить, что передача структурных переменных в функцию, как и в случае обычных переменных осуществляется по значению. Т.е. внутри функции мы работаем не с самой структурной переменной, а с её копией. Чтобы этого избежать, как и в случае переменных стандартных типов используют указатель на структуру. Там есть небольшая особенность, но об этом я расскажу в другой раз.
Кроме того, мы можем присваивать структурные переменные, если они относятся к одному и тому же шаблону. Зачастую это очень упрощает программирование.
Например, вполне реальная задача для каталога книг, упорядочить книги по количеству страниц.
Если бы мы использовали отдельные массивы, то сортировка выглядела бы примерно так.
for ( int i = 99; i > 0; i--)
for ( int j = 0; j
if (book_pages[j] > book_page[j+1])
//меняем местами значения во всех массивах
int temp_date;
int temp_pages;
char temp_author[50];
char temp_title[100];
float temp_price;
temp_date = book_date[i];
book_date[i] = book_date[j];
book_date[j] = temp_date;
temp_pages = book_pages[i];
book_pages[i] = book_pages[j];
book_pages[j] = temp_pages;
//и так далее для остальных трех массивов
>
Совсем другой дело, если мы используем структуры.
for ( int i = 99; i > 0; i--)
for ( int j = 0; j
if (knigi[j].pages > knigi[j+1].pages)
struct book temp;
temp = knigi[j]; //присваивание структур
knigi[j] = knigi[j+1];
knigi[j+1] = temp;
>
Неоспоримое удобство, не правда ли?
Надеюсь, у меня получилось достаточно убедительно показать преимущества использования структур.
На этой радостной ноте, я и завершаю сегодняшний урок.
Практическое задание:
- Чтение данных в структуру из файла. В файле запись о каждой книге хранится в следующем формате:
Khnut||Art of programming. T.1||1972||129||764||234.2
Ritchie||The C Programming Language. 2 ed.||1986||80||512||140.5
Cormen||Kniga pro algoritmy||1996||273||346||239
Требования к оформлению отчетов по лабораторным работам .
Работа №1. Массивы автоматические, статические и динамические.
Работа №2. Массивы и структурированные типы данных.
Работа №4. Очереди и стеки.
Работа №5. Связные списки.
Работа №6. Сортировка массивов.
Работа №7. Сортировка списков.
Работа №8. Исследование эффективности алгоритмов сортировки для массивов
Работа №9. Поиск в массивах и списках.
Работа №10. Деревья.
Лабораторный цикл включает в себя 10 работ, направленных на получение навыков работы с основными структурами данных и алгоритмами их обработки.
Лабораторные работы ориентированы на применение языка С++, хотя может быть использован и любой другой язык программирования.
1. Вирт Н. Алгоритмы и структуры данных.: Пер. С англ. - М.: Мир, 2001.
2. Топп У., Форд У. Структуры данных в С++. 1999.
3. Седжвик Р. Фундаментальные алгоритмы на C++. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск. 2001.
4. Хэзфилд Р., Кирби Л. Искусство программирования на C. Фундаментальные алгоритмы, структуры данных и примеры приложений. 2001.
Требования к оформлению отчетов по лабораторным работам
Отчет по лабораторной работе должен содержать название работы, предварительно составленный в соответствии с заданием текст программы, необходимый для допуска к выполнению работы, текст отлаженной работающей программы, результаты выполнения программы и выводы для тех пунктов задания, для которых это требуется.
Лабораторная работа №1
Массивы автоматические, статические и динамические
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить в функции main() переменные и массивы по таблице 1 в соответствии с вариантом:
Указатель на тип char ;
Указатель на тип float ;
массив целых чисел;
массив беззнаковых целых
Указатель на массив целых
Указатель на массив unsigned
Трехмерный массив целых
Трехмерный массив символов;
Указатель на двумерный
Указатель на двумерный
массив целых чисел.
Одномерный массив целых
Указатель на тип int ;
Указатель на тип char ;
массив типа double ;
Указатель на массив
Указатель на массив типа
Трехмерный массив целых
Указатель на двумерный
Указатель на двумерный
массив плавающих чисел.
массив целых чисел.
Одномерный массив целых
Указатель на тип char ;
Указатель на тип int ;
массив длинных чисел;
массив плавающих чисел;
Указатель на массив длинных
Указатель на массив
Трехмерный массив символов;
Указатель на двумерный
Указатель на двумерный
массив плавающих чисел.
Одномерный массив типа
длинных целых чисел;
Указатель на тип long int ;
Указатель на тип double ;
массив беззнаковых целых
Указатель на массив
Указатель на массив unsigned
Трехмерный массив целых
Трехмерный массив символов;
Указатель на двумерный
Указатель на двумерный
массив целых чисел.
Одномерный массив типа
беззнаковых целых чисел;
Указатель на тип float ;
Указатель на тип unsigned int ;
Указатель на массив
Указатель на массив символов;
Трехмерный массив целых
Трехмерный массив целых
Указатель на двумерный
Указатель на двумерный
массив целых чисел.
массив целых чисел.
Одномерный массив типа float ;
Указатель на тип float ;
Указатель на тип char ;
массив коротких целых
Указатель на массив символов;
Трехмерный массив unsigned
Указатель на массив
коротких целых чисел;
Указатель на двумерный
Трехмерный массив целых
массив беззнаковых целых
Указатель на двумерный
массив целых чисел.
коротких целых чисел;
Указатель на тип short int ;
Указатель на тип char ;
массив плавающих чисел;
Указатель на массив
Указатель на массив
Трехмерный массив целых
Трехмерный массив целых
Указатель на двумерный
Указатель на двумерный
массив целых чисел.
массив целых чисел.
Одномерный массив типа
Одномерный массив целых
Указатель на тип double ;
Указатель на тип int ;
массив целых чисел;
массив типа double ;
Указатель на массив целых
Указатель на массив типа
Трехмерный массив символов;
Указатель на двумерный
Указатель на двумерный
2. В функции main() выполнить следующие действия:
1. Проверить содержимое массива №1 (с помощью цикла for и операции вывода cout
2. Ввести данные в массив №1 (с помощью цикла for и операции ввода cin>>).
3. Еще раз проверить содержимое этого массива, сделать выводы.
4. Присвоить указателю №2 адрес массива №1, вывести на экран адреса массива и указателя и содержимое указателя. Сделать выводы.
5. Повторить пункт 3 для указателя, содержащего адрес массива. Сделать выводы.
6. Повторить пункты 1 – 3 для статического массива №3. Сделать выводы.
7. Используя имеющийся указатель №2, создать динамический массив и повторить для него пункты 1 – 3. Сделать выводы.
8. Удалить динамический массив. Используя указатель №4, создать двумерный динамический массив и повторить для него пункты 2, 3. Сделать выводы. Удалить двумерный динамический массив.
9. Вывести на экран любой из элементов трехмерного массива №5, использую операцию индексации.
10. Повторить пункт 9, используя имя массива как указатель и операцию доступа по указателю.
11. Присвоить указателю №6 на двумерный массив адрес трехмерного массива №5. Повторить для этого указателя пункт 10. Сделать выводы.
Сохранить файл с текстом программы для следующей работы.
1. По каким признакам классифицируются структуры данных?
2. К какой группе структур данных относятся автоматические массивы?
4. Какую информацию можно извлечь из типа данных?
5. К какой группе структур данных относятся статические массивы?
6. К какой группе структур данных относятся динамические массивы?
7. Что такое указатели?
8. Какие операции можно выполнять над указателями?
9. В чем заключается связь между указателями и массивами?
10. Какие операции обязательны при работе с динамическими массивами?
11. Свойства динамических массивов.
12. В чем заключается отличие между автоматическими и статическими массивами?
13. Можно ли изменить размер динамического массива при исполнении программы? Если да, то как это сделать?
14. Какое требование нужно соблюдать при присваивании адреса массива указателю?
15. Ограничения, накладываемые на определение многомерных динамических массивов.
16. В чем заключается отличие между именем массива и указателем?
Лабораторная работа №2
Массивы и структурированные типы данных
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить структуру (структурный тип), содержащую поля, определяемые вариантом, приведенным в табл. 1. Заменить все двумерные и трехмерные массивы и указатели одномерными. Заменить все несимвольные массивы на переменные тех же типов.
Символьный массив использовать для хранения строки, например, с именем студента, указатель на тип char – для организации динамического массива, хранящего строку, например, с фамилией студента.
Использовать одну из переменных для хранения некоторого идентификатора (номера); один из указателей на несимвольный тип – для организации динамического массива целых или плавающих чисел; другую переменную – для хранения размера этого массива;
Дополнить структурный тип любыми полями по своему выбору.
2. Определить функции:
• заполнения массива чисел;
• вывода на экран массива чисел;
• ввода информации в строки имени и фамилии и другие поля;
• вывода на экран всех полей структуры, кроме массива чисел;
• функцию освобождения динамической памяти.
У половины функций, по выбору студента, одним из аргументов должен быть указатель на структуру, у второй половины – ссылка на структуру.
3. Определить функцию main(), в которой создать:
• объект ранее определенного структурного типа
• указатель на этот структурный тип.
С помощью указателя создать динамический массив объектов структурного типа из 3-х – 4-х элементов.
Для объекта последовательно вызывать функции инициализации, заполнения массива чисел, ввода данных в остальные поля, показа массива, показа полей.
Для каждого элемента массива структур выполнить в цикле (for) функции инициализации, заполнения массива и ввода данных.
Вывести на экран содержимое полей каждого элемента массива структур в цикле (for) с помощью соответствующих функций.
В конце функции main() вызвать функцию освобождения памяти для объекта структурного типа и в цикле для каждого элемента массива объектов.
Удалить динамический массив.
Сохранить файл с текстом программы для следующей работы.
Создать в функции main() блок, в котором определить локальный объект структурного типа. Ввести данные в поля локального объекта.
Попытаться вывести на экран содержимое полей локального объекта за пределами блока. Сделать выводы.
1. Что представляет собой структурный тип данных?
2. Данные каких типов могут входить в состав структур?
3. Данные каких типов не могут входить в состав структур?
4. По каким признакам классифицируются структуры данных?
5. К какой группе структур данных относятся автоматические массивы?
7. Какую информацию можно извлечь из типа данных?
8. К какой группе структур данных относятся статические массивы?
9. К какой группе структур данных относятся динамические массивы?
10. Что такое указатели?
11. Какие операции можно выполнять над указателями?
12. В чем заключается связь между указателями и массивами?
13. Какие операции обязательны при работе с динамическими массивами?
14. Свойства динамических массивов.
15. Как обеспечить связь между массивами или структурами и функциями?
Лабораторная работа №3
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить функции записи и считывания структуры для двоичного и текстового файлов. У всех функций одним из аргументов должна быть ссылка на структурный тип, у функций работы с двоичными файлами еще одним аргументом должен быть указатель на тип FILE.
Использовать структурный тип и функции ввода и вывода на экран данных, определенные в программе к лабораторной работе №2.
2. Определить глобальные указатели на тип FILE для функций работы с двоичными файлами.
3. Определить функцию main(), в которой создать:
• указатели на тип FILE для функций работы с текстовыми файлами;
• указатель на структурный тип для организации динамического массива структур;
• первый динамический массив структур небольшого размера (3 – 4 элемента)
– для ввода данных и их сохранения в файлах;
• второй динамический массив структур такого же размера – для считывания данных из текстового файла;
• третий динамический массив структур – для считывания данных из двоичного файла.
4. Ввести данные в элементы первого динамического массива с помощью функций, разработанных в лабораторной работе №2.
5. Сохранить содержимое элементов массива структур в текстовом и двоичном файлах.
6. Считать содержимое текстового файла в элементы второго массива и вывести на экран. Сравнить содержимое первого и второго массивов.
7. Считать содержимое двоичного файла в элементы третьего массива и вывести на экран. Сравнить содержимое первого и третьего массивов.
Сохранить файл с тестом программы для последующих работ.
1. Что такое файл?
2. К какой группе структур данных относятся файлы?
3. Какие действия необходимо выполнить для работы с файлом?
4. Различаются ли файлы по типам?
5. Как в программах устанавливается связь с файлами?
6. Какие способы организации связи с файлами вам известны?
7. Какие операции можно выполнять над файлами?
8. Как открыть файл для записи?
9. Как открыть файл для считывания?
10. Какая функция позволяет узнать длину файла?
11. Как проверить, можно ли произвести запись в выбранный файл?
12. Можно ли считать данные из произвольного места в файле? Если да, то как это сделать?
13. Можно ли перемещаться по файлу? Если да, то с помощью какой функции?
14. Чем отличается запись действительных чисел в текстовый и двоичный файлы?
15. Как обеспечить связь между файлами и функциями?
Лабораторная работа №4
Очереди и стеки
Разработать программу в соответствии с заданием к лабораторной работе.
1. Определить массив, который будет использован для организации очереди
и стека. Тип массива выбрать по таблице №1 – массив №1.
Определить структурный тип, используемый для представления элементов стека, организованного в виде динамической цепочки звеньев.
2. Разработать функции занесения и извлечения данных для простой очереди, циклической очереди, стека на основе массива и на основе связного списка. Обратить внимание на аргументы функций. Можно использовать перегрузку функций.
3. В функции main() проверить работу простой и циклической очередей и обоих вариантов организации стека. Для простой очереди и стека на основе массива добиться их переполнения. Сделать то же самое для циклической очереди. Сделать выводы.
4. Проконтролировать при операциях занесения и извлечения данных изменение индексов записи и считывания для простой и циклической очередей. Проконтролировать изменение индекса вершины стека для массива и адреса вершины стека для списка. Сделать выводы.
Сохранить файл с тестом программы для последующих работ.
Разработать функции занесения и извлечения данных для приоритетной очереди. Проверить работу приоритетной очереди с помощью этих функций.
Рекомендации к выполнению работы.
Функция main() может содержать цикл, например, с постусловием, внутри которого может происходить опрос клавиатуры и выполнение вставки в очередь (стек) или извлечение, в зависимости от нажатой клавиши.

Предлагаем укрепить (или получить) знания о базовых структурах данных. Эти понятия являются основой всего, что связано с программами. Вспомните азы, а если не знаете – получите их. Они пригодятся в работе, а если есть цель найти ее, то и при прохождении интервью. Укажите, что вы знаете составляющие структуры данных, их применение, и это поможет в поиске работы. Потратив немного времени, вы приятно удивите интервьюера, начальника или коллег по работе.
Основополагающие сведения о структурах данных
Структуры данных делятся на:
- линейные (стеки, очереди, массивы) – элементы выстраиваются в последовательность либо линейный список. Также линейны и обходы узлов;
- нелинейные (графы, деревья) – данные выстраиваются без какой-либо последовательности. Также не линейны и обходы узлов.
Коснемся основных действий. Данные можно получить, найти, добавить, удалить. Для реализации этих целей существует много разнообразных структур данных. Каждая отдельно взятая более эффективна в одних вопросах и менее эффективна в других. Потому разработчик должен понимать функциональные составляющие каждой структуры. Грамотное применение функциональных свойств структуры данных ускорит решение любой поставленной задачи.
Приходится часто искать информацию – укажите одну разновидность. Если нужно постоянно что-либо вставлять – укажите другую. А если частенько приходится выполнять действия по перестановке и удалению – укажите третье решение.
Базовые термины
Перед изучением структуры данных кратко коснемся их основы – терминов, а затем перейдем к применению. К ним относятся:
- Интерфейс – определенный набор операций, поддерживающих структуру данных. Он присущ каждой структуре. Интерфейс может предоставлять только перечень поддерживаемых операций, тип принимаемых параметров и возвращает тип этих операций.
- Реализация – обеспечивает внутреннее представление структуры данных, помогает в определении алгоритмов, которые используются в операциях.
Характеристики
Важными характеристиками структур данных являются:
- Корректность – она должна грамотно реализовывать свой интерфейс.
- Сложность времени – должно использоваться минимальное количество времени на выполнение операций.
- Сложность пространства – при проведении операций память должна использоваться минимально.
Какие проблемы можно решить с помощью структуры данных
В связи с тем, что приложения становятся все более сложными, а количество составляющей информации в них постоянно растет, то возникают три проблемы:
- замедление процесса поиска в связи с ростом данных;
- ограниченная скорость процессоров. Несмотря на то, что она достаточно высокая, с ростом объема информации и она ограничивается;
- многократные запросы через поиск на веб-серверах вызывают сбои в их работе.
Структуры данных помогают в решение вышеперечисленных проблем. Данные можно организовать в структуры таким образом, что поиск будет осуществляться практически мгновенно.
Случаи выполнения
Чтобы провести сравнение временных промежутков, необходимых для выполнения различной структуры, используются следующие случаи:
- худший – сценарий, при котором для выполнения конкретной операции потребуется максимальное время, которое только возможно;
- средний – сценарий, при котором на выполнение операции отводится среднее время;
- наилучший – сценарий, который отображает кратчайший промежуток времени, необходимый для выполнения операции.
Основные виды структур
К основным видам структуры данных относятся:
Массивы
Это наипростейшие и широко используемые структуры данных, в которых элементы следуют один за другим. Представляет собой контейнер, в котором может храниться фиксированное количество однотипных компонентов.
- элементами называют все компоненты, хранящиеся в массиве;
- индексы – местонахождение каждого элемента в массиве выражается целым числовым индексом, используемом для его идентификации.
Размерность массива определяет количество индексов в нем. Они бывают одномерными (называют векторами) и многомерными (массив в середине массива). Массивы могут объявляться разными способами на различных языках программирования.
Некоторые структуры являются производными массивов (стеки, очереди). В массиве каждый элемент имеет индекс (положительное целое числовое значение), соответствующий тому, какую позицию в массиве он занимает.
Язык программирования определяет, с какого значения в массиве начинается нумерация. Во многих языках начальным индексом массива определен 0.
- статическими — характеризуются однородностью данных;
- динамическими – характеризуются непостоянством размера, который может меняться в ходе выполнения программы. Это усложняет процесс, ухудшает быстроту действий, но работа с информацией становится более гибкой;
- гетерогенными – характеризуется неоднородностью данных.
Основные операции, которые поддерживаются массивами:
- Traverse – выставляет один за одним все компоненты массива;
- Insert – добавляет один или несколько элементов по указанному индексу;
- Get – производит возврат элемента по указанному индексу;
- Delete – выполняет удаление элемента по указанному индексу;
- Size – позволяет узнать общую численность элементов, содержащихся в массиве.
Списки
Список является абстрактным типом данных. Существует несколько их разновидностей. Рассмотрим наиболее популярные:
Связные (связанные) списки
Связной список представляет собой массив с конечным множеством элементов (отдельных объектов) и указателями на них.
Каждый объект содержит:
- поле информации (тип данных может быть любым);
- ссылки (указатели) на последующий узел.
Таким образом упорядоченные элементы связного списка связаны друг с другом указателями. Вместе эти группы образуют последовательность.
Как и массив, список лежит в основе понятия классической структуры данных. Их функциональные особенности часто сравнивают, т.к. большинство других структур могут быть реализованы с помощью массивов или связных списков. Последний отличается от массива структурной гибкостью. Доступ к спискам осуществляется последовательно, а к массивам – произвольно.
Связанные списки бывают следующих видов:
- Однонаправленные (односвязные) – каждый узел сохраняет адрес либо ссылку на тот узел, который числится следующим. А узел, являющийся последним, содержит последующий адрес либо ссылку как NULL. Линейные однонаправленные списки встречаются чаще всего.
- Двунаправленные (двусвязные) – имеют две ссылки, которые связаны с каждым отдельным узлом (первая указывает на последующий, вторая – на предыдущий).
- Круговые (кольцевые) – все узлы списка соединены в круг при отсутствии в последнем NULL. Является подвидом двух предыдущих видов связных списков. Они могут быть одно- или двусвязными.
Чтобы односвязный список стал круговым, необходимо в его последний узел вставить указатель на первый элемент. Чтобы двунаправленный список преобразовать в кольцевой, следует добавить две ссылки на узлы: первый и последний.
Операции, являющиеся основными:
- InsertAtEnd – вставка заданного элемента в конце списка;
- InsertAtHead – вставка заданного элемента в начало списка;
- Delete – удаление заданного элемента из списка;
- DeleteAtHead – удаление первого элемента в списке;
- Search – возвращение заданного элемента из списка
- isEmpty – в тем случае, когда список пустой, производится возврат True.
Стеки
Отличное сравнение – стопка тарелок. Чтобы из стопки взять тарелку, необходимо вначале снять верхние тарелки. А положить тарелку можно только на верх стопки.
- Push – вставка в стек элемента наверху;
- Pop – удаление верхнего элемента из стека;
- Pip – отображается содержимое;
- isEmpty – происходит возврат True в случае, когда стек пустой;
- Top – возвращает элемент сверху, не удаляя его из стека.
Чаще всего в программировании применяется:
- стек изменений в редакторе кода, позволяющий быстро делать отмену изменений и возвращаться к предыдущему состоянию;
- стек передвижения по страницам в браузере – позволяет быстро переходить по страницам.
Очереди
Если кратко, то очередью является список, в котором добавление новых элементов допустимо строго в его конец, а извлечение – происходит строго с другого конца, который называют началом списка.
Элементы сохраняются последовательно. Но для очереди используется принцип FIFO, а не LIFO.
- Enqueue – вставка элемента в конец очереди;
- Dequeue – удаление элемента из начала очереди;
- isEmpty – будет возвращено значение True, если очередь пуста;
- Top – возвращает первый элемент из очереди.
Дек или двухсторонняя очередь
Дек (двухсторонняя очередь) – это вид списка (стека) с двумя концами. Он позволяет добавлять и извлекать элементы с двух сторон (как в начале, так и в конце).
Дек работает одновременно по FIFO и LIFO. Потому он и относится к отдельной программной единице, которая была получена в результате суммирования стека и очереди.
Графы
Графом называют набор узлов (вершин), соединенных между собой связями (называют ребра, дуги).
- ориентированными – имеют ребра с единственно возможным направлением между парой связанных вершин;
- неориентированными – для каждой дуги переход между вершинами может происходить в любом направлении, а также из каждой вершины можно перейти в другую;
- смешанные – отличаются присутствием дуг, перечисленных выше.
Графы могут иметь различную форму:
- матрицы смежности – таблицы целых чисел, в которой каждая строка либо столбец являются другим узлом на графе. В месте пересечения столбца и строки находится число, указывающее на отношение. Нули указывают, что ребер нет, а единицы – что связи есть;
- матрицы инцидентности;
- списка смежности – представлен списком, в котором левая сторона выступает вершиной, а правая – перечнем всех иных узлов, соединенных с ней;
- списка ребер.
В графах используются алгоритмы обхода:
- в глубину (depth-first search) – обход осуществляется по узлам.
- в ширину (breadth-first search) – поиск осуществляется по уровням;
Стиль дуг граф может быть не только в виде прямой линии, а вершин – выражен в цифрах. Существуют графы, именуемые взвешенными, где ребрам соответствует определенное значение (именуемое его весом). При совпадении концов ребра его называют петлей.
Графы довольно часто используются в транспортных и компьютерных сетях, веб-технологиях. По принципу граф построены социальные сети, где люди являются узлами, а дуги – их связями.
Множества
Хранение данных во множество организовано беспорядочно и без повторяющихся значений. В них можно добавлять и удалять объекты, а также есть еще ряд важнейших функций, позволяющих работать одновременно с двумя наборами функций.
Так, при двух заданных множествах функции выполнят:
- Union (объединение множеств) – объединятся все элементы, принадлежащие им обеим. Результат будет возвращен в качестве нового (не имеющего дубликатов);
- Intersection (пересечение множеств) – будет возвращено новое множество, которому будут принадлежать объекты, имевшиеся в обеих заданных множествах;
- Difference (разница множеств) – будет возвращено множество с элементами, содержавшимися в одном и не повторявшиеся в другом;
- Subset (подмножество) – возвращает булево значение, демонстрирующее содержатся ли в множестве все объекты иного.
Map также именуют ассоциативный массив или словарь. Это структура данных, которая сохраняет данные в связке уникальный ключ/ значение. Чаще всего он используется, когда необходим быстрый поиск информации
С помощью Map можно:
- добавить пару;
- удалить пару;
- изменить пару;
- найти значения, которые связаны с определенными ключами.
Хэш-таблицы
Это структуры, реализующие интерфейс Map, позволяющий сохранять пару (ключ/ значение). Хеширование применяется для нахождения в массиве значения индекса, по которому будет найдено нужное значение.
При детальном рассмотрении можно увидеть, что хэш-таблица является массивом. В нем хэш-функция является индексом.
Коллизией называют хеширование двух вводов, имеющих одинаковый цифровой выход. Цель – уменьшение числа коллизий.
Когда в хэш-таблицу вводится пара ключ/ значение, с уникальным ключом проводится хеширование, после чего он становится числом. Оно в последствии используется в качестве фактического ключа, в котором это значение хранится. При повторной попытке получить доступ к этому же ключу, хеш-функция проведет его обработку и вернет то же числовое значение, которое в дальнейшем будет использовано для нахождения связанного значения. Это способствует быстрому поиску.
Производительность хеширования зависит от:
- функций хеширования;
- параметров хэш-таблиц;
- методов устранения коллизий.
Деревья
Деревом является иерархическая структура данных. Она составлена из узлов (вершин) и дуг (ребер). При близком рассмотрении можно понять, что деревьями являются связанные графы, не имеющие цикличности.
Дереву присущи характеристики:
- Каждое имеет единственную вершину (корневой узел), расположенную сверху и не имеющую предков. Никакая вершина не ссылается на корень, а из него можно достичь любой имеющейся вершины дерева (это следствие свойства связанности древовидной структуры).
- Вершины, которые не имеют потомков (не ссылаются на иные) называются терминальными узлами (листьями).
- Объекты, которые располагаются между вершиной и листьями, называются промежуточными узлами.
- Каждая вершина древовидной структуры имеет лишь единого предка, а если он является корневым – не имеет ни одного предка.
- У корневого узла может быть от нуля или более потомков.
- У каждого дочернего узла может быть от нуля или более дочерних вершин.
Поддеревом называется часть древовидной структуры, которая имеет вершину и имеющиеся потомки.
Существует несколько типов деревьев. Чаще других встречается бинарное дерево. Оно представляет собой структуру данных с иерархией, в которой каждый узел имеет определенное значение (которое является ключом) вместе со ссылками на потомков (слева и справа).
Для деревьев используются следующие методы обхода:
- прямой – осуществляется сверху вниз (начинается с посещения предков и постепенно переходит к потомкам);
- обратный – обход осуществляется снизу вверх (прежде посещаются потомки, потом – предки);
- симметричный – обход осуществляется слева направо (по очереди осуществляется обход поддеревьев главного дерева).
Выражение информации в виде древовидных структур оправдано в том случае, если у нее есть явная иерархия. Иерархически выраженная структура потребуется при работе с данными о географических объектах, служебных должностях и т.д. В таких случаях информацию лучше представлять в виде классических математических деревьев.
Дерево двоичного (бинарного) поиска
Кроме вышеуказанных характеристик деревьев, дереву двоичного поиска характерны еще ряд характеристик:
- Узел может иметь не больше двух детей (потомков).
- Левые потомки меньше текущего узла, что меньше, чем у правых детей.
Бинарные деревья помогают существенно ускорить работу объектами (находить, удалять, добавлять их).
Префиксные деревья (Trie), боры, лучи
Префиксные деревья, именуемые иногда борами и лучами, являются разновидностью древовидных структур. Они особенно эффективны для работы со строками, т.к. обеспечивают быстрый поиск информации. По сути бор является деревом поиска.
Чаще всего боры используют для:
- поиска слов в словарях;
- автозавершений в поисковиках;
- IP-маршрутизации.
Бор хранит данные в узлах. Такие деревья часто используются для хранения слов. Они хранятся в борах сверху вниз – в каждом узле по букве.
Для записи слова необходимо проследовать по ветвям дерева, вписывая за раз по одной букве. Если порядок букв не похож на другие слова в дереве либо слово заканчивается, шаги начинают расходиться. В каждой вершине находится буква (данные) вместе с логическим значением, которое указывает на то, является ли данный узел в слове последним или нет.
Двоичная куча
Так называют полное дерево, у которого в каждом узле до двух детей. У двоичной кучи все уровни до последнего заполнены полностью. В последнем уровне заполнение ведется слева направо.
- максимальной – у родительских узлов ключи всегда больше либо равны тем ключам, которые у детей;
- минимальной – у родительских узлов ключи меньше либо равны ключам у дочерних элементов.
В двоичной куче прослеживается важность порядка между уровнями, но не между узлами одного уровня.
Это вся важная информация о структурах данных программы. Изучайте материал, находите новое и применяйте на практике. Если возникли вопросы – задавайте. Обязательно ответим на них.
Читайте также: