
Как распознать фишинговые сайты 1 по ссылке 2 по протоколу передачи данных
Обновлено: 25.04.2024
Фишинг является очень популярным методом кражи данных у пользователей Интернета, поскольку он не требует больших финансовых затрат и является универсальным инструментом — больше социальным, нежели технологическим. Благодаря этому мошенник или группа подобных лиц может быстро адаптироваться к новому способу работы. Мошенники в наше время тоже многое умеют и постоянно совершенствуют свои навыки.
Уверен, что большинство из вас слышали и сталкивались с фишингом, но во многих случаях прошли мимо, так и не поняв, что это и чем он опасен. Сегодня я постараюсь расширить ваши знания, расскажу, чем опасен фишинг, как его распознать и как защититься от него.
Что такое фишинг?
Самое простое определение фишинга заключается в том, что это метод мошенничества, при котором преступники, выдавая себя за представителей доверенных учреждений, вымогают конфиденциальные данные, чаще всего — пароли для входа в сервисы электронных банковских услуги, внутренние сети компании, а также номера платежных карт и адреса электронной почты.

Для этого злоумышленники используют вредоносное ПО или пытаются при помощи социальной инженерии заставить жертв предпринять определенные действия, которые помогут им получить желаемый результат. Атаки, направленные против обычных пользователей, относительно просты, но киберпреступники все чаще используют более сложные методи фишинга, которые требуют сбора информации о жертвах, чтобы подавить их бдительность и заставить играть по своим правилам.
Как работает фишинг?
Фишинг, с которым мы обычно имеем дело, состоит в отправке потенциальным жертвам специально созданных электронных писем или СМС. Они содержат ссылки на вредоносные веб-сайты, где интернет-пользователи должны предоставлять конфиденциальные данные, которые обычно являются логином и паролем для электронного банковского веб-сайта. Тем самым вы позволяете мошенникам воровать деньги со своих счетов. Заставить жертву сделать это — самая большая проблема, поэтому киберпреступники постоянно придумывают новые причины для осуществления своих планов. В последнее время наиболее распространенным методом фишинга являются микроплатежи.

Как видите, этот механизм очень прост, но самая большая проблема обманщика — заставить жертву предоставить данные, поэтому мы постоянно имеем дело с новыми фишинговыми кампаниями. Киберпреступники не всегда грозят неприятными последствиями. Популярным методом также является информирование в рекламных объявлениях, размещаемых на веб-сайтах и в социальных сетях, с привлекательными призами, с возможностью быстро заработать большие деньги или даже получить наследство от какого-то ныне покойного кенийского, американского или шотландского (выберите страну сами) миллиардера, который является вашим дальним родственником. В последнем случае изображения известных личностей (конечно, без их согласия) часто используются для убеждения в подлинности мошенничества.

Тем не менее, фишинг — это не только кража персональных данных обычных интернет-пользователей. Таким образом, мошенники все чаще пытаются убедить сотрудников предприятий предоставить им логин и пароль для внутренней сети компании или установить вредоносное программное обеспечение. Оно даст им открытый доступ в базу данных компании или организации и приведет к краже различной информации.
Вышеупомянутый целевой фишинг чаще всего используется для конкретных целей. Этот метод состоит в том, что преступники выбирают конкретного человека из персонала компании и фокусируют на нем свое внимание, заставляя играть на своем поле. В особой зоне риска — бухгалтеры, секретари и сотрудники имеющие доступ к базе данных. Преступники месяцами собирают информацию об этом человеке и используют ее, чтобы сделать мошенничество как можно более достоверным. Иногда мошенники даже притворяются супервайзерами или вспомогательным персоналом, заставляя пользователя установить вредоносную программу на свой ПК. Такой фишинг сложнее расшифровать, потому что он персонализированный, что, безусловно, усложняет поиск злоумышленников.
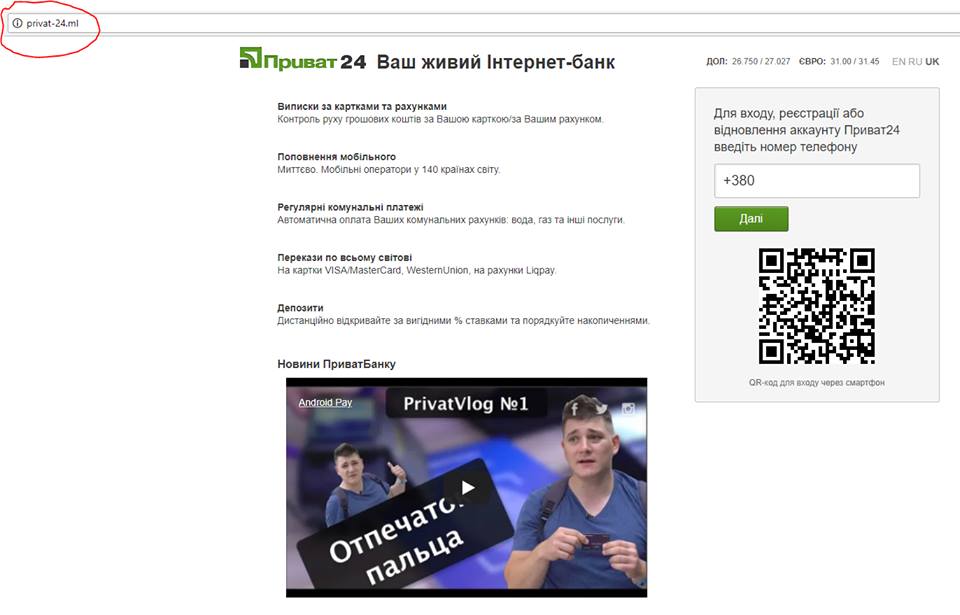
Проверьте адрес страницы, на которую ведет ссылка

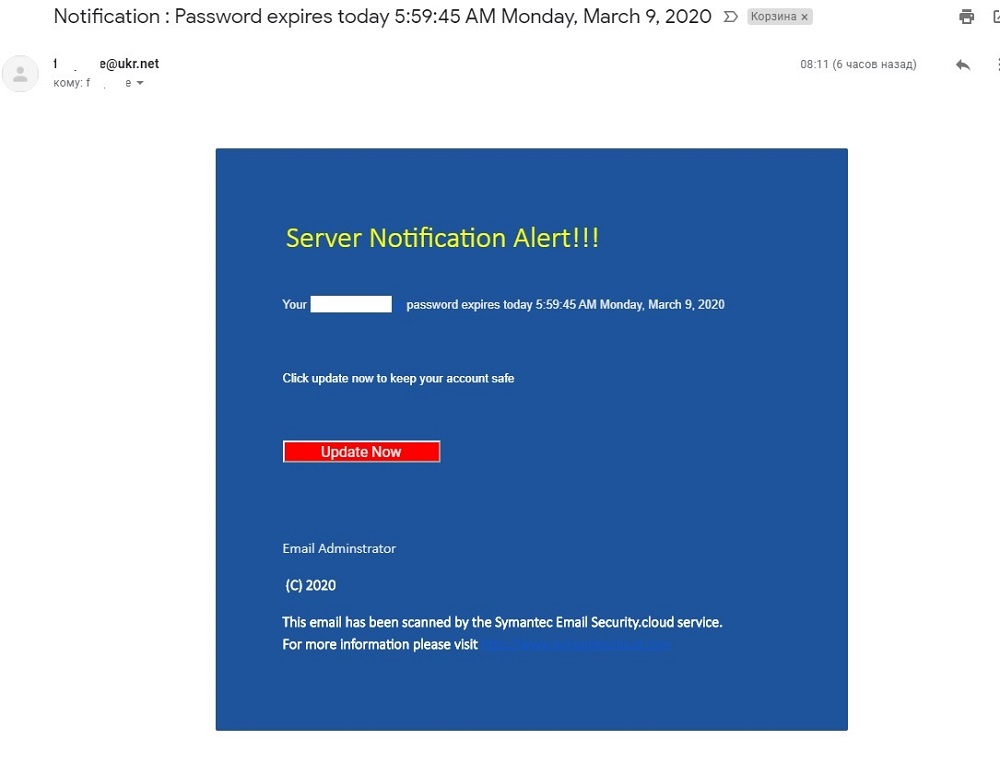
Не увлекайтесь
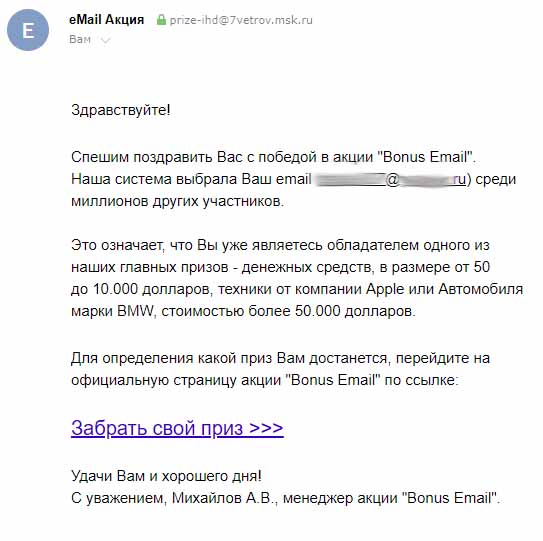
Запрос конфиденциальных данных — это всегда афера
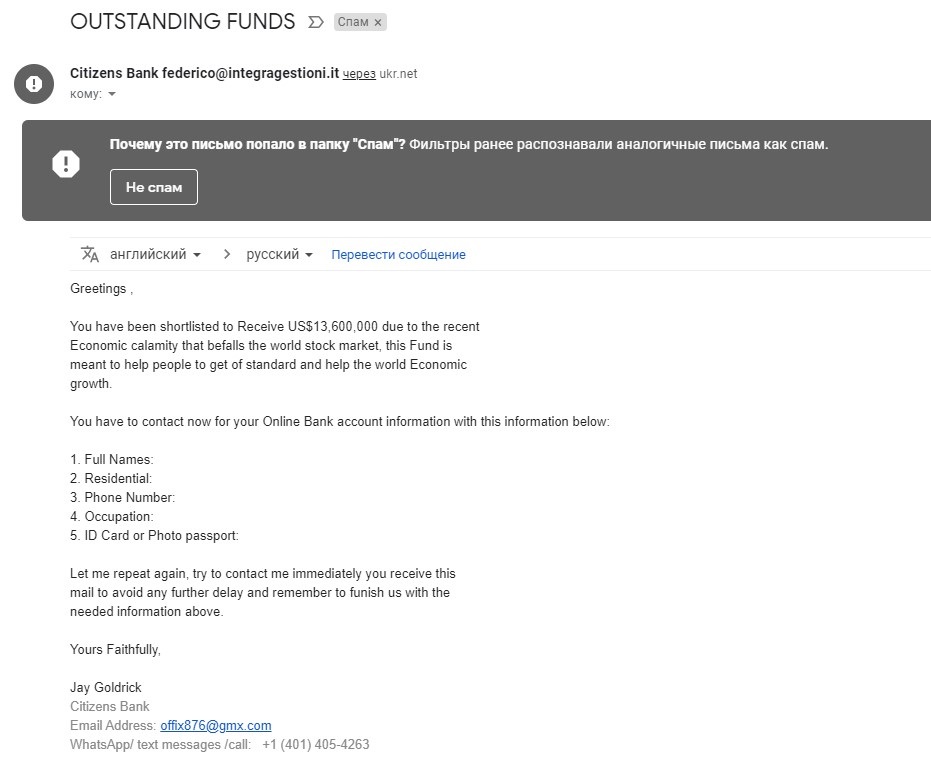
Трудности перевода

Остерегайтесь вложений
Преступники также используют вредоносные программы для захвата конфиденциальных данных или взлома компьютеров и целых сетей. Механизм действия тот же и ограничен попыткой убеждения жертвы открыть вредоносное вложение. Чаще всего они скрыты в архивах ZIP или RAR и имеют форму исполняемых файлов EXE или BAT . Однако они также могут скрыть вредоносный код в макросах документов программ Microsoft Office или Google Docs, поэтому вам следует обратить на них внимание и выполнить сканирование с помощью антивирусной программы перед запуском.
Как защитить себя от фишинга?

Также рекомендуется использовать антивирусные программы, несмотря на то, что они не смогут указать, что просматриваемая электронная почта является фишинговой, но они смогут заблокировать некоторые небезопасные сайты и вложения. Уверен, что антивирусное ПО обязательно поможет вам защитить компьютеры и персональные данные.
Также важно использовать актуальное программное обеспечение, в частности операционные системы, потому что новые уязвимости и проблемы безопасности постоянно обнаруживаются разработчиками и обезвреживаются. Помните, что только использование самых последних версий ОС гарантирует получение своевременных обновлений безопасности.
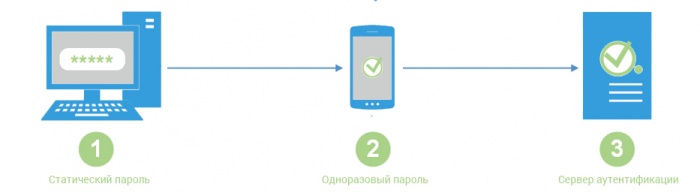
Хорошей практикой также является использование двухэтапной проверки личности пользователя в web-сервисах. Она широко используется в электронном банкинге, но доступна во все большем количестве сервисов и веб-сайтов. Двухэтапная (или двухкомпонентная) проверка состоит в вводе дополнительного кода в дополнение к традиционному паролю и логину
Код для входа может быть отправлен вам по электронной почте, в SMS или сгенерирован приложением, предоставленным поставщиком услуг. Существуют также сторонние программы, которые позволяют связывать учетные записи со многими веб-сайтами и создавать коды в одном месте, например, на вашем смартфоне.
Однако наиболее удобной формой двухэтапной проверки являются физические ключи безопасности U2F, которые устраняют необходимость переписывать пароли и коды в блокнот. Просто вставляете ключ в USB-порт компьютера, тем самым связываясь с поддерживаемыми службами для авторизации.

Фишинг представляет собой огромную угрозу, поскольку, согласно некоторым исследованиям, он является не только причиной потери денег многими пользователями, но и основной причиной утечки данных компаний. Однако, как мы показали в этой статье, в большинстве случаев намерения киберпреступников легко распознать и предотвратить их.

Фишинг - это форма мошенничества, при которой злоумышленник пытается узнать конфиденциальную информацию, такую как учетные данные для входа в систему или данные учетной записи, отправляя в качестве уважаемого лица или человека по электронной почте или другим каналам связи.

В этой статье я объясняю: характеристики домена фишинга (или мошеннического домена), функции, которые отличают их от законных доменов, почему важно обнаруживать эти домены и как их можно обнаружить с помощью методов машинного обучения и обработки естественного языка.
Многие пользователи невольно нажимают на фишинговые домены каждый день и каждый час. Злоумышленники нацелены как на пользователей, так и на компании. Согласно 3-му отчету Microsoft Computing Safer Index, опубликованному в феврале 2014 года, ежегодное влияние фишинга в мире может достигать 5 миллиардов долларов.
В чем причина этой стоимости?
Основной причиной является недостаточная осведомленность пользователей. Но защитники безопасности должны принять меры предосторожности, чтобы пользователи не могли противостоять этим вредоносным сайтам. Предотвращение этих огромных затрат может начаться с осознания людей в дополнение к созданию надежных механизмов безопасности, которые способны обнаруживать и предотвращать фишинговые домены для доступа к пользователю.
Давайте проверим структуру URL, чтобы понять, как злоумышленники думают при создании фишингового домена.
Унифицированный указатель ресурса (URL) создан для адресации веб-страниц. На рисунке ниже показаны соответствующие части в структуре типичного URL.

Некоторые компании, занимающиеся разведкой угроз, выявляют и публикуют мошеннические веб-страницы или IP-адреса в виде черных списков, поэтому другим становится проще предотвращать эти вредоносные активы. (cymon,firehoл)
Злоумышленник должен разумно выбрать доменные имена, потому что целью должно быть убедить пользователей, а затем настроить FreeURL, чтобы затруднить обнаружение. Давайте проанализируем пример, приведенный ниже.

Другими методами, которые часто используются злоумышленниками, являются киберсквоттинг и опечатывание.
Типосквоттинг, также называемый перехватом URL-адресов, является формой киберсквоттинга, которая основывается на ошибках, таких как опечатки, допущенные пользователями Интернета при вводе адреса веб-сайта в веб-браузер, или на основе типографских ошибок, которые трудно заметить при быстром чтении. URL, созданные с помощью Typosquatting, выглядит как доверенный домен. Пользователь может случайно ввести неправильный адрес веб-сайта или щелкнуть ссылку, которая выглядит как доверенный домен, и таким образом он может посетить альтернативный веб-сайт, принадлежащий фишеру.
Существует множество алгоритмов и большое разнообразие типов данных для обнаружения фишинга в научной литературе и коммерческих продуктах. Фишинговый URL и соответствующая страница имеют несколько функций, которые можно отличить от вредоносного URL. Например; злоумышленник может зарегистрировать длинный и запутанный домен, чтобы скрыть фактическое имя домена(Киберсквоттинг, Typosquatting). В некоторых случаях злоумышленники могут использовать прямые IP-адреса вместо использования имени домена. Событие такого типа выходит за рамки нашей компетенции, но его можно использовать для той же цели. Злоумышленники также могут использовать короткие доменные имена, которые не имеют отношения к законным названиям брендов и не имеют каких-либо дополнений FreeUrl. Но веб-сайты такого типа также не входят в сферу нашей деятельности, поскольку они более актуальны для мошеннических доменов, чем для фишинговых доменов.
Помимо функций на основе URL, используются различные виды функций, которые используются в алгоритмах машинного обучения в процессе обнаружения академических исследований. Функции, собранные в результате академических исследований для обнаружения области фишинга с помощью методов машинного обучения, сгруппированы, как указано ниже
- Функции на основе URL
- Доменные функции
- Функции на основе страниц
- Контент-ориентированные функции
Функции на основе URL
URL - это первое, что нужно проанализировать на сайте, чтобы решить, является ли он фишинговым или нет. Как мы упоминали ранее, URL фишинговых доменов имеют некоторые отличительные особенности. Функции, связанные с этими точками, получаются при обработке URL. Некоторые из возможностей на основе URL приведены ниже.
Доменные функции
Целью обнаружения доменов фишинга является обнаружение доменных имен фишинга. Поэтому пассивные запросы, связанные с доменным именем, которые мы хотим классифицировать как фишинговые или нет, предоставляют нам полезную информацию. Некоторые полезные доменные функции приведены ниже.
- Его доменное имя или его IP-адрес в черных списках известных сервисов репутации?
- Сколько дней прошло с момента регистрации домена?
- Имя регистранта скрыто?
Функции на основе страниц
Функции на основе страниц используют информацию о страницах, которые рассчитываются службами рейтинга репутации. Некоторые из этих функций дают информацию о том, насколько надежен веб-сайт. Некоторые из основанных на странице функций приведены ниже.
- Глобальный Pagerank
- Страна Pagerank
- Позиция на сайте Alexa Top 1 Million
Некоторые функции на основе страниц дают нам информацию об активности пользователей на целевом сайте. Некоторые из этих функций приведены ниже. Получить эти типы функций не так просто. Есть несколько платных услуг для получения этих типов функций.
Контент-ориентированные функции
Для получения этих типов функций требуется активное сканирование целевого домена. Содержание страницы обрабатывается, чтобы мы могли определить, используется ли целевой домен для фишинга или нет. Некоторая обработанная информация о страницах приведена ниже.
- Заголовки страниц
- Мета-теги
- Скрытый текст
- Текст в теле
- Изображения и т. Д.
Анализируя эту информацию, мы можем собрать такую информацию, как;
- Требуется ли вход на сайт?
- Категория сайта
- Информация о профиле аудитории и др.
Обнаружение фишинговых доменов является проблемой классификации, поэтому это означает, что нам нужны помеченные данные, которые имеют образцы в качестве фишинговых доменов и законных доменов на этапе обучения. Набор данных, который будет использоваться на этапе обучения, является очень важным моментом для создания успешного механизма обнаружения. Мы должны использовать образцы, классы которых точно известны. Таким образом, это означает, что образцы, которые помечены как фишинг, должны быть абсолютно обнаружены как фишинг. Точно так же образцы, которые помечены как законные, должны быть абсолютно обнаружены как законные. В противном случае система не будет работать правильно, если мы будем использовать образцы, в которых мы не уверены.
Для этого некоторые публичные наборы данных созданы для фишинга. Некоторые из известныхPhishTank, Эти источники данных широко используются в научных исследованиях.
Сбор законных доменов является еще одной проблемой. Для этой цели обычно используются службы репутации сайта. Эти сервисы анализируют и ранжируют доступные сайты. Этот рейтинг может быть глобальным или страновым. Механизм ранжирования зависит от самых разных особенностей. Сайты с высоким рейтингом являются законными сайтами, которые используются очень часто. Одним из известных сервисов рейтинга репутации являетсяAlexa, Исследователи используют топ-листы Alexa для законных сайтов.
Когда у нас есть необработанные данные для фишинговых и законных сайтов, следующим шагом должна стать обработка этих данных и извлечение из них значимой информации для обнаружения мошеннических доменов. Набор данных, который будет использоваться для машинного обучения, должен состоять из этих функций. Таким образом, мы должны обработать необработанные данные, которые собираются из Alexa, Phishtank или других источников данных, и создать новый набор данных для обучения нашей системы с помощью алгоритмов машинного обучения. Значения характеристик должны быть выбраны в соответствии с нашими потребностями и целями и должны быть рассчитаны для каждого из них.
Там так много алгоритмов машинного обучения, и каждый алгоритм имеет свой рабочий механизм. В этой статье мы объяснилиАлгоритм дерева решенийпотому что я думаю, что этот алгоритм является простым и мощным.
Первоначально, как мы упоминали выше, фишинг-домен является одной из проблем классификации. Таким образом, это означает, что нам нужны помеченные экземпляры для создания механизма обнаружения. В этой задаче у нас есть два класса:(1)фишинг и(2)законны.
Когда мы рассчитываем функции, которые выбрали для наших нужд и целей, наш набор данных выглядит так, как показано на рисунке ниже. В наших примерах мы выбрали 12 объектов и рассчитали их. Таким образом, мы сгенерировали набор данных, который будет использоваться на этапе обучения алгоритма машинного обучения.

Генерация дерева является основной структурой механизма обнаружения. Желтые и эллиптические формы представляют особенности, и они называются узлами. Зеленые и угловые представляют классы, и они называются листьями.длинапроверяется, когда приходит пример, а затем другие функции проверяются в соответствии с результатом. Когда путешествие образцов завершено, станет понятным класс, к которому принадлежит образец.

Теперь самый важный вопрос о деревьях решений еще не дан. Вопрос в том, чтокакая особенность будет расположена как рут?а такжекакие должны идти после рута?Выбор функций интеллектуально влияет на эффективность и вероятность успеха алгоритмов напрямую.
Итак, как алгоритм дерева решений выбирает функции?
В дереве решений используется показатель получения информации, который показывает, насколько хорошо данная функция разделяет обучающие примеры в соответствии с их целевой классификацией. Название методаПолучение информации, Метод математического уравнения получения информации приведен ниже.

Высокий коэффициент усиления означает, что функция имеет высокую способность распознавания. Из-за этого функция, которая имеет максимальную оценку усиления, выбирается в качестве корневой.Энтропияявляется статистической мерой из теории информации, которая характеризует (не) чистоту произвольного набора S примеров. Математическое уравнение энтропии приведено ниже.

Исходная энтропия является постоянным значением, относительная энтропия является изменяемой. Низкий показатель относительной энтропии означает высокую чистоту, а также высокий показатель относительной энтропии означает низкую чистоту Когда мы движемся вниз по дереву, мы хотим повысить чистоту, потому что высокая чистота на листе подразумевает высокий уровень успеха.

Алгоритм дерева решений рассчитывает эту информацию для каждого объекта и выбирает объекты с максимальным показателем усиления. Чтобы вырастить дерево, листья изменяются как узел, представляющий особенность. По мере того как дерево растет вниз, все листья будут иметь высокую чистоту. Когда дерево достаточно большое, процесс обучения завершен.
Дерево, созданное путем выбора наиболее отличительных элементов, представляет структуру модели для нашего механизма обнаружения. Создание механизма с высоким уровнем успеха зависит от набора обучающих данных. Для обобщения успеха системы обучающий набор должен состоять из самых разных выборок, взятых из самых разных источников данных. В противном случае наша система может работать с высокой частотой успеха на нашем наборе данных, но она не может успешно работать на реальных данных.
Читайте также: