
Виды протоколов файловых систем
Обновлено: 16.05.2024
Хотя это старая файловая система основные элементы используются и современных UNIX системах.
Имена файлов ограничены 14 символами ASCII, кроме косой черты "/" и NUL - отсутствие символа. (в последующих версиях расширены до 255)
Контроль доступа к файлам и каталогам.
Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы.
Используется схема i-узлов.
Не делается различий между разными файлами (текстовыми, двоичными и д.р.).
Поддерживаются символьные специальные файлы (для символьных устройств ввода-вывода).
- Если открыть файл /dev/lp и записать в него данные, то данные будут распечатаны на принтере.
- Если открыть файл /dev/tty и прочитать из него данные, то получим данные, введенные с клавиатуры.
Поддерживаются блочные специальные файлы (для блочных устройств ввода-вывода, например /dev/hd1).
Позволяет монтировать разделы в любое место дерева системы.
Расположение файловой системы UNIX
Количество дисковых блоков
Начало списка свободных блоков диска
При уничтожении суперблока, файловая система становится не читаемой.
Каждый i-узел имеет 64 байта в длину и описывает один файл (в том числе каталог).
Каталог содержит по одной записи для каждого файла.
Каталоговая запись UNIX V7 в 16 байт
Первые 10 дисковых блоков файла хранятся в самом i-узле, при блоке в 1Кбайт, файл может быть 10Кбайт.
Дополнительные блоки для i-узла, в случае больших файлов:
Одинарный косвенный блок - дополнительный блок с адресами блоков файла, если файл не сильно большой, то один из адресов в i-узле указывает на дополнительный блок с адресами. Файл может быть 266Кбайт=10Кбайт+256Кбайт (256Кбайт 3.1.1 Поиск файла
Этапы поиска файла по абсолютному пути /usr/sbin/mc
При использовании относительного пути, например sbin/mc, поиск начинается с рабочего каталога /usr.
3.1.2 Блокировка данных файла
Блокирование осуществляется по блочно.
Стандартом POSIX два типа блокировки:
Блокировка с монополизацией - больше ни один процесс эти блоки заблокировать не может.
Блокировка без монополизации - могут блокировать и другие процессы.
Блокировки данных файла без монополизации
Если процесс К попытается блокировать блок 6 с монополизацией, то сам процесс будет заблокирован до разблокирования блока 6 всеми процессами.
3.1.3 Создание и работа с файлом
fd=creat("abc", mode) - Пример создания файла abc с режимом защиты, указанном в переменной mode (какие пользователи имеют доступ). Используется системный вызов creat.
Успешный вызов возвращает целое число fd - дескриптор файла.
Который хранится в таблице дескрипторов файла, открывшего процесса.
После этого можно работать с файлом, используя системные вызовы write и read.
n=read(fd, buffer, nbytes)
n=write(fd, buffer, nbytes)
У обоих вызовов всего по три параметра:
fd - дескриптор файла, указывающий на открытый файл
buffer - адрес буфера, куда писать или откуда читать данные
nbytes - счетчик байтов, сколько прочитать или записать байт
Теперь нужно по дескриптору получить указатель на i-узел и указатель на позицию в файле для записи или чтения.
Таблица открытых файлов - создана для хранения указателей на i-узел и на позицию в файле. И позволяет родительскому и дочернему процессам совместно использовать один указатель в файле, но для посторонних процессов выделять отдельные указатели.
Связь между таблицей дескрипторов файлов, таблицей открытых файлов и таблицей i-узлов.
3.2 Файловая система BSD
Основу составляет классическая файловая система UNIX.
Особенности (отличие от предыдущей системы):
Увеличена длина имени файла до 255 символов
Было добавлено кэширование имен файлов, для увеличения производительности.
Применено разбиение диска на группы цилиндров, чтобы i-узлы и блоки данных были поближе друг к другу, для каждой группы были свои:
- суперблок
- i-узлы
- блоки данных.
Это сделано для уменьшения перемещений галовок.
Используются блоки двух размеров, для больших файлов использовались большие блоки, для маленьких маленькие.
Каталоговые записи ни как не отсортированы и следуют друг за другом.
Каталог BSD с тремя каталоговыми записями для трех файлов и тот же каталог после удаления файла zip, увеличивается длина первой записи.
3.3 Файловые системы LINUX
Изначально использовалась файловая система MINIX с ограничениями: 14 символов для имени файла и размер файла 64 Мбайта.
После была создана файловая система EXT с расширением: 255 символов для имени файла и размер файла 2Гбайта.
Система была достаточно медленной.
3.3.1 Файловая система EXT2
Эта файловая система стала основой для LINUX, она очень похожа BSD систему.
Вместо групп цилиндров используются группы блоков.
Размещение файловой системы EXT2 на диске
Размер блока 1 Кбайт
Размер каждого i-узла 128 байт.
i-узел содержит 12 прямых и 3 косвенных адресов, длина адреса в i-узле стала 4 байта, что обеспечивает поддержку размера файла чуть более 16Гбайт.
Особенности работы файловой системы:
Создание новых каталогов распределяется равномерно по группам блоков, чтобы в каждой группе было одинаковое количество каталогов.
Новые файлы старается создавать в группе, где и находится каталог.
При увеличении файла система старается новые блоки записывать ближе к старым.
Благодаря этому файловую систему не нужно дефрагментировать, она не способствует фрагментации файлов (в отличии от NTFS), что проверено многолетним использованием.
3.3.2 Файловая система EXT3
В отличие от EXT2, EXT3 является журналируемой файловой системой, т.е. не попадет в противоречивое состояние после сбоев. Но она полностью совместима с EXT2.
Разработанная в Red Hat
В данный момент является основной для LINUX.
Драйвер Ext3 хранит полные точные копии модифицируемых блоков (1КБ, 2КБ или 4КБ) в памяти до завершения операции. Это может показаться расточительным. Полные блоки содержат не только изменившиеся данные, но и не модифицированные.
Такой подход называется "физическим журналированием", что отражает использование "физических блоков" как основную единицу ведения журнала. Подход, когда хранятся только изменяемые байты, а не целые блоки, называется "логическим журналированием" (используется XFS). Поскольку ext3 использует "физическое журналирование", журнал в ext3 имеет размер больший, чем в XFS. За счет использования в ext3 полных блоков, как драйвером, так и подсистемой журналирования нет сложностей, которые возникают при "логическом журналировании".
Типы журналирования поддерживаемые Ext3, которые могут быть активированы из файла /etc/fstab:
data=journal (full data journaling mode) - все новые данные сначала пишутся в журнал и только после этого переносятся на свое постоянное место. В случае аварийного отказа журнал можно повторно перечитать, приведя данные и метаданные в непротиворечивое состояние.
Самый медленный, но самый надежный.
data=ordered - записываются изменения только мета-данных файловой системы, но логически metadata и data блоки группируются в единый модуль, называемый transaction. Перед записью новых метаданных на диск, связанные data блоки записываются первыми. Этот режим журналирования ext3 установлен по умолчанию.
При добавлении данных в конец файла режим data=ordered гарантированно обеспечивает целостность (как при full data journaling mode). Однако если данные в файл пишутся поверх существующих, то есть вероятность перемешивания "оригинальных" блоков с модифицированными. Это результат того, что data=ordered не отслеживает записи, при которых новый блок ложится поверх существующего и не вызывает модификации метаданных.
data=writeback (metadata only) - записываются только изменения мета-данных файловой системы. Самый быстрый метод журналирования. С подобным видом журналирования вы имеете дело в файловых системах XFS, JFS и ReiserFS.
3.3.3 Файловая система XFS
XFS - журналируемая файловая система разработанная Silicon Graphics, но сейчас выпущенная открытым кодом (open source).
XFS была создана в начале 90ых (1992-1993) фирмой Silicon Grapgics (сейчас SGI) для мультимедийных компьютеров с ОС Irix. Файловая система была ориентирована на очень большие файлы и файловые системы. Особенностью этой файловой системы является устройство журнала - в журнал пишется часть метаданных самой файловой системы таким образом, что весь процесс восстановления сводится к копированию этих данных из журнала в файловую систему. Размер журнала задается при создании системы, он должен быть не меньше 32 мегабайт; а больше и не надо - такое количество незакрытых транзакций тяжело получить.
Более эффективно работает с большими файлами.
Имеет возможность выноса журнала на другой диск, для повышения производительности.
Сохраняет данные кэша только при переполнении памяти, а не периодически как остальные.
В журнал записываются только мета-данные.
Используются B+ trees.
Используется логическое журналирование
3.3.4 Файловая система RFS
RFS (RaiserFS) - журналируемая файловая система разработанная Namesys.
Официальная информация на RaiserFS
Более эффективно работает с большим количеством мелких файлов, в плане производительности и эффективности использования дискового пространства.
Использует специально оптимизированные b* balanced tree (усовершенствованная версия B+ дерева)
Динамически ассигнует i-узлы вместо их статического набора, образующегося при создании "традиционной" файловой системы.
Динамические размеры блоков.
3.3.4 Файловая система JFS
JFS (Journaled File System) - журналируемая файловая система разработанная IBM для ОС AIX, но сейчас выпущенная как открытый код.
Журналы JFS соответствуют классической модели транзакций, принятой в базах данных
В журнал записываются только мета-данные
Размер журнала не больше 32 мегабайт.
Асинхронный режим записи в журнал - производится в моменты уменьшения трафика ввода/вывода

Файловая система обеспечивает работу пользователей и программ с файлами (чтение и запись информации на диске), а так же ведет учет свободных и занятых кластеров на диске.
Файловая система осуществляет работу с данными на диске, основываясь на адресах секторов.
Работа с программами основывается на именах файлов.
Цели, состав и функции
Цели использования файловой системы:
- Экранирование физической организации долговременного хранилища данных.
- Создание простой модели (логической) этого хранилища.
- Предоставление программам и пользователям удобного набора команд для манипулирования файлами.
Состав файловой системы определяется следующими компонентами:
- Все файлы на диске.
- Наборы структур данных, которые используются для управления файлами.
- Комплекс системных программных средств которые реализуют различные операции над файлами (создание, запись, чтение, поиск и другие).
Функции файловой системы:
- Отображение логической модели данных на физическую организацию хранилища данных. То есть структура файлов и папок на компьютере переноситься на физический жесткий диск. А именно на конкретные сектора.
- Обеспечение устойчивости файловой системы к сбоям и ошибкам.
- Предоставление программного интерфейса для приложений. Что бы программы могли работать с файлами.
- Обеспечение совместного доступа к файлу несколькими процессами. О процессах я рассказывал в основах операционных систем.
- Защита файлов от несанкционированного доступа.
Какие бывают файловые системы
Для Windows используются два файловые системы:
- FAT (File Allocation Table).
- NTFS (New Technology File System).
Для UNIX систем это:
- UFS (Unix File System).
- S5 (применительно к System V).
Физическая организация файловых систем
Обычные HDD диски состоят из:
- Дорожек. Концентрических колец предназначенных для хранения данных, размеченных на диске. Они состоят из одинакового числа секторов.
- Секторов. Сектор является наименьшей адресуемой единицей дискового устройства для обмена данными. Размер сектора фиксирован.
- При низкоуровневом форматировании создаются дорожки и сектора, на диск записывается информация для определения границ секторов.

Логические диски
При работе в операционной системы мы работаем с логическими дисками или разделами. Физический диск может быть разбит на один или несколько логических дисков.
Логический диск или раздел это часть (или весь) физического диска, которую операционная система представляет пользователю как логическое устройство.
На одном логическом диске может использоваться только одна файловая система.
На моем примере.

В моем случае диск C это часть физического SSD диска. Диски D и E — полностью два физических диска. Часто один физический диск разбивают на два логически C и D.
Возможные варианты организации логических дисков:
- Один физический – один логический.
- Один физический – несколько логических.
- Несколько физических – один логический.
Вариант несколько физических = дин логический обычно используется в RAID массивах.
На картинке выше видно что один диск (диск C) помечен как загружаемый (системный) иконкой слева.
Высокоуровневое форматирование диска
Высокоуровневое форматирование диска необходимо для создания логического диска и файловой системы на нем.
При форматировании пространство логического диска разбивается на кластеры определенного размера.
Кластер (блок) является минимальной единицей хранения данных, используемой в файловой системе.
При форматировании на диск записывается следующая информация:
- Загрузчик операционной системы.
- Сведения о границах областей отведенных под файлы и каталоги.
- Информация о поврежденных областях.
- Информация о доступном и неиспользуемом пространстве.
Служебная область содержит общую информацию о файловой системе, свободных кластерах, о размещении файлов в кластерах.
Главная таблица файлов – MFT содержит как минимум одну запись для каждого файла и запись для себя. На кластеры делится весь раздел диска, а не только область данных.
В файловой системе NTFS данные организуются следующим образом.

Организация данных в NTFS
Возникает вопрос, а что же такое файл?
Файл это неструктурированная последовательность байтов, в которую можно записывать и из которой можно считывать информацию. Файл это логический объект, позволяющий обращаться к информации по имени.
За счет использования файлов в операционной системе появилась возможность простого доступа пользователей и приложений к информации по имени.
Наличие имени файла позволяет получать доступ к информации независимо от адресов кластеров, в которых располагается файл. Существует возможность определения прав доступа пользователей к файлу.
Типы файлов
Обычные файлы — это файлы которые содержат информацию произвольного характера. Они имеют произвольную структуру. Операционная система должна распознавать как минимум один тип файлов, это собственные исполняемые файлы.
Специальные файлы – фиктивные файлы, которые ассоциируются с устройствами ввода-вывода.
Каталоги – файлы, которые содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо признаку. Каталоги могут содержать файлы любых типов, включая каталоги.
Другие — тип файлов, содержащий символьные связи, именованные конвейеры, отображаемые в памяти.
Иерархическая структура файловой системы состоит из следующих элементов:
- Дерево – файл может входить только в один каталог.
- Сеть – файл может входить в несколько каталогов.
Корневым называют каталог верхнего уровня.

Иерархическая структура файловой системы
Монтирование логических дисков
Монтированием логических дисков называют встраивание логического диска в иерархическую структуру файлов операционной системы.
В качестве точки монтирования может выступать любой пустой каталог существующей файловой системы. При монтировании он становится корневым для файловой системы монтируемого диска.
Возможности файловой системы
Учет свободных кластеров
Использование связного списка номеров свободных кластеров. В каждом кластере, входящем в список, помещаются номера свободных кластеров и ссылка на следующий кластер из списка. При этом в оперативной памяти достаточно хранить один кластер из списка.
Использование битового массива. Свободные кластеры помечаются 1, а занятые 0 (или наоборот). В оперативной памяти достаточно хранить один кластер битового массива. Выделяемые файлу свободные кластеры располагаются близко друг к другу, что приводит к увеличению быстродействия.
Дисковые квоты
Дисковая квота – максимальное количество файлов и блоков (кластеров), назначаемое пользователю для хранения данных.
Гибкий лимит – при превышении гибкого лимита во время регистрации пользователю выдается предупреждение, и счетчик предупреждений уменьшается на 1. Если счетчик равен 0, то в регистрации отказывается.
Жесткий лимит – лимит который не может быть превышен.
Резервное копирование
Резервное копирование это процесс создания на носителе, предназначенном для восстановления данных в оригинальном месте их расположения в случае их повреждения или разрушения.
Существуют следующие способы повышения эффективности и удобства резервного копирования:
- Сохранение не всей файловой системы, а только некоторых каталогов.
- Инкрементное резервное копирование: сохраняются только файлы, изменявшиеся после последнего резервного копирования.
- Хранение резервных копий на других носителях, а так же в удаленном месте.
- Сжатие резервируемых данных.
- Быстрое фиксирование состояния файловой системы путем копирования критических структур данных для решения проблемы изменения данных во время резервного копирования.
- Возможность восстановления в исходное место размещения, в другое место с сохранением структуры каталогов и без сохранения структуры.
Физическое резервное копирование это последовательное копирование всех кластеров диска.
Логическое резервное копирование это проверка каталогов и сохранение содержащихся в них информации.
Преимущества физического копирования:
- простота реализации;
- высокая скорость.
- резервирование свободных кластеров;
- невозможность восстановления отдельных файлов;
- невозможность инкрементного резервного копирования.
Логическое резервирование происходит следующим образом:
- Резервируются файлы, которые были изменены. Резервируются каталоги, содержащиеся в пути к этому файлу.
- Создается битовый массив, индексированный по номеру индексного дескриптора.
- Рекурсивно исследуется каталоги, пометки снимаются с каталогов, в которых нет модифицированных файлов и каталогов.
- Резервируются все помеченные каталоги, перед каталогом записывается его атрибуты.
- Резервируются все помеченные файлы, перед файлом записываются его атрибуты.
- Исследуются все элементы начального каталога и помечаются модифицированные файлы и все каталоги, в которых рекурсивно ищутся все модифицированные файлы.
Далее создается резервная копия.
Восстановление файловой системы из резервной копии происходит следующим образом:
- Создается пустая файловая система.
- Восстанавливаются данные последней полной архивации, сначала каталоги, а затем файлы.
- Восстанавливаются данные из инкрементных резервных копий.
- Восстанавливается список свободных кластеров.
Теперь вы знаете основы файловых систем.

Обучаю HTML, CSS, PHP. Создаю и продвигаю сайты, скрипты и программы. Занимаюсь информационной безопасностью. Рассмотрю различные виды сотрудничества.
Фа́йловая систе́ма (англ. file system ) — порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронном оборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяет формат содержимого и способ физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имен файлов и (каталогов), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
Общие понятия
Назначение файловой системы - обеспечение интерфейса к данным на накопителях. Цель - организация хранения и доступа.
Состав файловой системы
- Совокупность файлов.
- Набор структур данных управления (каталоги, дескрипторы, таблицы).
- Функции управления (создание объекта ФС, уничтожение, чтение, запись).
Каждый файл характеризуется своим уникальным именем. Чтобы упростить имена используются разрешения.
Для FAT16 правило 8.3: имя файла может состоять из 12 символов (8 - основная часть, и 3 символа расширения).
При копировании в файловой системе файлов производится преобразование имен.
Путь в файловой системе - для однозначной идентификации объекта.
Типы файлов
- Текстовые.
- Двоичные.
- Специальные (связанные с аппаратными устройствами).
- Файлы, через которые описываются каталоги (директор).
Атрибуты файлов
- Системные.
- Архивные.
- Только для чтения.
- Скрытые.
- Время создания
- Временные
Типы иерархической структуры
- Дерево: узлы - объекты файловой системы, показана их вложенность; корень - точка, в которой начинается файловая система.
- Сеть: в отличие от дерева один объект может присутствовать в разных директориях.
С понятием файловые системы связаны следующие технологии:
- Принципы организации файловых систем
- Организация прав доступа в файловых системах
- Общая модель файловой системы
- Файлы, отображаемые в оперативную память
- Поддержка нескольких файловых систем
- Журнальные файловые системы
Принципы организации файловых систем
Логическая организация файла
Описывает то, как выглядит файл для работающих с ним приложений. Файл рассматривается как набор записей. Выделяют следующие подходы к хранению файлов:
Набор записей постоянной длины
Последовательное хранение логических записей фиксированного размера.
Набор записей переменной длины
Для любой записи тут в начале (конце) должна указываться длина.
Физическая организация файла
Описывает, как файл может размещаться на носителе. Выделяют следующие способы размещения:
Непрерывное размещение
Непрерывное размещение (подряд блок за блоком).
Достоинства:
- простота реализации
- скорость доступа (все данные подряд, поэтому не надо перемещать носитель головки).
- фрагментация
- место на носителе распределяется неэффективно.
Связанный список блоков
Пространство разбивается на нужные разделы. В каждый блок помещается ссылка на следующий. В последнем блоке стоит метка, что он последний. Уходим от фрагментации, но теряем в производительности. Также в каждом блоке часть места расходуется на указатели.
Связанный список индексов
Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является использование связанного списка индексов. С каждым блоком связывается некоторый элемент - индекс. Индексы располагаются в отдельной области диска (в MS-DOS это таблица FAT). Если некоторый блок распределен некоторому файлу, то индекс этого блока содержит номер следующего блока данного файла. При такой физической организации сохраняются все достоинства предыдущего способа, но снимаются оба отмеченных недостатка: во-первых, для доступа к произвольному месту файла достаточно прочитать только блок индексов, отсчитать нужное количество блоков файла по цепочке и определить номер нужного блока, и, во-вторых, данные файла занимают блок целиком, а значит имеют объем, равный степени двойки.
Перечень номеров блоков
Для хранения адреса файла выделено 13 полей. Если размер файла меньше или равен 10 блокам, то номера этих блоков непосредственно перечислены в первых десяти полях адреса. Если размер файла больше 10 блоков, то следующее 11-е поле содержит адрес блока, в котором могут быть расположены еще 128 номеров следующих блоков файла. Если файл больше, чем 10+128 блоков, то используется 12-е поле, в котором находится номер блока, содержащего 128 номеров блоков, которые содержат по 128 номеров блоков данного файла. И, наконец, если файл больше 10+128+128*128, то используется последнее 13-е поле для тройной косвенной адресации, что позволяет задать адрес файла, имеющего размер максимум 10+ 128 + 128*128 + 128*128*128.
Общая организация файловой системы
ОС WINDOWS
В ОС Windows наиболее распространенной на сегодняшний день является файловая система NTFS, заменившая устаревшую файловую систему FAT. Именно файловую систему NTFS лучше всего использовать на сегодняшний день. Чтобы жесткий диск можно было использовать в компьютере, его необходимо подготовить, отформатировать в выбранную файловую систему. Программа форматирования создает на жестком диске компьютера структуру в соответствии с правилами файловой системы Windows после чего диск становится виден в операционной системе и его можно использовать. Форматирование жесткого диска осуществляется силами операционной системы или сторонней программы. При этом выбирается тип файловой системы жесткого диска, размер кластера и способ форматирования.
Кластер — упрощенно, минимальная ячейка на жестком диске для хранения информации, эдакая коробочка для хранения файлов. Кластер имеет вполне конкретные стандартизованные размеры равные 512 байт раньше и 4 096 байт в настоящее время. В одном кластере хранится только один файл, если он меньше размера кластера, то все равно занимает весь кластер. Когда файл не помещается целиком в одном кластере, то он записывается кусочками по разным кластерам, необязательно соседним. Поскольку размеры файлов крайне редко кратны размеру кластера, то на диске файлы практически всегда занимают больше места, чем их реальный размер. Чтобы было понятнее, возьмем для наглядности такой пример. Есть 9 кирпичей, из них 3 белых и 6 красных, а в контейнер помещается только 5 кирпичей одного типа. Чтобы хранить наши кирпичи нам понадобится 3 контейнера, хотя емкость двух контейнеров 10 кирпичей. Вот наглядная иллюстрация, как это происходит.
В файловой системе компьютера происходит точно также. В этом легко убедиться, если кликнуть правой кнопкой мыши по файлу и выбрать свойства.
Файл размером 6 байт занимает в файловой системе жесткого диска 4 096 байт, т.е. один кластер. Соответственно маленький размер кластера больше подходит для хранения маленьких файлов, а большой размер кластера для хранения больших. Тогда место на диске будет использоваться более рационально. Так же происходит и с ярлыками.
Структура файловой системы Windows
Первоначально, вся информация в виде файлов записывалась в файловую систему Windows в одну кучу, однако с ростом количества информации и емкости дисков это стало очень неудобно. Попробуйте найти нужную вам вещь в коробке, среди десятков других. Выходом из этой ситуации стало создание древовидной структуры папок (директорий или каталогов) сильно облегчающих структурирование и поиск информации. Внутри каталога создаются подкаталоги, и файлы группируются по логическому принципу удобному пользователю.
Дальнейший рост емкости дисков привел к следующему очевидному шагу, разбить один физический носитель информации на несколько логических разделов (дисков). Логически выделенная часть смежных блоков на диске называется раздел (partition). Такая структура файловой системы применяется в настоящее время в операционной системе Windows.
Это позволяет упростить структурирование информации, повысить надежность хранения данных за счет разделения системных и пользовательских файлов, более гибко управлять правами доступа к файлам, увеличить скорость дисковых операций. Каждый созданный логический диск воспринимается операционной системой, как независимый, хотя фактически он виртуален. Благодаря этому каждому разделу жесткого диска можно назначить произвольную файловую систему или настроить размер кластера, а так же иметь несколько операционных систем на одном компьютере.
Первый физический сектор жесткого диска отведен для хранения главной загрузочной записи (MBR), необходимой для начальной загрузки операционной системы, а так же хранит таблицу разделов.
Разделы бывают двух видов: первичный (основной) и дополнительный (расширенный). В первом секторе основного раздела располагается загрузочный сектор, обеспечивающий загрузку ОС с данного раздела жесткого диска. Всего на физическом диске может быть четыре раздела и только один из них расширенный. Дополнительный раздел представляет собой оболочку для любого количества других логических разделов. Это позволяет обойти ограничение, только четыре раздела на физическом диске.
Вот и все, что мы хотели рассказать о файловой системе компьютера в операционной системе Windows.
ОС UNIX
Состоит из двух компонент:
- иерархия файлов и директорий
- набор файлов устройств, логических томов или разделов.
Для файловой системы UNIX характерна операция монтирования. Монтирование – установление ассоциаций между именами файловой иерархии и устройствами. Оно происходит в два этапа:
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл . При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память , поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление данных.
Таким образом, файловая система играет роль промежуточного слоя, экранизирующего все сложности физической организации долговременного хранилища данных и создающего для программ более простую логическую модель этого хранилища, а затем предоставляет им набор удобных в использовании команд для манипулирования файлами.
Классическая схема организации программного обеспечения файловой системы представлена на рис. 7.6.
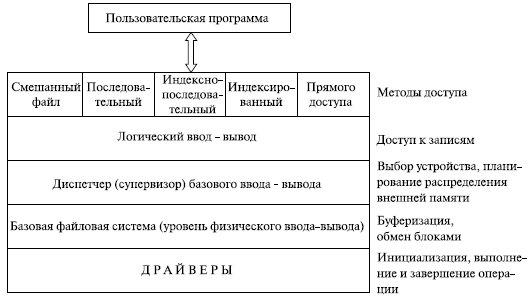
На нижнем уровне драйверы устройств непосредственно связаны с периферийными устройствами или их котроллерами либо каналами. Драйвер устройства отвечает за начальные операции ввода-вывода устройства и за обработку завершения запроса ввода-вывода. При файловых операциях контролируемыми устройствами являются дисководы и стримеры (накопители на МЛ). Драйверы устройств рассматриваются как часть операционной системы.
Следующий уровень называется базовой файловой системой, или уровнем физического ввода-вывода. Это первичный интерфейс с окружением (периферией) компьютерной системы. Он оперирует блоками данных, которыми обменивается с дисками, магнитной лентой и другими устройствами. Поэтому он связан с размещением и буферизацией блоков в оперативной памяти. На этом уровне не выполняется работа с содержимым блоков данных или структурой файлов. Базовая файловая система обычно рассматривается как часть операционной системы (в MS- DOS эти функции выполняет BIOS , не относящийся к ОС).
Диспетчер базового ввода-вывода отвечает за начало и завершение файлового ввода-вывода. На этом уровне поддерживаются управляющие структуры, связанные с устройством ввода-вывода, планированием и статусом файлов. Диспетчер осуществляет выбор устройства, на котором будет выполняться операция файлового ввода-вывода, планирование обращения к устройству (дискам, лентам), назначение буферов ввода-вывода и распределение внешней памяти. Диспетчер базового ввода-вывода является частью ОС.
Логический ввод- вывод предоставляет приложениям и пользователям доступ к записям. Он обеспечивает возможности общего назначения по вводу-выводу записей и поддерживает информацию о файлах. Наиболее близкий к пользователю уровень ФС часто называется методом доступа. Он обеспечивает стандартный интерфейс между приложениями и файловыми системами и устройствами, содержащими данные. Различные методы доступа отражают различные структуры файлов и различные пути доступа и обработки данных.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
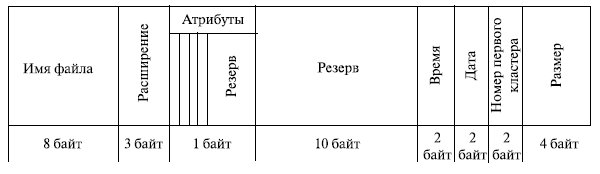
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
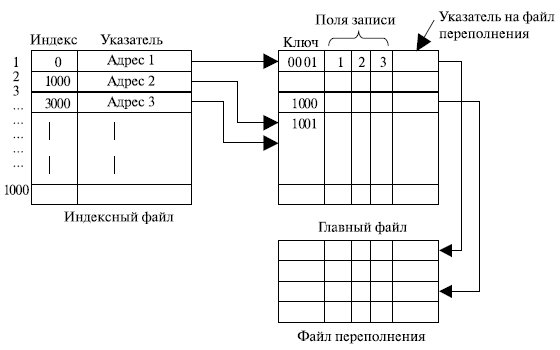
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .
Читайте также: